- The paper proposes CmIVTP, a framework that fuses macroscopic AIS and microscopic CCTV data to deliver robust and uncertainty-sensitive vessel trajectory predictions.
- It employs a unique cross-modal interaction transformer and uncertainty-aware variational decoder, achieving significantly lower ADE and FDE compared to baseline methods.
- The framework addresses signal sparsity and environmental challenges by integrating historical motion priors and dynamic scene analysis to enhance maritime safety and autonomous navigation.
Cross-modal Vessel Trajectory Prediction with CmIVTP
Problem Formulation and Context
The paper "CmIVTP: Cross-modal Interaction-based Vessel Trajectory Prediction for Maritime Intelligence" (2605.26524) focuses on advancing maritime intelligent transportation systems (MITS) through robust vessel trajectory prediction using cross-modal data fusion. Vessel movements are traditionally monitored via AIS—a cooperative radio-based system prone to sparsity, outages, and low fidelity—and CCTV, a non-cooperative sensor that offers rich environmental context but limited dynamic information. In complex waterways, especially those with uncooperative or non-broadcasting vessels, single-modal approaches are fundamentally restricted. The CmIVTP framework is introduced to address these limitations, synergistically integrating macroscopic AIS and microscopic CCTV modalities to achieve resilient, context-aware, and uncertainty-sensitive trajectory forecasting.
Figure 1: Maritime-MmD+ covers four risky areas, including bridge approaches and curved waterways, critical for navigational safety.
Framework Architecture
Visual Scene Target-aware Encoder (VSTaE)
The VSTaE module is designed to extract spatial and temporal features from CCTV sequences, modeling environmental constraints and vessel-object interactions. It includes target-specific embeddings via RoI Align, global scene context from a ResNet backbone, and bounding box encodings. Temporal evolution is captured with ConvLSTM and dynamically weighted to emphasize recent, potentially maneuver-critical events. Fused representations are passed to downstream modules for trajectory prediction.
Rather than naive feature concatenation, the CMIT incorporates asymmetric self-attention and cross-attention mechanisms to align and fuse AIS-derived motion features, CCTV-based environmental features, and scene representations, enabling intra- and inter-modal interaction modeling. This hierarchical fusion ensures the physical consistency and environmental feasibility of predicted trajectories through contextual memory injection from environmental modalities.
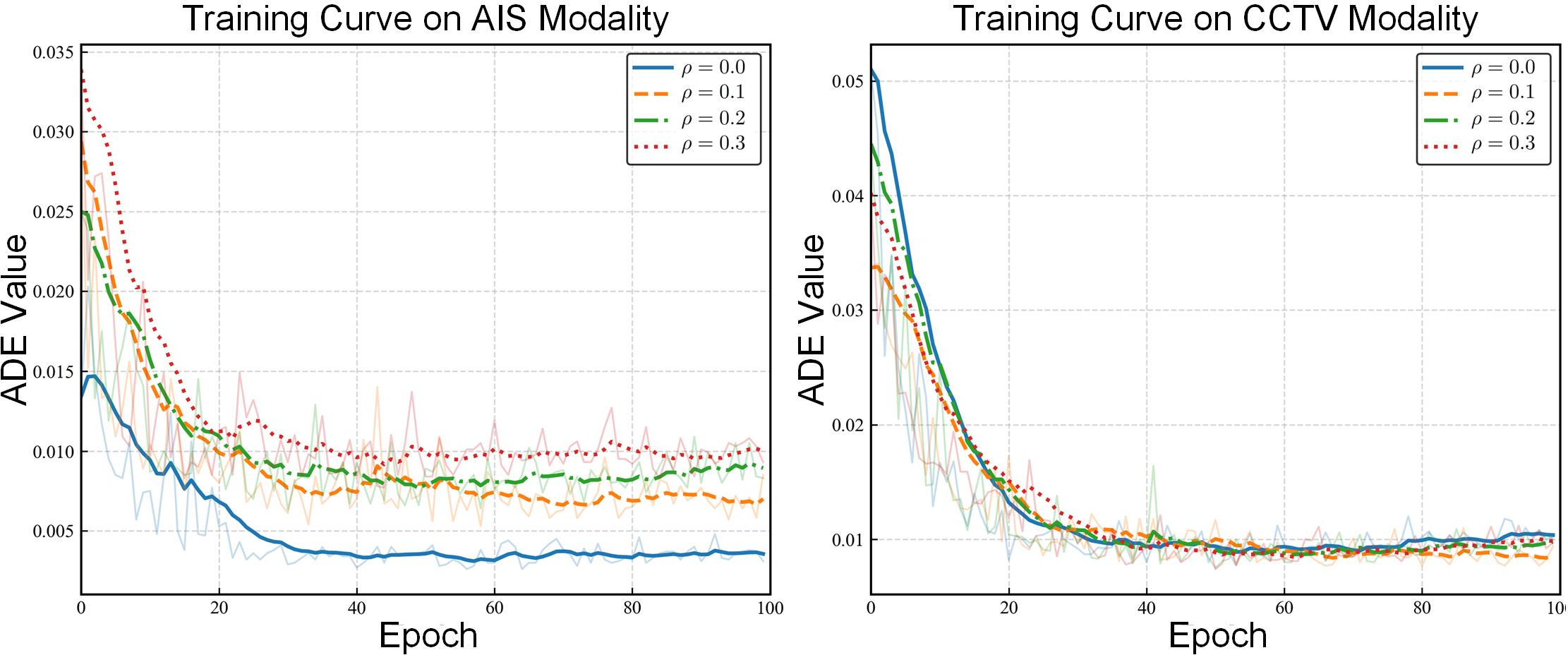
Figure 2: CmIVTP achieves robust convergence in trajectory prediction under increasing AIS data loss, with CCTV features compensating for missing kinematic signals.
Uncertainty-aware Variational Decoder (UaVD)
The UaVD module utilizes CVAE-inspired latent conditioning to capture maneuver uncertainty and support multi-modal trajectory outputs. By sampling latent variables, the model generates diverse, physically plausible future trajectory modes, reflecting both stochasticity and environmental constraints. Predictions are produced via an efficient MLP-based sequence decoder.
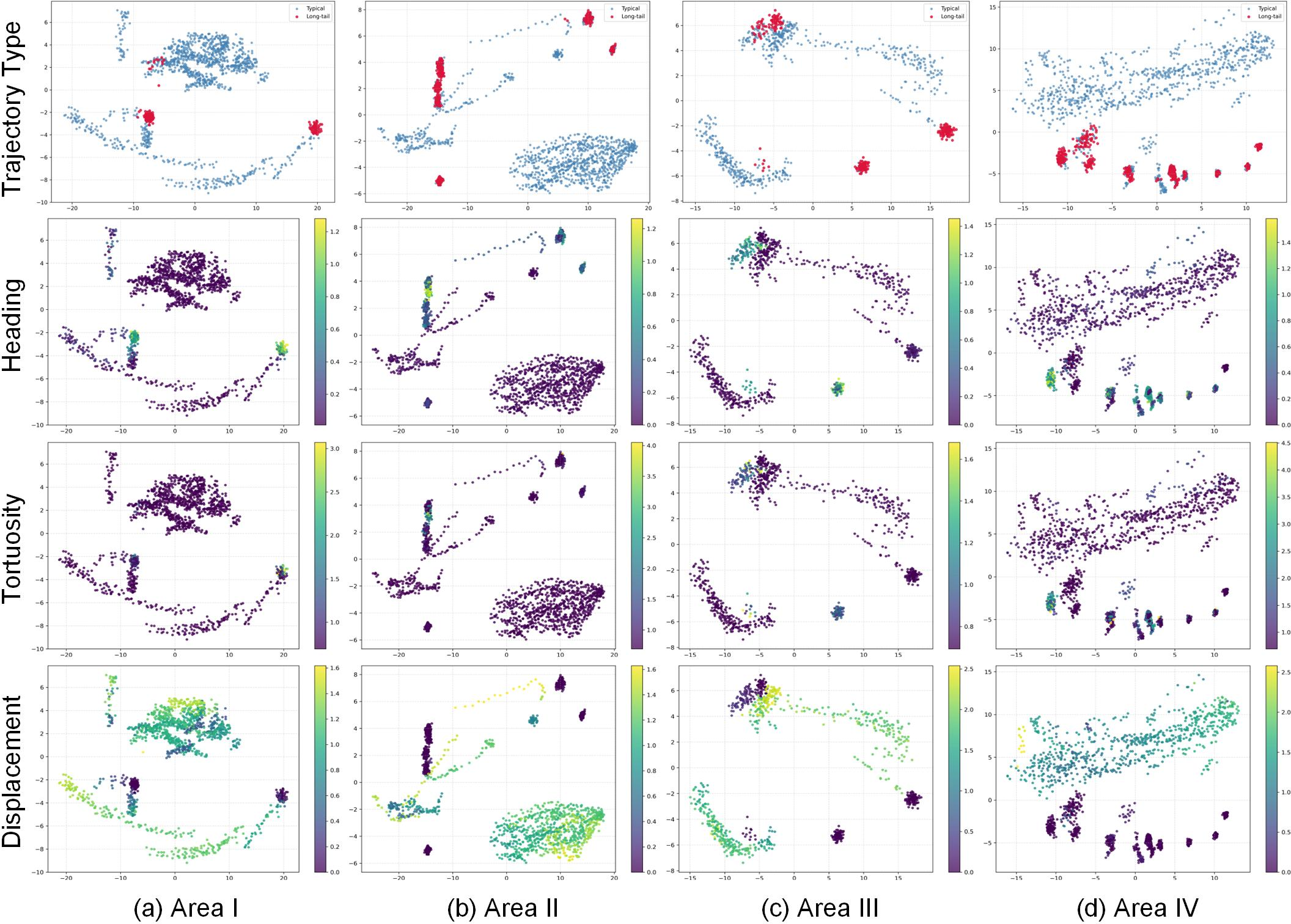
Figure 3: PCA visualizations reveal structured latent spaces with localized regions for long-tail trajectories and organized gradients for motion descriptors.
Vessel Group Trajectory Bank (VGTB)
The VGTB module clusters historical AIS trajectories, using K-means over normalized motion features to construct a repository of representative trajectory modes. During inference, the bank provides coarse motion priors by searching for prototypes similar to the observed trajectory, which are adaptively fused with network predictions via learnable offsets and dynamic gating—effectively refining the forecast while handling rare, complex, or sparse data cases.
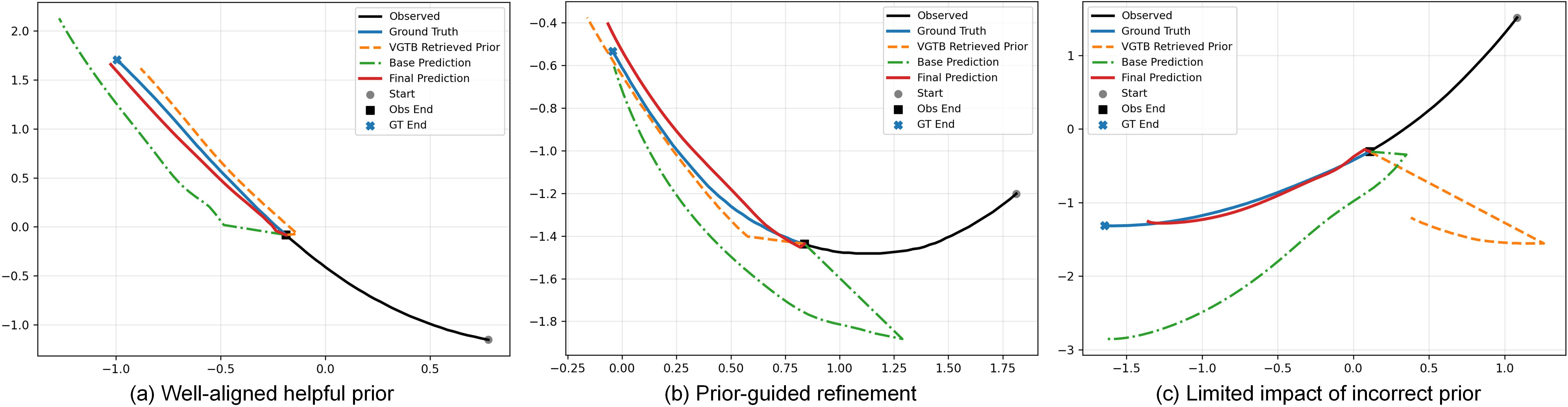
Figure 4: Prior-effect visualization displays (a) helpful prior alignment, (b) prior-guided refinement, and (c) limited impact of an incorrect prior.
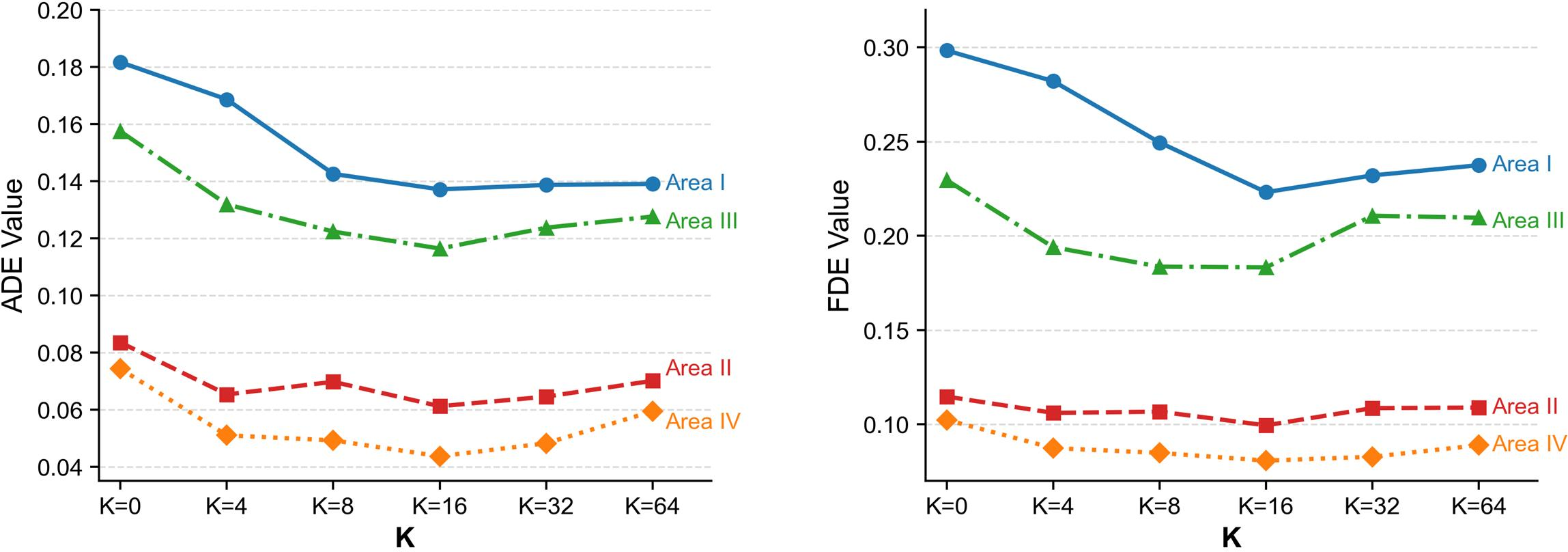
Figure 5: Ablation on cluster number K in VGTB demonstrates performance tradeoffs versus computational cost.
Dataset and Evaluation
The Maritime-MmD+ dataset, detailed in the paper, provides temporally and spatially aligned AIS and CCTV trajectories from complex, high-traffic waterway scenarios. The evaluation spans varying prediction horizons ($12, 24, 36$ steps), traffic densities (ϕl, ϕm, ϕh), and simulated AIS missing rates (ρ=0.1,0.2,0.3). Performance is measured via ADE and FDE, with multimodal input (AIS, CCTV, Scene Representations) and comparison against state-of-the-art baselines (RNNs, LSTM, Transformers, GNN, VAE, GAN, and domain-specific methods).
Numerical Results
CmIVTP outperforms all baselines in both no-missing and missing data conditions, achieving the lowest ADE and FDE across all task parameters. The error gap is substantial—especially in missing-AIS and high-density scenarios, where baseline models degrade markedly due to data sparsity, while CmIVTP retains robust convergence. Ablation studies confirm the critical complementarity of multimodal inputs and the efficacy of each architectural module for accuracy and robustness. Analysis of multimodal prediction on long-tail trajectories indicates that the learned latent space produces diverse, non-collapsed forecasts, even for rare maneuver patterns.
Implications and Future Directions
Practically, CmIVTP enables resilient, high-fidelity vessel trajectory prediction for intelligent maritime systems, particularly in contexts with unreliable AIS coverage and dynamic environmental challenges. Theoretically, it demonstrates the necessity of cross-modal fusion and uncertainty modeling in open-water, multi-agent navigation domains, transcending the limitations of unimodal and deterministic approaches. The multimodal fusion paradigm is essential for risk-aware maritime safety and autonomous vessel operation.
Future research should address robustness in extreme visual degradation (e.g. fog, darkness) and complete AIS blackout, further expand dataset diversity, and explore efficient pre-training and transfer learning for model generalization to new waterways. Additionally, scaling the approach for real-time large-scale deployment and extending to intelligent traffic management, anomaly detection, and emergency response are promising directions.
Conclusion
CmIVTP presents a technically rigorous, modular framework for cross-modal vessel trajectory prediction, integrating AIS and CCTV modalities with learned environmental representations, uncertainty-aware modeling, and historical motion priors. The architecture demonstrates strong empirical performance and resilience in complex, signal-denied maritime environments, establishing a robust foundation for next-generation intelligent transportation and autonomous navigation systems.