- The paper introduces a PAC-Bayesian framework that rigorously quantifies generalisation in physics-informed machine learning through PDE-based regularisation.
- It develops tight, multi-task generalisation bounds by leveraging Sobolev and Poincaré smoothness, which are validated on standard PDE benchmarks.
- The framework demonstrates improved label efficiency and practical self-bounding-aware training that maintains non-vacuous guarantees even under data scarcity.
Introduction and Motivation
Physics-informed machine learning (PIML) seeks to enhance classical data-driven learning by enforcing physical constraints, commonly represented by partial differential equations (PDEs), within the training objective. The empirical success of PIML, and particularly physics-informed neural networks (PINNs), in scientific and engineering applications is rooted in the intuition that incorporating mechanistic knowledge acts as an implicit regulariser, thus improving generalisation even in regimes with limited data. However, the statistical mechanisms through which physical structure influences generalisation, especially for unbounded regression losses and multi-objective settings (data, PDE, initial, and boundary residuals), have not been rigorously established. Most existing analyses rely on approximation or stability arguments, often offering little insight into the data-physics interplay governing out-of-sample performance.
This paper, "A PAC-Bayesian View of Generalisation for Physics-Informed Machine Learning" (2605.26341), establishes a formal PAC-Bayesian framework for PIML, characterising generalisation gaps in PDE-driven regression under unbounded losses. Distinct from prior approaches, it constructs high-probability guarantees leveraging the structural decomposition of PIML objectives and avoids loose union-bound aggregations of multi-loss terms.
The foundational contribution is the derivation of PAC-Bayesian generalisation bounds that are suited to regression tasks with potentially heavy-tailed loss distributions, as often encountered with squared error or PDE residuals. The analysis employs a multi-task perspective: each component risk (data fit, PDE residual, IC, BC) is treated simultaneously in the PAC-Bayes framework, yielding bounds that scale tightly with total sample size and share complexity terms across losses.
The complexity of the bounds depends on the input-gradient norms of the losses, revealing a direct connection between physical regularity (as imposed by the governing PDE operators) and a model's generalisation capacity. The framework is instantiated under two core regularity assumptions:
- Sobolev-Smoothness: Assuming the learning model satisfies a Φ-Sobolev inequality, the cumulant-generating function (CGF) of the losses can be bounded in terms of the expected squared norm of the loss input-gradients, with a constant dependent on Sobolev regularity.
- Poincaré-Smoothness: Assuming a Poincaré-type inequality, the loss variance is controlled by its Dirichlet energy, producing a bound with complexity scaling by the sum of expected squared input-gradients (again modulated by a Poincaré constant).
Both regimes result in generalisation gap bounds that, up to logarithmic factors, scale as the square root of the weighted input-gradient complexity times a divergence term (KL or χ2), but the Sobolev-based guarantees are strictly tighter, especially regarding the penalty on the confidence parameter.
Practical Considerations for Bound Tightness
Empirical gradient norms for loss functions grow rapidly as one moves away from a well-trained model in parameter space, dramatically loosening the theoretical bounds if global uniformity is required. This observation motivates a local analysis—estimating the relevant constants within a compact neighborhood of a high-quality prior. Clipping loss values and gradients is shown to have negligible impact locally but greatly stabilises bound calculations, ensuring non-vacuous guarantees in realistic regimes.
The framework provides an end-to-end practical algorithm. The prior is first fitted to physics-only constraints, then used as the center for posterior exploration and estimation of Lipschitz, Sobolev, and Poincaré constants. Posterior learning seeks to directly minimise the PAC-Bayes-derived upper bounds (self-bounding-aware training), with bound computation incorporating stochastic surrogates over the posterior distribution’s parameterised family.
Empirical Evaluation: Tight Bounds in Practice
The effectiveness of the proposed framework is validated on standard PDE benchmarks, including 1D wave, reaction, and convection problems, across regimes with varying quantities of observational data.
In the large-data regime (md=30000), the Sobolev-based PAC-Bayes bound (termed Ours-Sob.) consistently achieves non-vacuous, tight generalisation gaps—less than 2× the test risk—outperforming both union-bound aggregations (U-Sob., U-Poi.) and Poincaré-based variants. The bounds remain informative even as the sample size drops to md=300 (restricted-data regime), although some inflation is observed due to estimation looseness and less regularity in the data-fidelity terms.
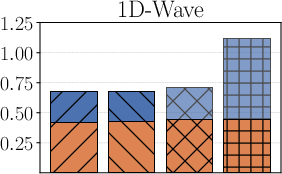
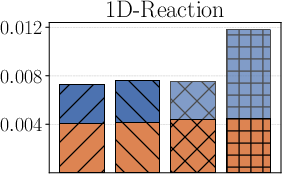
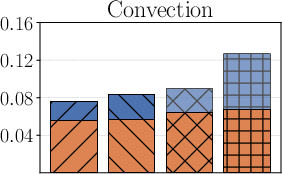

Figure 1: Test error and generalisation bounds for multiple methods on the 1D-Wave, 1D-Reaction, and Convection problems with md=30k.
When further reducing md to extremely small values (down to md=2), the framework demonstrates that tight, non-vacuous generalisation guarantees (≈1.75 for 1D-Wave) are retained if the model remains sufficiently regularised by physics priors and attains low empirical error.
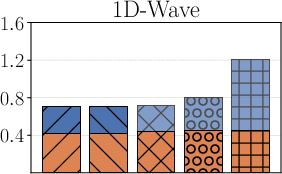
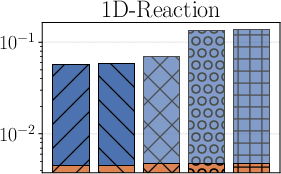
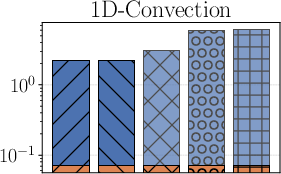

Figure 2: Test error and generalisation bounds under severe observational data scarcity (md=300), demonstrating robustness of the PAC-Bayes approach.
Across all experiments, the bounds are shown to be effectively minimised during posterior training, with notable decreases after bound-targeted optimisation—highlighting the practicality of the self-bounding-aware approach.
Theoretical and Practical Implications
The established PAC-Bayesian view provides several significant takeaways:
- Direct Link Between Regularity and Generalisation: The explicit dependency on input-gradient mean squared norm formalises the intuition that PDE (and thus physics) regularity quantitatively reduces effective model complexity, improving generalisation.
- Avoidance of Union-Bound Looseness: The multi-task PAC-Bayes construction yields significantly tighter generalisation bounds relative to classical approaches that apply separate (and thus suboptimal) tuning and aggregation for each loss term.
- Label-Efficient Priors: By showing that effective priors can be constructed exploiting only the PDE structure—without observed data—the framework enhances label efficiency in scientific domains.
- Feasibility of Surrogate Bound Optimisation: The algorithmic design demonstrates that even in high-dimensional, heavy-tailed, or multi-task PIML contexts, such bounds are computable and can drive practical training.
Prospects for Future Developments
The framework opens several research avenues:
- Refined, Data-Dependent Constants: Improving the estimation of regularity and Lipschitz constants, possibly via data-driven or adaptive methods, could further tighten bounds and enhance efficiency.
- Construction of Physics-Informed Priors: Developing systematic methods for generating structured priors that incorporate physical insights beyond PDE structure—covering broader classes of scientific models.
- Extensions to Complex Physical Systems and Implicit Regularisation: Adapting the PAC-Bayesian framework to more intricate multi-physics, high-dimensional, or multi-scale systems, and exploring connections with implicit regularisation phenomena observed in overparameterised neural PDE solvers.
- Objective Design for Unbalanced Task Settings: Developing objectives that better integrate sample-centric constraints in heterogeneous or partially observed physical systems.
Conclusion
This work rigorously establishes the foundational statistical mechanisms governing generalisation in physics-informed machine learning via a PAC-Bayesian lens (2605.26341). The theory articulates, in a concrete and computable fashion, how physical structure regularises and improves learning from finite data, and supports this with both a principled training algorithm and robust empirical validation. The resulting framework yields non-vacuous, tight, and optimisable generalisation bounds, even in label-scarce regimes, providing a meaningful advance in the trustworthy deployment of PIML methods in scientific domains.