Efficient Benchmarking Is Just Feature Selection and Multiple Regression
Abstract: Efficient benchmarking techniques aim to lower the computational cost of evaluating LLMs by predicting full benchmark scores using only a subset of a benchmark's questions. By reframing this problem as an instance of multiple regression with feature selection, we find that existing efficient benchmarking methods can be greatly improved by simply using kernel ridge regression at the prediction stage. Additionally, using an information-theoretic feature-selection algorithm called minimum redundancy maximum relevance (mRMR), we can further improve upon these methods by selecting question subsets that will be maximally useful for prediction. Except in very data-poor settings, these approaches consistently achieve smaller prediction errors (in both MAE and RMSE), and greater ranking correlation between predicted and true scores (in both Spearman $ρ$ and Kendall $τ$) across a range of benchmarks using both binary and continuous metrics. Furthermore, mRMR subsampling is much faster than competitor methods (which often involve fitting probabilistic models or running clustering algorithms), and is more likely to select the same questions under different random seeds or training data splits. Tutorial code can be found at https://github.com/sambowyer/mrmr_eval .

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about testing LLMs more quickly and cheaply. Instead of running a model on every single question in a big benchmark (which can take a lot of time and computing power), the authors show how to pick a small set of questions and still predict the model’s overall score very accurately. Their main message is simple: efficient benchmarking can be done well by treating it like two classic steps in statistics—pick useful “features” (questions) and learn a prediction formula (multiple regression).
What questions were the researchers trying to answer?
They wanted to know:
- Can we choose a small group of questions that are especially good at telling us how a model will do on the whole benchmark?
- Given a model’s answers on just those questions, can we accurately predict its full score and how it ranks compared to other models?
- Will this work for different kinds of scores (like right/wrong, or continuous scores such as ROUGE or pass@k), and can it be fast and reliable?
How did they do it?
Think of a benchmark as a big exam with lots of questions. The authors split the problem into two stages:
- Stage 1: Pick a small “coreset” of questions that are most useful.
- Stage 2: Use the answers on that coreset to predict the model’s overall exam score.
Here’s how they handled each stage:
Picking the questions (feature selection with mRMR)
- Feature selection means choosing the most informative items from a larger set. Here, each question is treated as a “feature.”
- mRMR stands for Minimum Redundancy Maximum Relevance:
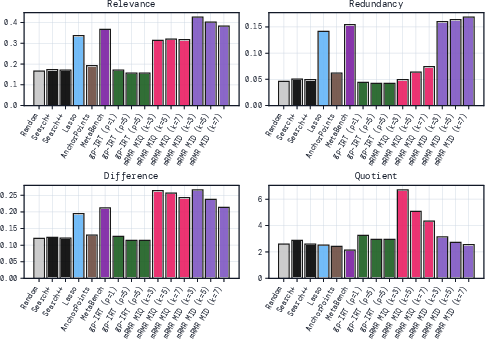
- Maximum relevance: choose questions that closely relate to the overall benchmark score. In everyday terms, these questions are strong clues to how the model will do overall.
- Minimum redundancy: avoid questions that duplicate each other’s information. Don’t pick five near-identical questions; pick diverse ones.
- To measure “how related” two things are, they use mutual information, a number that tells you how much knowing one thing helps you predict another. High mutual information means a question is very helpful; low redundancy means questions aren’t repeating the same signal.
Predicting the overall score (regression)
- Regression is a way to learn a formula that predicts an outcome (the full score) from inputs (the coreset question scores).
- Ridge regression: a sturdy, simple method that prevents overfitting by shrinking overly large weights. Think of it as a balanced recipe that doesn’t let any single ingredient dominate too much.
- Kernel ridge regression: an upgraded version that can learn from combinations of questions (not just each question alone). It’s like noticing that doing well on Question A and Question B together tells you more than either alone. The “kernel” trick lets the method consider these interactions without making the computation complicated.
They also compared their approach against other popular methods, like:
- AnchorPoints (choosing representative questions by clustering),
- TinyBenchmarks/gp-IRT (using Item Response Theory, a model from testing/psychometrics),
- Lasso (another regression method that picks features by making some weights exactly zero),
- Random selection and exhaustive random search baselines.
What did they find, and why is it important?
Here are the main results:
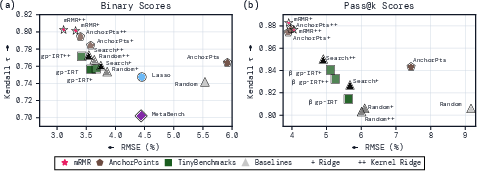
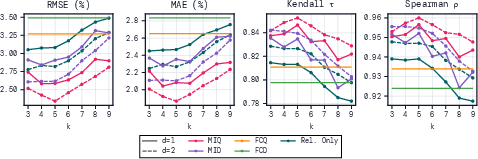
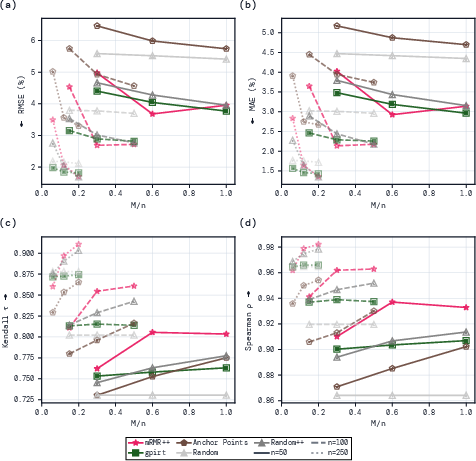
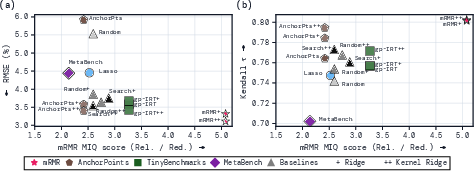
- Using mRMR to pick the questions and kernel ridge regression to predict the score (they call this mRMR++) gave the best performance in many cases.
- It consistently had smaller prediction errors and better agreement with the true ranking of models (high Spearman and Kendall rank correlations), especially on benchmarks with right/wrong scoring.
- Kernel ridge regression also improved older methods: swapping in kernel ridge (instead of their original predictors) made AnchorPoints and similar approaches more accurate.
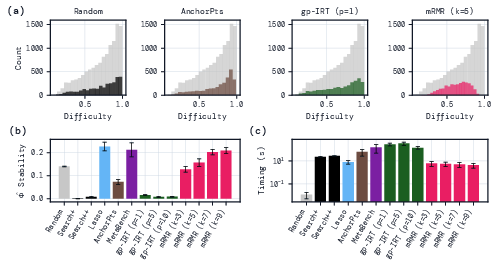
- mRMR was fast. It ran much quicker than methods that need heavy probabilistic modeling or large clustering steps.
- mRMR was stable. Across different random seeds or training splits, it tended to pick the same questions more often, which means the selected coreset is reliable.
- It worked on both kinds of metrics:
- Binary scores (correct/incorrect).
- Continuous scores (like ROUGE-L, BERTScore, and pass@k in coding).
- For pass@k (coding tasks), coresets chosen with pass@1 often helped predict other pass@k values too, especially when using kernel ridge.
- Caveat: In very data-poor settings (too few source models to learn from), some IRT-based methods could have lower error, though they were less stable and worse at ranking.
Why this matters: Testing LLMs is expensive, especially on complex tasks. These results mean you can evaluate models faster and cheaper while still getting trustworthy scores and rankings. That saves computing resources and lets researchers iterate on training and settings more quickly.
What’s the impact?
- Practical savings: You can test models using only 5–15% of the original questions and still get strong predictions of the full score.
- Better workflows: Faster, stable evaluations help during model training, ablation studies, and tuning (like temperature or prompts), because you get good feedback sooner.
- Broad applicability: The approach works across different benchmarks and scoring styles, making it easy to adopt.
- Simple tools, strong results: mRMR and kernel ridge regression are well-known, easy to implement, and do not require complex modeling. Just smarter question selection plus a better prediction formula gets you most of the gains.
In short, the paper shows that efficient benchmarking can be treated as “pick the best questions” plus “fit a good regression,” and doing so delivers accurate, fast, and stable evaluations of LLMs without needing to run every single benchmark question.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Data requirements and sample complexity: The approach relies on per-question scores from M source models and degrades in data-poor settings; quantify minimal M versus coreset size n needed to achieve target error or rank-correlation thresholds, and derive sample-complexity curves to guide practitioners.
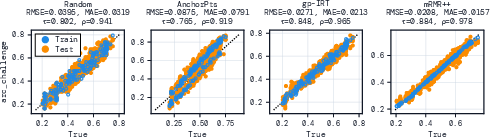
- Out-of-distribution generalization: The method shows an S-shaped bias (overpredicting very weak models and underpredicting very strong ones) and is not recommended for models far outside the source-model performance range; develop OOD-robust predictors (e.g., importance weighting, covariate-shift correction, conformal calibration) and evaluate on frontier models.
- Continuous-metric feature selection: On non-pass@k continuous metrics, mRMR coresets underperform brute-force search; investigate alternative selection objectives better suited to continuous targets (e.g., HSIC-based criteria, submodular mutual information, Fisher kernels, or regression-aware forward selection).
- Mutual information (MI) estimation with few samples: The MI estimators (KSG and mixed discrete–continuous) can be biased/unstable for small M and sensitive to the k-NN parameter; assess estimator robustness, try parametric or shrinkage MI, copula-based MI, or discretization schemes with bias correction, and provide guidance for estimator/hyperparameter choice.
- Pass@k generalization strategy: Coresets built on pass@1 only partially generalize across k; design multi-k-aware coresets that jointly optimize predictive performance across k∈{1,…,64}, or model pass@k as a parametric function of pass@1 to improve transfer.
- Cost-aware coreset selection: The method assumes uniform per-question cost; extend selection to incorporate heterogeneous evaluation costs (e.g., code execution, multi-turn interactions) to maximize information per unit compute/latency.
- Coverage and capability diversity: mRMR tends to select average-difficulty items; introduce explicit coverage constraints (e.g., across subjects/capabilities in MMLU) or diversity-aware objectives (e.g., submodular facility location, DPPs) and quantify capability coverage.
- Stability guarantees: While empirical stability is reported, there are no theoretical guarantees; analyze stability of greedy mRMR under sampling noise and derive conditions under which selected coresets remain invariant as M or the training pool changes.
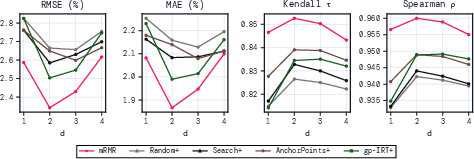
- Theoretical performance bounds: Provide generalization/error bounds for ridge/kernel ridge predictors in this setting (as a function of M, n, kernel degree d, and score noise), including conditions for when polynomial features help versus overfit.
- Handling stochastic/heteroscedastic noise: Per-question scores can be noisy (e.g., pass@k variance, summarization metric instability); incorporate uncertainty into selection and prediction (e.g., variance-aware MI, weighted regression, errors-in-variables models) and measure robustness to label noise.
- Missing data robustness: Leaderboard datasets often have missing per-model per-question entries; develop imputation strategies or selection/prediction methods robust to missingness mechanisms, and quantify the impact on stability and error.
- Feature representation beyond per-model scores: The method represents questions only by historical model scores; explore augmenting with question text embeddings, metadata, difficulty proxies, or activation features to reduce dependence on large M and improve cold-start for new benchmarks.
- Model class exploration: Beyond (kernel) ridge, assess non-linear predictors (e.g., GAMs with interactions, tree ensembles, GPs) and models with heteroscedastic errors; establish model selection protocols that remain reliable under tiny-sample regimes.
- Hyperparameter selection under small M: Cross-validation for λ (regularization) and kernel degree d may be unreliable with few models; investigate Bayesian/empirical-Bayes tuning, marginal-likelihood selection, or nested CV variants designed for low M.
- Joint multi-benchmark coresets: Benchmarks are treated independently; study whether cross-benchmark coresets can share items/skills to amortize evaluation cost (e.g., jointly selecting items across related benchmarks) and compare to IRT-based multi-benchmark methods without relying on IRT.
- Dynamic updates and benchmark drift: Coresets are static; design incremental update rules that refresh coresets as new models/versions arrive or as benchmarks evolve, and add drift detection to trigger re-selection.
- Uncertainty quantification for decisions: Provide calibrated confidence intervals for predicted scores and ranks (e.g., via bootstrap, Bayesian ridge, or conformal methods) and evaluate calibration quality for model comparisons.
- Fairness across model families: Assess whether coresets overfit to the distribution of training-model families (e.g., open vs. closed, instruction-tuned vs. base); design selection that enforces fairness/coverage across families and audit subgroup performance.
- Evaluation breadth and realism: Experiments omit long-horizon, interactive, or human-in-the-loop tasks (e.g., SWE-bench, multi-turn dialogue with human ratings); extend to these settings and adapt selection to path-dependent or subjective scoring.
- End-to-end compute trade-offs: Report selection time but not full trade-offs (selection + coreset evaluation + prediction) under realistic batching/parallelism constraints; provide compute–accuracy/ranking curves to guide deployment.
- Robustness to item perturbations: Test whether coresets remain informative under paraphrasing/rephrasing or adversarial edits; design selection robust to surface-form variations.
- Interpretability of interactions: Kernel ridge with degree d=2 leverages pairwise interactions without interpretability; develop post-hoc analysis to identify influential questions and interactions driving predictions to support auditability.
- Comparative breadth in feature selection: The paper does not compare against DPPs, facility-location-based selection, influence-function-based core sets, or determinantal submodular methods; include these baselines and analyze stability–performance trade-offs.
- Label shift across pass@k values: Question difficulty shifts across k; formalize this as a domain shift and evaluate domain-adaptation corrections (e.g., reweighting or invariant selection) to improve cross-k generalization.
- Human-evaluation budgets: Methods assume automatic metrics; adapt selection when labels come from humans with tight budgets by integrating active learning/uncertainty sampling and measuring gains in human-judgment settings.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now using the paper’s mRMR-based coreset selection and (kernel) ridge regression approach, along with sector links, potential tools/workflows, and key assumptions that affect feasibility.
- Training checkpoint triage and gating (software/ML infrastructure)
- What: Rapidly approximate full-benchmark scores for each training checkpoint using a small, static coreset; trigger early stopping or promote promising runs.
- Tools/workflows: “Eval-accelerator” module integrated into MLflow, Weights & Biases, LangSmith; CI/CD gating step that runs coreset evals on each checkpoint.
- Assumptions/dependencies: Access to per-question scores from M ≥ 15–30 source models on the same benchmark; test models are in-distribution relative to source models; kernel degree/cross-validation set up; predictions less reliable at performance extremes.
- Efficient hyperparameter and inference-time sweeps (software)
- What: Use coreset predictions to rank sampling settings, prompt formats, or few-shot configurations before committing to full evaluations.
- Tools/workflows: Automated sweep controllers that use mRMR coresets + kernel ridge to prune the search space.
- Assumptions/dependencies: In-distribution sweeps; enough M/n for stable regression (e.g., coreset ≈ 5–15% of items); continuous metrics supported but may benefit from model selection between linear vs. quadratic kernels.
- Enterprise model shortlisting and procurement (cross-sector: finance, healthcare, enterprise IT)
- What: Shortlist candidate LLMs with low-cost coreset evals while preserving rank orderings close to full-benchmark results.
- Tools/workflows: Procurement dashboard that runs coreset-based “screening” and reserves full evals for finalists.
- Assumptions/dependencies: Candidate models similar to source pool; legal ability to run benchmark queries; communicate uncertainty and use full evals for contractual decisions.
- Continuous integration (CI) quality gates for model releases (software vendors/platforms)
- What: Regressions/quality checks on a stable, repeatable mRMR coreset per benchmark before release.
- Tools/workflows: GitHub Actions/Buildkite step invoking mRMR++ predictions; fail/pass thresholds on rank correlations (Kendall τ/Spearman ρ) or MAE/RMSE.
- Assumptions/dependencies: Stable coreset reproducibility; periodic refresh if data distribution drifts.
- Cheaper code-generation evaluation using pass@1 coresets to estimate pass@k (software/DevTools)
- What: Build coresets on pass@1 and reuse them to predict pass@k (k ∈ {2,4,…,64}) to reduce runs and generations.
- Tools/workflows: IDE/CI plugin that estimates pass@k from fewer generations; benchmarking scripts calling kernel or linear ridge on coreset results.
- Assumptions/dependencies: Coreset generalizes across k; models are in-distribution; ensure enough generations for low-variance pass@1 signals.
- Benchmark curation and maintenance (academia/open-source leaders)
- What: Use mRMR to identify maximally informative, minimally redundant questions; curate “tiny” yet representative benchmark slices.
- Tools/workflows: Coreset builder CLI and notebooks (based on the paper’s GitHub) to refresh coresets as new source models arrive.
- Assumptions/dependencies: Sufficient source-model diversity; consider fairness and coverage—avoid overfitting to a narrow capability profile.
- Compute budgeting and evaluation scheduling (energy/finance/operations)
- What: Use quick coreset predictions to decide whether a full, costly eval is warranted, optimizing compute spend and carbon budget.
- Tools/workflows: Budget-aware scheduler that triggers full runs only when predicted gains exceed a threshold.
- Assumptions/dependencies: Organization-defined error tolerance; track calibration errors and re-estimate when drift occurs.
- Governance and audit sampling (regulated sectors: finance, healthcare, public sector)
- What: Stable, repeatable coresets act as audit samples for compliance checks and internal model reviews.
- Tools/workflows: Governance dashboards that store coreset definitions, predicted vs. true score deltas, and ranking stability over time.
- Assumptions/dependencies: Static coresets suit routine checks; document limitations (e.g., binary metrics strongest, continuous metrics require care).
- Community leaderboard pre-screening (academia/open-source)
- What: Quickly estimate a model’s placement before committing to full, high-variance, multi-benchmark runs.
- Tools/workflows: Leaderboard integration that accepts coreset results and displays provisional standings with confidence notes.
- Assumptions/dependencies: Transparent caveats; top candidates still need full evaluation; avoid gaming by enforcing coreset secrecy or rotation.
- Research triage for ablations and ideas (academia/industry R&D)
- What: Rank-order ablations and research ideas for likely performance impact across multiple benchmarks using coreset predictions.
- Tools/workflows: Meta-evaluation notebooks with cross-validated kernel degree selection (d=1 vs. d=2).
- Assumptions/dependencies: Sufficient source data; beware under/overfitting on small M/n; continuous metrics may benefit from linear kernels.
- “Coresets-as-a-service” for common benchmarks (industry/academia)
- What: Distribute precomputed, stable coresets (and trained predictors) for popular benchmarks to reduce barrier to entry.
- Tools/workflows: Package registry with coreset IDs, seed, and mRMR settings; API for score prediction given coreset results.
- Assumptions/dependencies: Licensing of benchmarks; transparency on source model pool and update cadence.
Long-Term Applications
The following applications require further research, scaling, standardization, or integration with adjacent advances (e.g., adaptive evaluation, OOD prediction, uncertainty quantification).
- Standardized efficient-evaluation protocols and certifications (policy/regulation)
- What: Bodies like NIST/ISO codify efficient benchmarking protocols (coreset selection, prediction, error reporting).
- Tools/workflows: Compliance templates, audit packs, certified coreset libraries.
- Assumptions/dependencies: Stakeholder consensus; rules for uncertainty, drift, and out-of-distribution (OOD) models.
- Adaptive evaluation with early stopping (software/AI assurance)
- What: Combine mRMR-informed priors with adaptive test selection to dynamically tailor question choice per model and stop early when confident.
- Tools/workflows: Active-testing orchestrators with stopping rules and budget control.
- Assumptions/dependencies: New algorithms to merge static coresets with adaptive selection; robust uncertainty estimates.
- OOD performance prediction for frontier models (academia/industry)
- What: Extend to prediction-powered inference or covariate-shift approaches to extrapolate from weaker source models to stronger test models.
- Tools/workflows: Hybrid predictors (mRMR++ + PPI) with guardrails and small calibration subsets.
- Assumptions/dependencies: Reliable small labeled sets for calibration; theoretical guarantees; careful bias control.
- Multi-metric and cross-benchmark forecasting for safety/robustness (AI safety/assurance)
- What: Jointly predict across related metrics (e.g., toxicity, factuality, robustness) using multi-target kernel ridge and shared coresets.
- Tools/workflows: Safety dashboards with cross-metric error tracking and rank-correlation matrices.
- Assumptions/dependencies: High-quality, multi-metric source data; fairness and subgroup checks; calibrated uncertainty.
- Energy- and carbon-aware evaluation planners (energy/sustainability)
- What: Optimize evaluation plans to minimize carbon while maintaining rank fidelity (Kendall τ/Spearman ρ) targets.
- Tools/workflows: Carbon-cost models integrated with coreset schedulers; green-compute reporting.
- Assumptions/dependencies: Accurate carbon accounting; organizational incentives and policies.
- Drift-aware continual monitoring with coreset rotation (production ML across sectors)
- What: Detect benchmark- or data-drift and refresh coresets/predictors to retain accuracy in long-lived systems.
- Tools/workflows: Drift detectors coupled with automatic coreset regeneration (mRMR) and predictor retraining.
- Assumptions/dependencies: Monitoring infrastructure; retraining budget; versioning and auditability.
- Regulated domain evaluation kits (healthcare, finance, legal)
- What: Domain-specific coreset kits aligned with regulatory expectations for coverage and repeatability.
- Tools/workflows: Packaged question sets, documentation, and reference predictors; evidence-ready reports.
- Assumptions/dependencies: Access to sensitive data under governance; IRB/ethics approvals; human oversight loops.
- Semi-automated benchmark design (academia/benchmark publishers)
- What: Use mRMR signals to identify gaps (low relevance/high redundancy) and automatically generate new items to improve coverage.
- Tools/workflows: Item-generation assistants, MI-based diagnostics, iterative curation pipelines.
- Assumptions/dependencies: High-quality item generation (synthetic/human-in-the-loop); robust MI estimation in low-data regimes.
- Federated/edge benchmarking with minimal data movement (edge/IoT/privacy)
- What: Send only coreset queries to edge models and predict overall performance server-side to reduce bandwidth and protect data.
- Tools/workflows: Federated evaluation protocols; privacy-preserving telemetry; on-device coreset caching.
- Assumptions/dependencies: Privacy constraints; secure transport; model heterogeneity management.
- Procurement and SLA frameworks with uncertainty-aware predictions (enterprise/legal)
- What: Contractual SLAs based on predicted performance plus confidence bands; periodic full audits for validation.
- Tools/workflows: UQ-augmented predictors; legal templates for “predict-then-validate” procurement.
- Assumptions/dependencies: Trusted uncertainty quantification; legal acceptance; dispute resolution tied to full re-tests.
- Educational modules on efficient evaluation and information theory (education)
- What: Curricula and labs demonstrating mRMR, MI estimation, and kernel ridge with real benchmarks, reducing compute needs for teaching.
- Tools/workflows: Interactive notebooks, lightweight datasets, GitHub tutorials.
- Assumptions/dependencies: Stable open datasets; institutional adoption; basic Python/ML literacy.
Cross-cutting assumptions and caveats
- Data requirements: Method needs per-question scores from a set of source models (M typically ≥ 15–30 for strong results; performance degrades in very low-M regimes).
- Distributional match: Best for in-distribution test models relative to the source pool; accuracy declines for models far below/above source performance.
- Underspecification: Keep a reasonable M/n ratio; extremely large coresets relative to M reduce regression reliability.
- Metric sensitivity: Binary metrics show strongest gains; for continuous metrics, compare linear vs. quadratic kernels via cross-validation; sometimes brute-force search baselines can be competitive.
- Stability and refresh: Static coresets are stable and fast, but should be refreshed as benchmarks or model landscapes evolve.
- Transparency: Communicate prediction error, rank-correlation, and known biases (e.g., slight S-shaped regression at extremes); use full evals for high-stakes decisions.
Glossary
- AnchorPoints: A clustering-based efficient benchmarking method that selects representative questions and uses a weighted mean for prediction. "Using kernel ridge regression also improves the performance of existing efficient benchmarking methods AnchorPoints and TinyBenchmarks."
- BERTScore: An automatic evaluation metric that compares text generation to references using contextual embeddings. "For GovReport we have two metrics, ROUGE-L \citep{lin_automatic_2004} and BERTScore \citep{zhang_bertscore_2020}."
- Beta-IRT: A continuous variant of Item Response Theory modeling scores on [0,1] via the Beta distribution. "To adapt gp-IRT to continuous data, we use the -IRT model from \citet{noel_beta_2007}, described in \cref{app:cirt}."
- Coreset: A selected subset of questions used to estimate full-benchmark performance efficiently. "Select a coreset of questions of size ."
- Cross-validation: A model selection technique that partitions data into folds to tune hyperparameters. "where is a regularisation coefficient (which we select via cross-validation) and is the identity matrix."
- Entropy: A measure of uncertainty in a random variable, used to define mutual information. "can be expressed in terms of the entropy of the variables (with joint entropy and conditional entropy ):"
- Fisher information: A quantity measuring how informative an observation is about model parameters. "select the most informative question (in terms of Fisher information)."
- GAM: Generalized Additive Model; a regression model where the response depends on a sum of smooth functions of predictors. "Prediction happens on coreset questions using a linear GAM."
- gp-IRT: Generalised performance-IRT; a method combining IRT-based predictions with clustering-based weighted means. "The second method, Generalised p-IRT (gp-IRT), predicts a convex combination of the p-IRT score and an AnchorPoints score"
- Item Response Theory (IRT): A probabilistic framework modeling the interaction between latent model ability and item parameters to predict correctness. "The two-parameter IRT model represents the probability of model correctly answering question as:"
- K-means clustering: An algorithm that partitions data into k clusters by minimizing within-cluster variance. "\citet{vivek_anchor_2024} perform K-means clustering over "
- Kendall’s tau (τ): A rank correlation coefficient measuring the agreement between two rankings. "reduced prediction error (RMSE) and increased ranking correlation (Kendall )."
- Kernel ridge regression: Ridge regression performed in a feature space induced by a kernel function to capture nonlinear relationships. "we find that existing efficient benchmarking methods can be greatly improved by simply using kernel ridge regression at the prediction stage."
- Kernel trick: A technique allowing inner products in high-dimensional feature spaces to be computed via kernels without explicit mapping. "Thanks to the kernel trick (\citet{boser_training_1992}; see \cref{app:kernel_trick})"
- KL-divergence: A measure of discrepancy between two probability distributions, used to express mutual information. "Equivalently, the MI can be expressed in terms of a KL-divergence between the joint distribution of the two variables"
- KSG estimator: A k-nearest-neighbor-based estimator for mutual information between continuous variables. "based on the continuous-continuous KraskovâStögbauerâGrassberger (KSG) estimator \citep{kraskov_estimating_2004}."
- L1 penalty: A sparsity-inducing regularization term that encourages zero coefficients. "Replacing ridge regression's penalty with an penalty causes many of the coefficients to shrink to 0"
- L2 penalty: A regularization term that shrinks coefficients to reduce variance and ensure invertibility. "The penalty shrinks coefficients and renders the matrix $(X^TX + \lambdaI)$ invertible"
- Lasso: A linear model with L1 regularization that performs variable selection by zeroing coefficients. "Lasso & penalty & Linear model"
- MAE: Mean Absolute Error; an average of absolute differences between predicted and true values. "smaller prediction errors (in both MAE and RMSE)"
- Maximum likelihood: A method for estimating parameters by maximizing the likelihood of observed data. "we estimate for a new test model via maximum likelihood on \cref{eq:irt}"
- MCMC: Markov Chain Monte Carlo; sampling-based algorithms for approximate Bayesian inference. "fitted using MCMC or variational inference."
- Medoid: The most centrally located data point in a cluster (minimizing distances to others). "select the medoid questions to form ."
- Minimum Redundancy Maximum Relevance (mRMR): A feature selection criterion maximizing relevance to the target while minimizing redundancy among selected features. "an information-theoretic feature-selection algorithm called minimum redundancy maximum relevance (mRMR)"
- Mutual information (MI): A measure of dependence between variables, quantifying shared information. "Mutual information measures the dependence between two variables"
- NP-complete: A class of problems believed to be computationally intractable to solve exactly in polynomial time. "Finding the globally optimal subset is NP-complete \citep{davies_np-completeness_1994}"
- Pass@k: A code-generation metric measuring whether any of k attempts solve a task. "such as ROUGE-L \citep{lin_automatic_2004} or pass@"
- PCA-corrected KSG estimator: A variant of the KSG MI estimator that applies PCA to improve estimation in certain settings. "we use a PCA-corrected KSG estimator \citep{gao_efficient_2015}."
- Polynomial kernel: A kernel function corresponding to all monomials up to a given degree, enabling interaction features. "with degree- polynomial kernels."
- Reproducing Kernel Hilbert Space (RKHS): A Hilbert space of functions associated with a kernel, enabling inner-product computations via kernels. "the Reproducing Kernel Hilbert Space, or RKHS"
- Ridge regression: Linear regression with L2 regularization to prevent overfitting and handle multicollinearity. "we proceed with ridge regression \citep{hoerl_ridge_1970, frank_statistical_1993, hastie_ridge_2020, hastie_elements_2001} since it is simple, quick and effective."
- RMSE: Root Mean Squared Error; the square root of the average squared difference between predicted and true values. "reduced prediction error (RMSE)"
- ROUGE-L: An n-gram overlap-based metric for summarization, focusing on longest common subsequence. "For GovReport we have two metrics, ROUGE-L \citep{lin_automatic_2004} and BERTScore \citep{zhang_bertscore_2020}."
- Spearman rho (ρ): A rank correlation coefficient based on the Pearson correlation of ranks. "greater ranking correlation between predicted and true scores (in both Spearman and Kendall )"
- Stratified sampling: Sampling that preserves the distribution across predefined strata (bins). "The training (source) models are selected via stratified sampling over ten equally-spaced bins"
- Variational inference: An optimization-based method for approximate Bayesian inference using tractable surrogate distributions. "fitted using MCMC or variational inference."
Collections
Sign up for free to add this paper to one or more collections.