- The paper introduces a contrastive percentile estimation method, using user-specific reservoir sampling to counteract skewed engagement data.
- It integrates value-weighted and bootstrapped loss extensions to co-optimize ranking fidelity and reward calibration in real-world settings.
- Empirical evaluations in offline and online tests reveal improved UAUC, balanced low-activity user performance, and scalable system integration.
PEARL: Unbiased Percentile Estimation via Contrastive Learning for Industrial-Scale Livestream Recommendation
Introduction and Problem Context
In large-scale industrial recommender systems, user engagement data is structurally skewed: a minority of highly active users generate a disproportionate volume of feedback, causing overrepresentation of their preferences and degrading overall model robustness. This "behavioral intensity imbalance" propagates user-side bias, resulting in models that amplify high-activity users’ signals while underrepresenting less active populations. This is particularly problematic in livestreaming platforms, where engagement dynamics are distinct from other modalities such as short-form videos.
Traditional debiasing strategies—including counterfactual learning, propensity reweighting, and representation-level disentanglement—treat bias as a global property and largely ignore sharply heterogeneous user activity. Recent relative preference modeling approaches like RAD convert absolute engagement into conditional percentiles but depend on auxiliary CDF models, introducing additional estimation complexity.
PEARL directly confronts these limitations by proposing a contrastive, user-centric, nonparametric percentile estimation framework. The method leverages real pairwise historical samples and a multi-sample contrastive loss to provide unbiased, scalable, and robust per-user preference signals, fundamentally improving the fidelity of livestream recommendation outcomes.
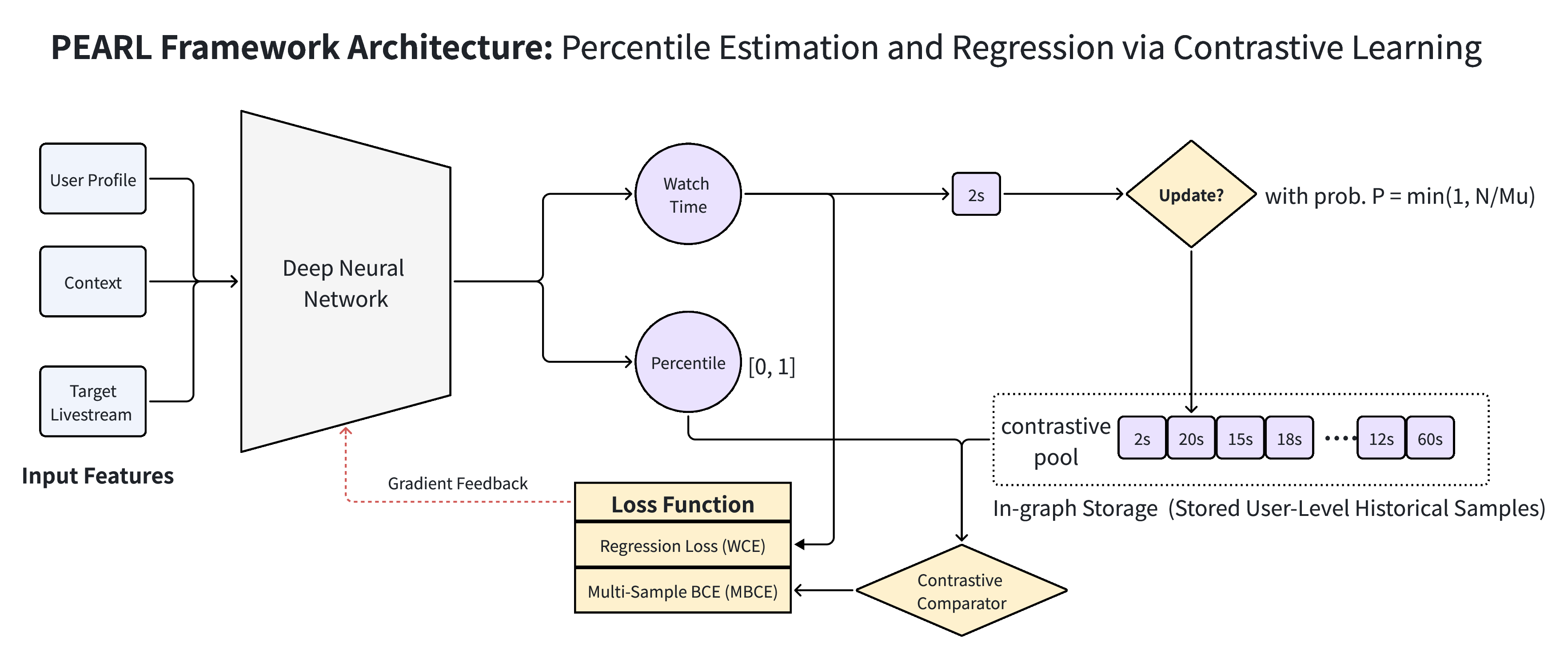
Figure 1: The PEARL architecture, with a user-keyed reservoir pool for unbiased sampling, and multi-sample contrastive learning for percentile loss computation.
Methodological Innovations
Contrastive Percentile Estimation
PEARL’s core contribution is casting percentile estimation as a series of stochastic contrastive decisions. For each user-item engagement y, the framework samples multiple historical engagement values {Yi′} from the same user’s reservoir. The model then learns to predict the probability that y>Yi′ for each reference, optimizing a multi-sample binary cross-entropy loss. This yields an unbiased estimate of the empirical percentile of y under the user’s behavioral distribution while circumventing expensive explicit distribution estimation.
This design is grounded in a proof that the expectation of this binary indicator aligns with the exact CDF percentile, removing the requirement for parametric modeling of user-wise engagement distributions. A multi-sample extension further reduces estimation variance, stabilizing training even in billion-scale streaming contexts via significant noise suppression (N-sample averaging).
Value-Weighted and Bootstrapped Extensions
To handle cases where target value magnitude carries economic or engagement significance, PEARL generalizes its loss to incorporate value weights, aligning the learned signal with cumulative reward. For discrete or highly sparse targets (e.g., rare gifts, reports), prediction-based bootstrapping smooths the percentile estimation by using prior model predictions rather than degenerate binary labels, yielding differentiable, informative training signals.
Co-Training with Regression Heads
In production, both ranking and value calibration are often required (e.g., auction scoring, explicit revenue optimization). PEARL integrates a dual-head co-training objective, jointly optimizing for debiased percentile ranking and absolute magnitude. This anchors the learned representations, preserving both personalized ranking fidelity and the scale calibration indispensable for real-world operations.
Efficient System Integration
PEARL implements a user-keyed reservoir sampling pool in-graph for real-time unbiased sampling, ensuring user-wide historical coverage with minimal footprint and latency. A dynamic gradient gating mechanism further suppresses high-variance updates from insufficiently populated reservoirs, stabilizing convergence.
Experimental Results
Offline Evaluation
Offline experiments on industrial-scale datasets reveal robust improvements over established baselines (regression, CQE, RAD) across targets:
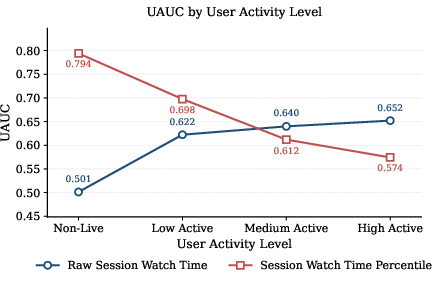
Cohort analysis by user activity demonstrates that baseline regression exhibits strong performance skewed toward high-activity users; performance on the non-live cohort is near random. PEARL, by contrast, delivers balanced improvements, particularly excelling among low-activity users who constitute the bulk of the platform’s user base.
Online A/B Testing
Deployment in a live production environment (billions of users, week-long experiments) confirms PEARL’s real-world impact:
- Watch Duration: +2.1%
- Consumption Amount: +0.80%
- Interaction Rate: +1.49%
- Report Rate: -6.91%
These are highly material improvements in industrial recommender KPIs, attributed to more accurate modeling of each user’s individual behavioral context and attenuation of intensity-driven bias. Notably, the reduction in report rate indicates improved user satisfaction and lower incidence of negative feedback.
Implications and Future Prospects
PEARL demonstrates that implicit behavioral debiasing via contrastive percentile learning is both theoretically principled and practically scalable. The approach obviates the need for auxiliary distributional models while capturing per-user preference nuance, making it broadly relevant for platforms with highly heterogeneous activity profiles. Direct modeling of relative behavior appears critical for robust personalization, especially as platforms diversify modalities and user bases.
Theory suggests broad applicability of this approach beyond livestreaming to any context where engagement bias distorts sample distributions: e-commerce, social feeds, and personalized advertising. Future extensions could include dynamic adaptation of reservoir pool sizes, more granular context-dependent contrastive sampling, or integrating contrastive percentile estimation with large-scale generative recommenders and sequential transducers.
Conclusion
PEARL introduces a robust, theoretically justified, and computationally efficient framework for debiasing behavioral intensity in industrial recommender systems using nonparametric contrastive percentile estimation. Its combination of practical architecture and empirical performance establishes a new paradigm for bias-corrected user modeling, with substantial implications for personalized, fair, and scalable recommendation at production scale (2605.21752).