- The paper introduces Mahjong, a framework that maps experts to GPUs by accounting for hardware variability, reducing mean latency by up to 16.5%.
- It leverages trace-driven profiling and iterative heuristic mapping to distinguish between consistently and temporally activated experts for optimal workload distribution.
- Experimental results show substantial improvements in tail latency and scalability with minimal profiling overhead, underscoring its practical impact on MoE inference.
GPU-Variability-Aware Expert-to-GPU Mapping for MoE Systems: The Mahjong Framework
Introduction and Motivation
Mixture-of-Expert (MoE) models have established themselves as a highly efficient alternative to dense transformer architectures for LLMs, leveraging conditional computation via a set of specialized "experts" such that only a subset are activated per token. This architectural design reduces per-token FLOPs and enhances throughput. However, MoE inference on multi-GPU systems introduces a synchronization bottleneck: at each layer, token processing proceeds in lockstep and the slowest ("straggler") GPU determines the end-to-end latency, severely impeding scalability and responsiveness.
Stragglers are caused not only by expert assignment imbalances but, critically, by inter-GPU performance variability. Even state-of-the-art GPUs show persistent throughput differences of up to 27.7% between fastest and slowest devices, due to process variation, power management, and runtime effects. Previous approaches to expert placement focus only on balancing token loads across GPUs and remain agnostic to this hardware variability, leading to suboptimal overall latency.
This paper introduces Mahjong, a framework for GPU-variability-aware Expert Mapping. Unlike prior token-balancing schemes, Mahjong profiles both expert utilization patterns and per-GPU performance characteristics, optimally mapping experts onto heterogeneous GPU resources to minimize wall-clock latency. Mahjong further distinguishes between consistently and temporally activated experts and ensures fine-grained separation of correlated workloads.
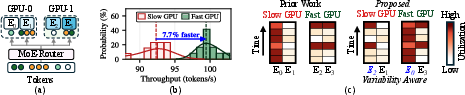
Figure 1: (a) MoE models assign experts to multiple GPUs, with a router determining expert activations. (b) GPUs demonstrate significant performance variability. (c) Mahjong places experts such that fast GPUs process more tokens proportionally, and highly-utilized experts are not placed on slower GPUs.
Characteristics and Implications of Expert Utilization and Hardware Variability
Empirical profiling with models such as Qwen3-235B reveals heavily non-uniform expert utilization, with the most active experts receiving up to 4.2× more tokens compared to others, an imbalance exacerbated by heterogeneous query distributions in real-world workloads.
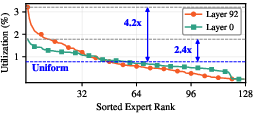
Figure 2: Expert utilization for Qwen3-235B's layers 0 and 92; expert activation rates differ markedly across layers and experts.
Simultaneous hardware profiling discovers persistent intra- and inter-node GPU throughput variability, with differences observed even within a single 8-GPU node over time and significantly larger spreads across clusters.
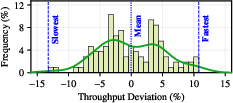
Figure 3: Distribution of throughput variation for DeepSeek-R1-Distill-Qwen-7B on 128 NVIDIA L40s; the fastest GPU outperforms the slowest by 27.7%.
Straggler effects are system-wide: even perfectly balanced token assignments still leave the slowest device as a bottleneck at every synchronization barrier.
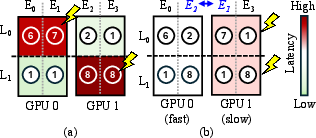
Figure 4: (a) Trivial expert allocation amplifies imbalances, creating stragglers. (b) Prior work attempts to redistribute experts, but does not account for GPU hardware non-uniformity.
Novelty and Algorithmic Design of Mahjong
Insights and Design Principles
Mahjong’s principal insights are twofold:
- Balance Per-GPU Latency, Not Token Load: Fast GPUs should process a proportionally larger share of tokens, calibrated to their measured throughput, enabling synchronous completion of MoE layers across devices.
- Identify and Disaggregate Consistent vs Temporal Experts: Some experts ("consistent") are regularly activated across time steps, while others ("temporal") are heavily used together but only in particular bursts. Placing correlated temporal experts or highly-used consistent experts on the same—or slow—GPU compounds straggler latency.
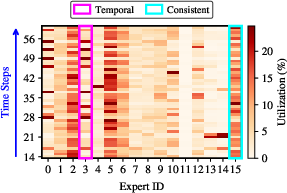
Figure 5: Per-step utilization patterns for Llama-4 Scout Layer-43; consistent experts activated in 85% of steps, temporal experts have clustered high activation.
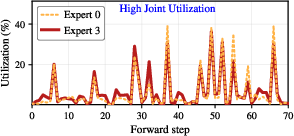
Figure 6: Correlation in activation patterns between temporal experts for Llama-4 Scout, revealing a Pearson correlation coefficient of 0.88 between certain expert pairs.
Implementation Pipeline
Mahjong composes a four-step pipeline:
- Expert Utilization Trace Collection: Profiling live inference traces to capture per-expert token activity patterns over sufficient time steps, discovering both consistent and temporal expert usage.
- Per-GPU Variability Profiling: Systematically benchmarking each GPU’s MoE-layer latency across a relevant range of token loads, using fine-grained sampling at tile boundaries to expedite this process.
- Heuristic Expert Mapping: Using iterative search (with multiple restarts to avoid local minima), Mahjong minimizes summed straggler latency over the trace by greedily swapping expert placements, guided by utilization and GPU latency profiles.
- Deployment: The finalized mapping is loaded into the MoE serving engine (e.g., vLLM), after which the router dispatches tokens to GPU-hosted experts according to the optimized plan.

Figure 7: Overview of Mahjong: (1) profile GPU variability, (2) capture expert utilization trace, (3) iterative mapping search, (4) deploy mapping for inference.
Iterative search refines placements by scoring mappings with:
S(M)=t∈T∑gmax(Cg(ng(M,t)))
where ng(M,t) is the token count on GPU g at time t for mapping M, and Cg the profiled latency curve.
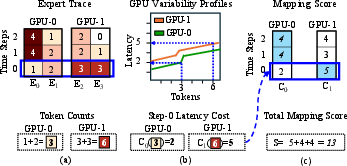
Figure 8: Mapping evaluation—token counts per expert and per GPU for a time step; per-GPU latency cost curves; mapping is scored as the sum of straggler costs across the trace.
Experimental Evaluation
Throughput and Tail Latency Analysis
Mahjong is evaluated across five modern MoE models (e.g., Mixtral-8x22B, Llama-4-Scout, Qwen3-30B-A3B) using real and technical inference workloads (ShareGPT, CodeContests) and varying levels of induced GPU throughput variability:
- End-to-end latency: Mahjong reduces mean request latency by 7.9% on average (up to 16.5%). Gains scale with hardware variability and expert-use skew. Wide and few-expert models (Mixtral-8x22B) benefit most; highly-uniform expert routing (Qwen3-30B-A3B) shows minimal gains.
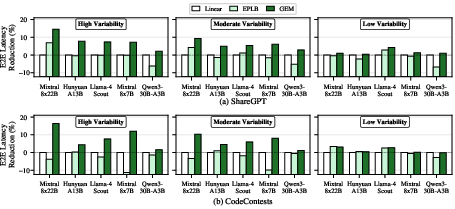
Figure 9: End-to-end latency reduction relative to linear mapping for five MoE models; greater improvement with higher hardware variability.
- p90 Time-Per-Output-Token (TPOT): Tail latency—critical for user-perceived responsiveness—yields even larger relative reductions (9.1% average p90 TPOT reduction, up to 16.9%).
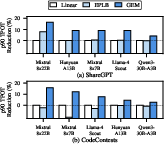
Figure 10: p90 TPOT latency reduction on high-variability hardware, demonstrating consistent reduction across models and datasets.
- Expert Mapping Policy Comparison: Visualization of per-time-step expert assignments confirms that only Mahjong disambiguates both consistent and correlated temporal experts, avoiding placement of heavily-utilized groups on straggler hardware.
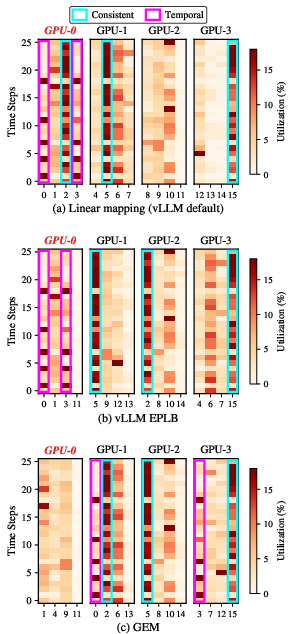
Figure 11: (a) Linear mapping co-locates consistent and correlated temporal experts on slowest GPU. (b) EPLB mitigates for consistent, not temporal, experts. (c) Mahjong distributes both types, minimizing straggler effects.
Profiling Overhead and Scalability
Mahjong's profiling overhead is negligible (<4 minutes per model), and its efficient sampling methods result in a 265–515× reduction in offline profiling time compared to token-by-token benchmarking.
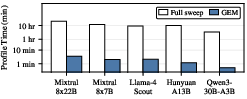
Figure 12: Mahjong reduces per-GPU variability profiling time by orders of magnitude vs full token sweeps.
Crucially, observed and extrapolated throughput distributions show the problem of GPU variability—and corresponding benefits of optimal expert mapping—scales disproportionally with larger multi-GPU deployments.
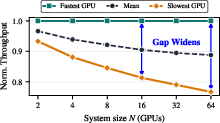
Figure 13: Expected slowest-to-fastest per-GPU throughput gap increases monotonically with system size N, exceeding 23% at N=64.
Implications and Future Prospects
Mahjong's variability-aware mapping framework establishes a necessary systems optimization for practical MoE serving at scale. Its approach is orthogonal to prior training-time routing/balancing strategies and can be integrated with recent advances in speculative and communication-optimal MoE serving (2605.19945). As LLM inference deployments grow to dozens or hundreds of GPUs per workload and deploy in dynamically variable cloud environments, accounting for hardware heterogeneity is essential to minimize latency stalls and maximize served throughput.
Practical implications include reduced user-perceived stall in interactive applications, more efficient cloud resource use, and compatibility with emerging MoE architectures and inference engine designs. Theoretically, Mahjong suggests future MoE scheduling and dispatch policies should jointly model hardware variability, expert utilization structure (including temporal correlation), and communication overheads.
Further research may explore dynamic mapping adjustment in response to online shifts in hardware state, improvements to expert routing itself under hardware/system constraints, or joint scheduling across multiple concurrent MoE workloads.
Conclusion
Mahjong presents a GPU-variability-aware, trace-driven expert placement framework for MoE model inference. By leveraging fine-grained hardware and workload profiling, and by explicitly modeling both consistent and temporally correlated expert activation, Mahjong achieves significant reductions in end-to-end and tail latency across diverse model and system scenarios. Its methodology and insights are increasingly pertinent as MoE architectures and deployment scales continue to grow.
Reference: "GEM: GPU-Variability-Aware Expert to GPU Mapping for MoE Systems" (2605.19945)

