- The paper introduces a data-centric approach using real images as anchors to construct preference pairs for improving diffusion model alignment.
- It employs a two-stage process—distributional warm-up and contrastive optimization—to enhance photographic realism and mitigate model artifacts.
- Experimental results show that fine-tuning with just 512 curated pairs matches the performance of methods using over 800K generated pairs.
Data-Centric Preference Alignment in Diffusion Models Using Real Data
Introduction
Preference alignment in text-to-image diffusion models conventionally depends on curated preference pairs derived from model-generated outputs. However, this paradigm is limited by the quality ceiling of the generations, the relativistic nature of pairwise supervision, and substantial annotation costs. The paper "When Preference Labels Fall Short: Aligning Diffusion Models from Real Data" (2605.19839) re-examines this framework, proposing a data-centric alternative that exploits real images as anchors for implicit preference supervision. Through systematic construction of real-image/perturbed-image pairs, the work introduces a methodologically robust approach that obviates reliance on manually annotated preference pairs, yielding highly competitive alignment performance.
Limitations of Existing Preference-Based Alignment
Traditional preference alignment collects pairs of generated images per prompt and relies on human-annotated binary comparisons. Even preferred samples in these datasets (e.g., Pick-a-Pic, HPDv2/3) are often plagued by artifacts or stylistic collapse, reflecting the intrinsic deficiencies of the generative models from which they are drawn. The relative supervision signal struggles to capture holistic image quality when both samples are imperfect and fails to reflect absolute human aesthetic preferences.

Figure 1: Preferred samples in human-annotated pairs still exhibit pronounced local or global visual deficiencies, highlighting failure modes in conventional preference-based pipelines.
Quantitative and qualitative analyses (Figure 2) further establish that preference and reward-based optimization often induce improvements along narrow visual axes (smoothness, stylization consistency) but may restrict overall realism, texture diversity, or compositional fidelity.
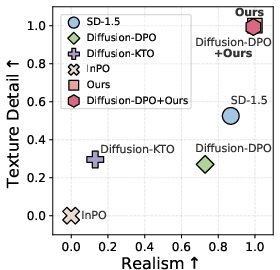
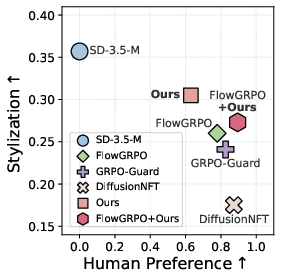
Figure 2: Optimization against pairwise preference or reward signals induces axis-specific gains (smoothness, stylization) at the expense of more balanced realism or texture improvement.
Framework for Real-Data-Based Preference Supervision
Construction of Preference Pairs with Real Data
The core contribution of the paper is a robust pipeline for automatic preference pair construction grounded in real data. Drawing on a curated subset of high-quality photographs from HPDv3, the method applies a salient region detection network (U²-Net) to extract visually critical regions and utilizes prompt-conditioned diffusion inpainting (e.g., SD-v1.5-Inpainting) to introduce controlled local degradations. The positive example is the original image; the negative is the inpainted (degraded) variant.

Figure 3: Red-marked salient regions undergo local degradation by inpainting, yielding interpretable negative examples and structurally meaningful preference pairs for alignment.
Preference supervision thereby emerges not from subjective manual labeling, but from explicit, interpretable discrepancies between curated real data and semantically/structurally disturbed perturbations.
Two-Stage Alignment: Distributional Warm-Up and Contrastive Preference Optimization
Alignment proceeds in two stages:
- Distributional Warm-Up: The base model is nudged toward the real image manifold with a distribution-level ranking loss (as in Diffusion-DRO), ensuring generated samples become statistically indistinguishable from real data under an online reward model. This step reduces the mode and quality mismatch between generations and real reference points, stabilizing the subsequent learning phase.
- Contrastive Preference Optimization: Standard DPO-based policy optimization is then performed using the constructed real/degraded pairs, refining fine-grained perceptual attributes by maximizing the likelihood of real samples relative to their degraded counterfactuals under a controlled KL-regularized policy shift.
Experimental Validation
Effectiveness and Data Efficiency
Fine-tuning both SD-1.5 and SD-3.5-M with only 512 real/degraded preference pairs yields performance that matches or exceeds Diffusion-DPO trained with >800,000 annotated model-generated pairs, as assessed by a suite of preference metrics (PickScore, ImageReward, UnifiedReward, HPSv3), perceptual quality (DeQA), and aesthetic (LAION) scores. Notably, these gains are consistent across evaluation sets (Pick-a-Pic v2, DrawBench, Parti-Prompts).
Human Evaluation
A user study—using direct head-to-head comparison between methods—shows a strong preference for the real-data-supervised model across several prompt domains and artistic genres.

Figure 4: Human raters favor outputs from real-data-aligned models versus both base and conventionally aligned SD-3.5-M models.
Complementarity with Existing Alignment Pipelines
When integrated as a post-training step on top of models already aligned by Diffusion-DPO or FlowGRPO, real-data-based supervision provides consistent additive improvements in preference and aesthetic metrics. This establishes the framework not only as a standalone alternative but as an augmentative module in alignment pipelines.
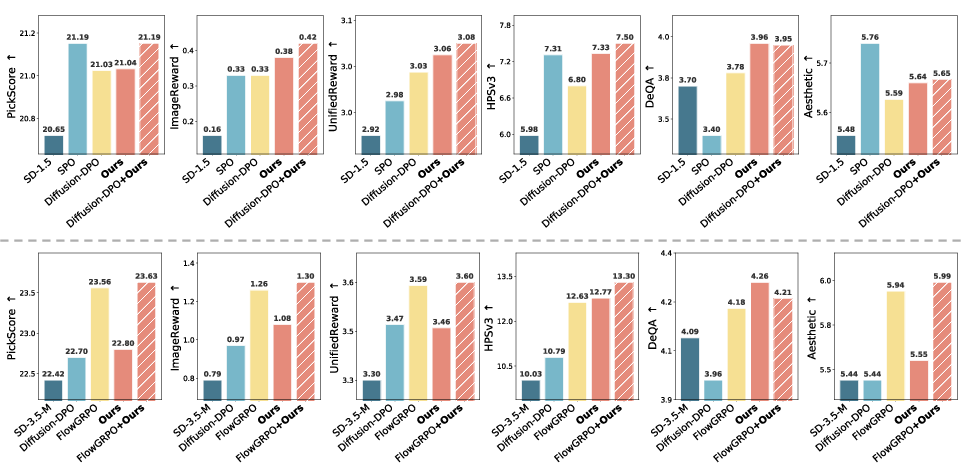
Figure 5: Real-data-based supervision yields systematic gains both as an independent signal and when applied following standard reward/preference model alignment, across models and datasets.

Figure 6: Qualitative examples on SD-1.5 showing superior texture and realism after post-training with real data; additive improvements observed when combined with Diffusion-DPO.

Figure 7: SD-3.5-M generations demonstrate enhanced color naturalism and lighting when using real-data post-training, alleviating mode collapse typical of pure reward-based pipelines.
Data and Perturbation Strategy Robustness
Performance gains persist regardless of the perturbation strategy (inpainting with various backbones or text-to-image generation using captions), and are robust to curation details (degree of filtering, scoring thresholds). Most gains are realized with hundreds of well-curated pairs; further scaling gives diminishing returns.
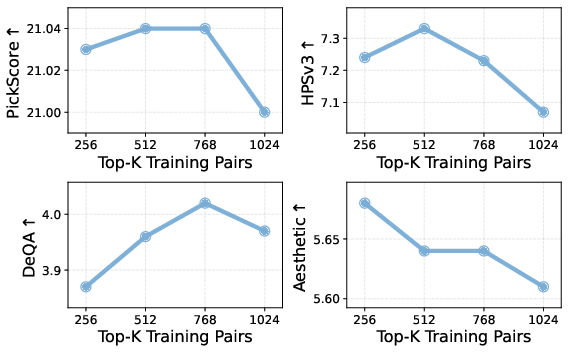
Figure 8: Performance saturates as the number of curated preference pairs increases, confirming high data efficiency of the approach.
Theoretical and Practical Implications
The data-centric approach reconceptualizes preference alignment from optimization over relative model outputs to direct estimation of the gap between a generative model’s distribution and the natural image manifold. Real images act as “anchors” for human aesthetic judgment, and the contrastive supervision highlights semantically meaningful departures from preferred domains. This reframing removes the ceiling imposed by model quality in the construction of preference pairs, is annotation-free, and reduces sensitivity to subjective bias or artifact-heavy supervision.
Practically, the method allows highly scalable alignment of diffusion models with minimal curation cost (on the order of dozens of GPU hours). The approach proves modular, complementary, and easily extensible—facilitating integration with existing reward- or preference-based fine-tuning procedures.
Future Directions
The framework’s data-centric construction is agnostic to modality—a logical next direction is extension to multi-modal, video, and cross-domain generative alignment. Further, more principled data selection beyond the simple colorfulness and quality filter can be explored to optimize the diversity and representativeness of the real-data anchors. Lastly, the approach is orthogonal to next-generation reward modeling or hybrid RLHF schemes and could be combined with stronger human-preference inference techniques.
Conclusion
This work establishes that real images are an effective, underexploited source of supervision for preference alignment in diffusion models, rendering large-scale manual annotation unnecessary and mitigating the artifact-bias intrinsic to model-generated preference pairs. The framework’s simplicity, robustness, and empirical efficacy underline its significance in building future data-driven, label-efficient, and human-centered generative models.