- The paper introduces the SP-CoR framework, a novel approach that integrates spectral energy sampling and physics-informed fusion for multi-robot cooperation.
- The study establishes the CoopSR benchmark with the EgoTeam dataset, featuring over 114K QA pairs to assess spatial, temporal, and coordination reasoning.
- Experimental results show SP-CoR outperforms baselines by up to 7.12%, demonstrating improved sim-to-real transfer and generalization in complex multi-robot settings.
Multi-Robot Cooperative Egocentric Spatial Reasoning with MLLMs: An Analysis of "Seeing Together"
Introduction
The problem of cooperative spatial reasoning in multi-robot embodied settings is fundamentally challenging due to partial, noisy, and distributed egocentric observations. The paper "Seeing Together: Multi-Robot Cooperative Egocentric Spatial Reasoning with Multimodal LLMs" (2605.18431) directly addresses this open challenge by establishing the CoopSR benchmark and proposing a new Multimodal LLM (MLLM) architecture, SP-CoR, explicitly designed for fine-grained reasoning across synchronized egocentric video streams from robot teams. The work represents a substantive advance in evaluating and modeling distributed cooperative perception, introducing new evaluation datasets, a systematic taxonomy, and a multi-stage architecture for physics and spectral-informed evidence integration.
Benchmark and Dataset Design: CoopSR and EgoTeam
A central contribution is the introduction of CoopSR, an evaluation benchmark for multi-robot cooperative visual question answering, accompanied by the large-scale EgoTeam dataset.
CoopSR systematically pushes cooperative reasoning capability beyond prior single-agent or EgoExo settings by requiring models to answer queries about spatial, temporal, visibility, and coordination aspects by aggregating observations from multiple synchronized robot-centric video streams.
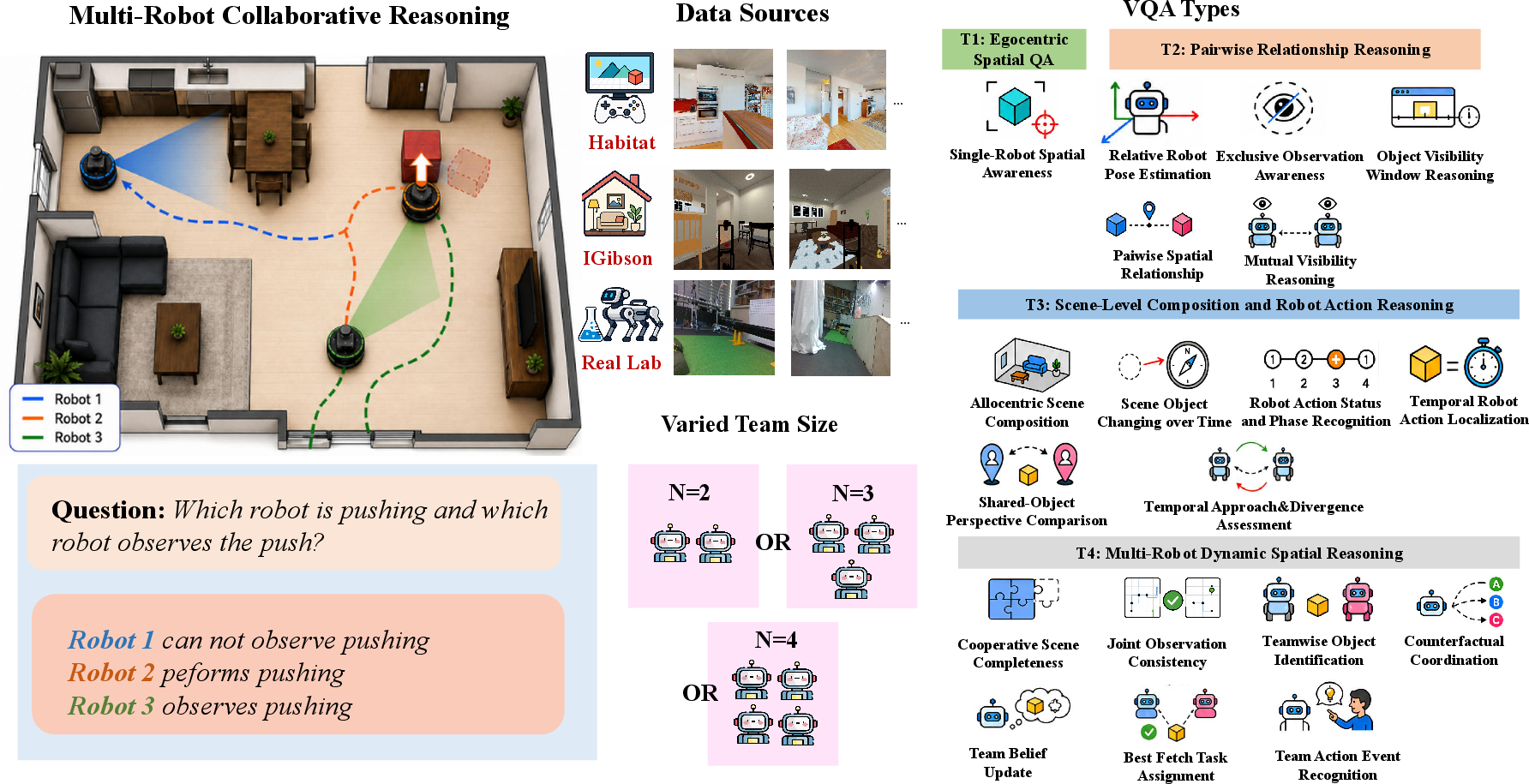
Figure 1: The CoopSR benchmark evaluates spatial, temporal, visibility, and coordination reasoning using synchronized egocentric views from variable-size robot teams in both simulation and real scenarios.
Key dataset design principles and properties include:
- Diversity and Scale: EgoTeam contains over 114K QA pairs, 19 question types, four difficulty tiers, and three team sizes (N=2,3,4), spanning both simulator (Habitat, iGibson) and real-world settings.
- Structured Reasoning Taxonomy: The questions are partitioned into levels (T1–T4), progressing from single-robot spatial queries to complex team-level scene, action, and coordination reasoning.
- Rich Metadata: Synchronized egocentric RGB-D video, semantic labels, ground-truth poses, relative spatial relations, and object interaction logs provide grounded annotations for precise QA generation.
- Manual Validation: Multi-step human review ensures reliability, correctness, and genuine requirement for cooperative perception.
This design enables both the modeling and quantitative evaluation of fundamental aspects like cross-view grounding, temporal event association, shared-object and team-level belief formation—beyond prior benchmarks which focus primarily on single-agent or limited exocentric relations.
MLLMs, when naively adapted for multi-agent settings, show significant performance degradation due to a lack of architectural inductive bias for agent identity, geometry, and cooperative fusion. To address these limitations, the paper proposes SP-CoR (Spectral and Physics-Informed Cooperative Reasoner), a modular MLLM framework with three core components:
Spectral Energy-Aware Multi-Robot Frame Sampling
Given the combinatoric explosion in visual tokens when processing N synchronized video streams, SP-CoR introduces a two-stage training-free selection procedure:
- CLIP-based Semantic Ranking: Each robot's frames are scored for query relevance using frozen CLIP embeddings. The top-M per-robot are retained.
- Spectral Temporal Energy Filtering: For each candidate, a discrete Fourier Transform is applied to CLIP feature windows to compute semantic motion energy, favoring temporally informative, dynamic frames (e.g., those reflecting robot or object actions rather than redundant static views).
This results in a query-attentive, temporally discriminative selection of per-robot evidence, maintaining tractability and focusing modeling on critical moments for downstream reasoning.
Rather than treating robot video as an unordered sequence, SP-CoR encodes each robot's state via:
- Visual feature statistics,
- Learned reliability estimates,
- Spectral (Fourier) temporal descriptors,
- Encodings of robot pose and motion.
These states are then fused using an attentional block that conditions robot evidence on joint physics and spectral state tokens. Final robot states are pooled into a team belief vector by reliability-weighted aggregation, explicitly reflecting team-level uncertainty and spatial configuration.
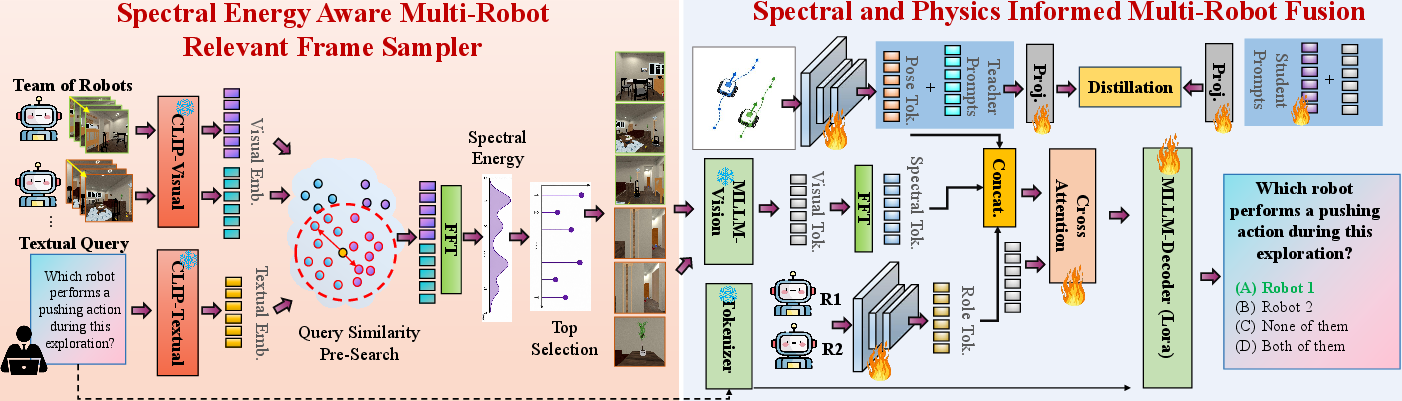
Figure 2: SP-CoR incorporates query-guided spectral energy sampling, spectral and physics-informed fusion, and physics-aligned prompt distillation for robust cooperative spatial reasoning.
Physics-Aligned Prompt-Space Distillation (PAPSD)
Physical priors (e.g., ground-truth poses, inter-robot geometry) are leveraged during training by a teacher-student paradigm. Teacher prompts encode privileged simulation data; student prompts are conditioned only on test-time observations. Distillation in prompt space encourages the student to recover latent structure necessary for physical reasoning at inference, yielding improved sample-efficiency and inference generalization without requiring privileged input post-deployment.
Experimental Results

Figure 3: Performances of several MLLMs on the real-world test set. Left: accuracy histograms; right: qualitative results.
Comparisons span 22 MLLM baselines—zero-shot, supervised fine-tuning (SFT), retrieval-augmented (RAG), and keyframe selection methods—across all configurations of CoopSR. Key findings include:
- Zero-Shot MLLMs achieve poor accuracies (31–42%), confirming the necessity of multi-robot explicit modeling.
- SFT improves performance substantially (Qwen2.5-VL-7B: 66.68% on Habitat), but accuracy drops with increased robot-team size, evidencing a lack of cooperative scaling.
- RAG and Keyframe Selection further improve evidence curation, but fail to model robot identity and cross-view relations explicitly.
- SP-CoR achieves the highest performance: 70.55% on Habitat and 70.82% on iGibson, outperforming strong baselines by +3.87% and +7.12% respectively. Gains are consistent across backbones and settings.
Ablations and Generalization
Comprehensive ablation studies individually disable each SP-CoR module. Removing spectral sampling, Fourier encoding, spectral-aware fusion, or prompt distillation all degrade accuracy, with fusion showing the largest drop in complex scenes. Importantly, SP-CoR also demonstrates superior generalization to larger team sizes (N=4) when trained on smaller (N=2,3), and outperforms on real-world benchmarks, indicating robust transfer beyond simulation.
Further, robot dropout experiments highlight the genuine need for multi-robot, not single-view, integration; performance collapses when input from one robot stream is removed, confirming that CoopSR tasks probe true cooperative reasoning.
Implications and Future Directions
Practically, this work charts a pathway to robust, team-level embodied AI capable of distributed situation awareness for domains like warehouse automation, search and rescue, and smart infrastructure. By demonstrating improved sim-to-real transfer and handling diverse robot team sizes, SP-CoR forms a practical foundation for scalable deployed systems.
From a theoretical perspective, the results evidence that physically and spectrally grounded architectural inductive biases are essential for surpassing the limitations of general-purpose MLLMs in embodied multi-agent settings. The demonstration that prompt-space distillation can transfer privileged geometric knowledge efficiently suggests new research directions in knowledge transfer under partial observability.
Future developments may include:
- Extending the benchmark and real-world evaluation to larger, more heterogeneous multi-agent settings.
- Integrating explicit communication and coordination strategies.
- Exploring end-to-end differentiable fusion architectures that tightly couple perception, language, and control.
- Addressing privacy, safety, and robustness implications for deployment in open environments.
Conclusion
The "Seeing Together" paper establishes a rigorous empirical and architectural foundation for cooperative egocentric spatial reasoning with MLLMs. The introduction of the CoopSR benchmark and the SP-CoR framework marks a significant advance in unified evaluation and modeling for multi-robot embodied intelligence. Results underscore the necessity for physically and spectrally driven evidence selection and fusion. The work lays the groundwork for both practical deployment of collaborative robot teams and further research at the intersection of embodied perception, multimodal language modeling, and cooperative AI.