Double/Debiased Machine Learning for Continuous Treatment Effects in Panel Data with Endogeneity
Published 18 May 2026 in stat.ME | (2605.17910v1)
Abstract: We propose a double/debiased machine learning framework to estimate average derivative effects in nonparametric panel models with two-way fixed effects. It extends instrumental variable methods to panel settings, handles continuous treatments and various forms of endogeneity, and introduces a cross-fitting scheme to restore independence after eliminating time fixed effects. A penalized GMM debiasing term enables automatic debiased machine learning with endogeneity. Our estimators for contemporaneous, dynamic, and aggregated effects are consistent and asymptotically normal with a valid variance estimator. Simulations show reduced regularization bias and accurate confidence intervals. An application to ECLS-K data reveals rich dynamics in the effect of family SES on childhood BMI.
The paper introduces a novel DML framework that debiases nonparametric panel estimators to handle TWFE and continuous treatments with endogenous regressors.
It employs penalized GMM and innovative cross-fitting techniques to reduce bias and improve variance estimation, as demonstrated through extensive simulations.
Empirical applications using ECLS-K data reveal dynamic SES effects on childhood BMI, highlighting temporal sign reversals and robust causal inference.
Debiased Machine Learning for Continuous Treatment Effects in Panel Data with Endogeneity
Motivation and Background
Panel data models with continuous, time-varying treatments, non-strict exogeneity, and both individual and time fixed effects require robust estimation tools capable of handling high-dimensional structural functions and various sources of endogeneity. Traditional instrumental variable and panel estimation methods—including those for two-way fixed effects (TWFE)—are limited in their flexibility, often constrained to linear or partially linear models, or unable to adequately handle endogeneity when dynamic components or lagged outcomes are present.
The double/debiased machine learning (DML) framework addresses these requirements by leveraging machine learning methods to flexibly estimate high-dimensional structural functions, while utilizing orthogonalization and cross-fitting to mitigate regularization and overfitting bias. Although DML has been applied to panel models with individual effects, prior work does not address the combination of TWFE and endogeneity, especially in nonparametric settings. This paper fills that gap by systematically extending DML to handle nonparametric panels with endogenous regressors and TWFE, developing new debiasing techniques and cross-fitting schemes suitable for this complex setting (2605.17910).
Framework and Estimation Procedures
Model Structure
The authors formalize static and dynamic nonparametric panel models encompassing additive TWFE:
Static Model:Yit=γ0(Xi,t−q:t,Di,t−q:t,Ci)+μi+λt+εit, with sequential or complete endogeneity in covariates, and instrument sets Iit.
Treatment effects are defined as average derivatives: θ0t(s)=E[∂Di,t−s∂Yit], with aggregated estimands as weighted averages.
Debiasing Procedure
The estimation procedure proceeds as follows:
Fixed Effect Elimination: TWFE are removed via sequential differencing and cross-sectional demeaning in cross-fitting folds, restoring the independence necessary for valid inference.
Machine Learning for Structural Function: Flexible ML (e.g., penalized GMM, DeepIV) estimates the differenced structural function, mitigating the ill-posed nature of nonparametric instrumental variable regression.
Orthogonalization: Construction of Neyman orthogonal moment conditions via explicit debiasing terms based on the Gateaux derivative properties of the moment conditions.
Estimation of Debiasing Term: The Riesz representer, which does not have closed-form, is estimated via penalized GMM—extending Auto-DML approaches to the endogenous, high-dimensional panel setting.
Cross-Fitting Algorithm: A novel scheme splits the panel along both time and individual axes, leveraging additional folds for demeaning and function estimation, thus avoiding the spurious correlation introduced by standard demeaning.
Asymptotic Theory
Rigorous asymptotic results are established:
Convergence Rate: Penalized GMM estimator for the debiasing component achieves Op(r2εN−2/(2ξ+1)) under mild conditions on sieve approximation and sparse eigenvalues.
Inference: The debiased estimator is N-consistent and asymptotically normal, with consistent variance estimation.
Simulation Results
Extensive Monte Carlo experiments demonstrate:
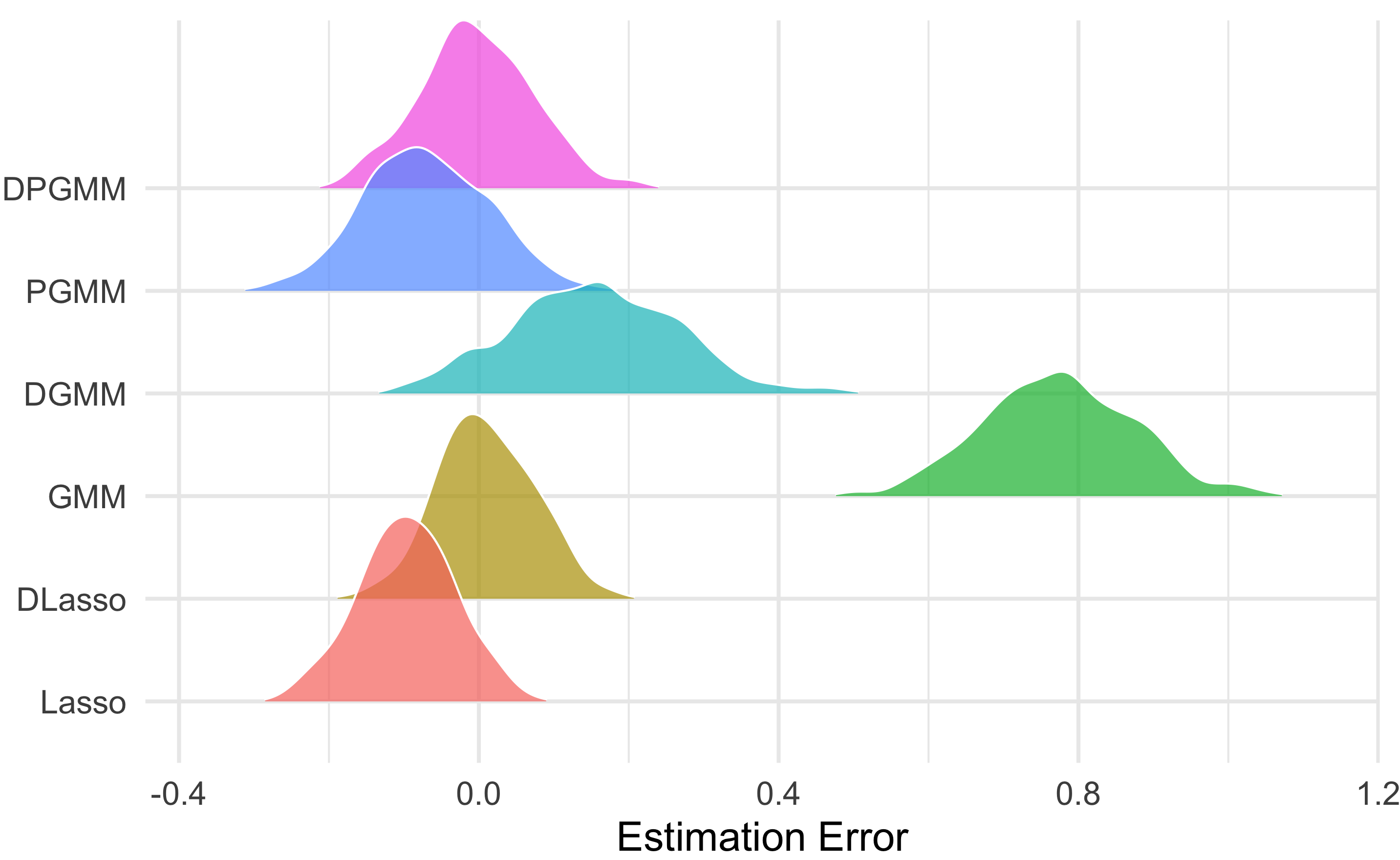
Bias Reduction: The debiased estimator (DPGMM) eliminates nearly all bias and achieves the lowest MSE relative to plug-in or naive ML estimators, even under severe misspecification or when endogeneity is ignored.
Variance Estimation: The estimator for asymptotic variance is accurate; confidence interval coverage closely matches nominal levels.
Robustness: Debiasing consistently improves performance for various first-stage estimators, covariate dimensions, and sample sizes.
Figure 1: Distributions of the estimation errors of the estimators, showing tighter concentration and near-normality for debiased methods.
Empirical Application
The framework is applied to the Early Childhood Longitudinal Survey, Kindergarten Cohort (ECLS-K):
Treatment Variables: Family SES, household size, fast food price index.
Outcome: Childhood BMI across six periods.
Specification: Both static and dynamic TWFE panel models, estimating contemporaneous and lagged effects via flexible dictionaries and cross-fitting.
Key empirical findings:
Temporal Dynamics: The contemporaneous SES effect on BMI exhibits sign reversal, with negative coefficients early and positive later—explaining contradictory findings in previous literature.
Effect Magnitudes: SES consistently exerts the strongest influence; household size is only transiently significant; fast food price effects are weakest and mostly insignificant in dynamic specifications.
Robustness: Results are stable across specification choices, indicating the model's reliability.
Implications and Future Directions
Practical Implications
Debiasing ML Estimators in Panels: The penalized GMM-based estimation for the debiasing term and the specialized cross-fitting restore valid inference in settings where standard panel and ML methods fail due to high-dimensionality and endogeneity.
Causal Inference with Continuous Treatments: The framework allows researchers to estimate marginal effects of continuously varying treatments—both current and historical—while accounting for dynamic treatment heterogeneity.
Resolution of Temporal Aggregation Pitfalls: Period-specific effect estimation avoids averaging artifacts, offering more granular insight into policy-relevant dynamics.
Theoretical Significance
Generalization of DML: Extends DML theory to accommodate TWFE and endogenous regressors in nonparametric panel models, overcoming previously unresolved technical barriers.
Robust Variance Estimation: Provides reusable inferential tools for settings beyond the immediate context, including complex panels and longitudinal studies.
Speculation on Future Developments
Panel Regimes with (N,T)→∞: Further theoretical work to generalize asymptotic results in panels with large T would be required to address incidental parameter problems.
Alternative Identification Strategies: Automatic debiasing for panel data under parallel trends or proxy variables could open new avenues for ML-based panel causal inference.
Integration with General ML Architectures: Frameworks such as neural nets and boosting could be adapted using the penalized GMM debiasing structure to advance nonparametric panel methodologies.
Conclusion
This paper develops a comprehensive DML framework supporting valid inference for continuous treatment effects in panel data with TWFE and endogeneity, furthering both theoretical and empirical causal panel analysis. The rigorous asymptotic results, robust empirical and simulation evidence, and methodological innovations—especially the penalized GMM debiasing and novel cross-fitting—mark a substantive contribution to econometric and statistical learning for panel causal inference. Extensions to regimes with large T, and identification without credible instruments, remain open research problems.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.