- The paper shows that standard text encoders maintain high performance under truncation up to 70-80%, questioning the necessity of MRL for moderate compression.
- It demonstrates through comprehensive experiments on retrieval and classification tasks that MRL only offers benefits under extreme truncation (≥80%), especially in smaller models.
- The study reveals that MRL induces higher variance in lower embedding dimensions, indicating trade-offs between computational cost and embedding efficiency.
Robustness of Text Embedding Truncation: Revisiting Matryoshka Representation Learning
Introduction and Motivation
The pursuit of storage- and compute-efficient text representations underpins several practical and large-scale NLP applications such as document retrieval and recommendation. Matryoshka Representation Learning (MRL) has become a prevalent training paradigm, enabling text encoder models to yield embeddable feature vectors at multiple, predetermined dimensionalities by truncation. The core hypothesis is that by explicitly optimizing for truncated embeddings, models achieve higher robustness to dimensionality reduction, especially under aggressive compression regimes. However, the actual necessity and marginal utility of MRL — in light of empirical evidence suggesting strong robustness of non-MRL models to random truncation — has not been systematically evaluated. This work rigorously benchmarks MRL against random truncation on diverse models and tasks, examining the extent to which robustness to dimensionality reduction is an artifact of training (and specifically MRL), or an intrinsic property of modern text encoders.
Comprehensive Experimental Evaluation
The methodology involves two distinct comparative settings: benchmarking existing open-weight models (both with and without MRL) and controlled experiments where the only variable is the use of MRL in otherwise identical training configurations.
Open Model Benchmark
A suite of eight prominent text encoders — four “smaller” (∼400–500M parameters) and four “larger” (∼4B parameters) — are systematically evaluated on retrieval (NanoBEIR) and classification (MTEB) tasks. Embeddings are truncated at discrete pre-specified intervals, both within and outside the original MRL training set of dimensions, and their downstream performance measured relative to the untruncated embeddings.
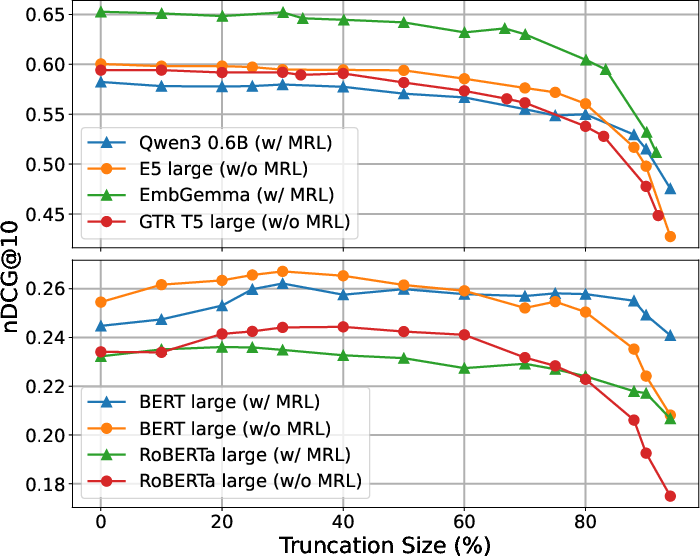
Figure 1: Truncation robustness of open text encoders with and without MRL shows no significant difference except at extreme (≥80%) truncation.
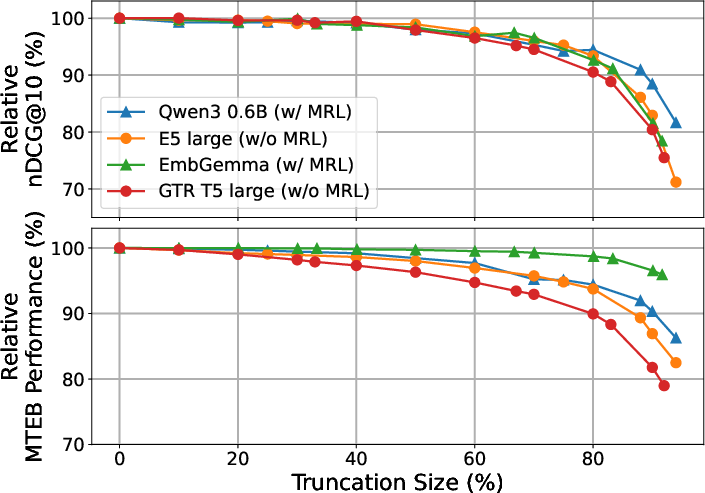
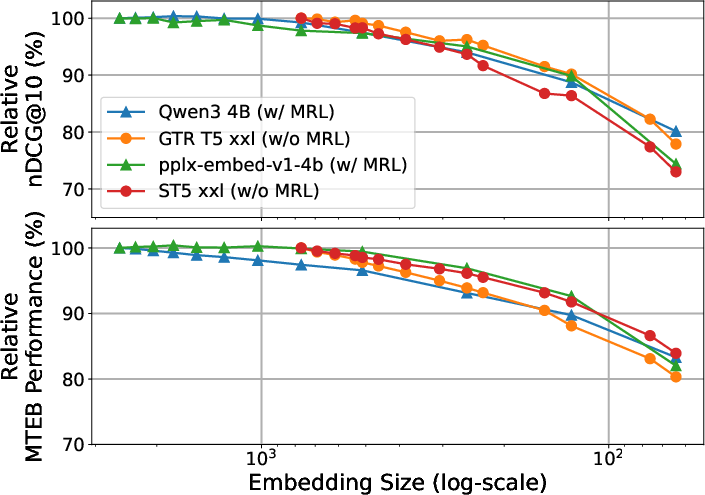
Figure 2: Relative robustness of smaller models (∼400M parameters) as embedding size is reduced.
The empirical findings demonstrate that across all baseline models — regardless of MRL intervention — embedding truncation up to approximately 70-80% of the original dimensionality incurs minimal performance degradation for both retrieval and classification. Only under severe size reduction (≥80% truncated) does MRL offer perceptible benefit, and even then, primarily in smaller models or certain domains.
Controlled Training Experiments
To isolate the effect of MRL, the authors fine-tune pairs of encoder architectures (BERT, RoBERTa in base and large sizes; T5 base encoder) under a contrastive objective, once with standard contrastive loss and once with an MRL-augmented objective. Training and validation are kept constant (SNLI+MultiNLI), with convergence verified.
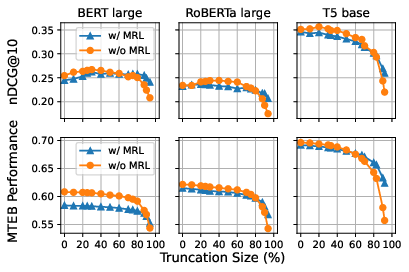
Figure 3: Downstream benchmark performance of encoder pairs trained with and without MRL; non-MRL models consistently outperform until heavy truncation.
Across all architectures and benchmarks, randomly truncated non-MRL models equal or surpass their MRL-trained counterparts in downstream accuracy up to the 80% truncation threshold, after which performance for non-MRL models degrades more sharply. This result directly refutes any blanket claim that MRL universally enhances robustness at all truncation levels.
Structural and Statistical Insights
Further analysis explores the distribution of information across embedding dimensions. MRL-trained models display increased variance in the lower dimensions relative to non-MRL baselines, as measured by standard deviation across encoded text batches.
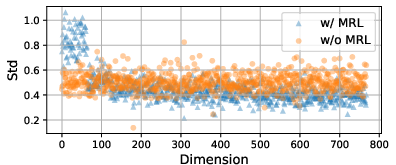
Figure 4: Standard deviation across embedding dimensions for BERT base with/without MRL; MRL injects higher variance in the lowest dimensions.
This phenomenon indicates that MRL induces a form of information packing or compression into the truncated (typically lower) subspaces, directly supporting its utility under heavy truncation scenarios. However, outside these high-compression regimes, this property may be redundant or even interfere with optimal performance on less heavily truncated embeddings.
Numerical Results and Robustness Patterns
Consistent trends are observed in both absolute and relative performance metrics across datasets and model sizes, reinforcing the central claim. In both NanoBEIR and MTEB, larger encoder models naturally exhibit smoother degradation under truncation — a further argument against the necessity of MRL except in the most aggressive compression settings.
Additional supporting results can be found in aggregate and per-dataset analyses:
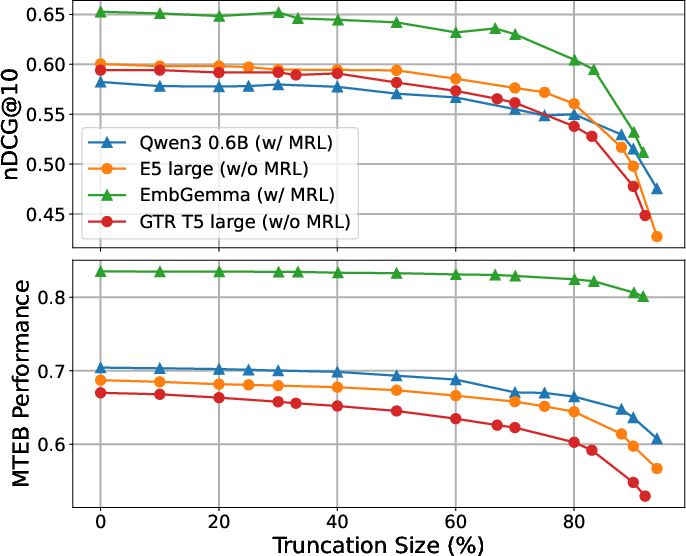
Figure 5: Absolute performance of smaller models at varying truncation levels.
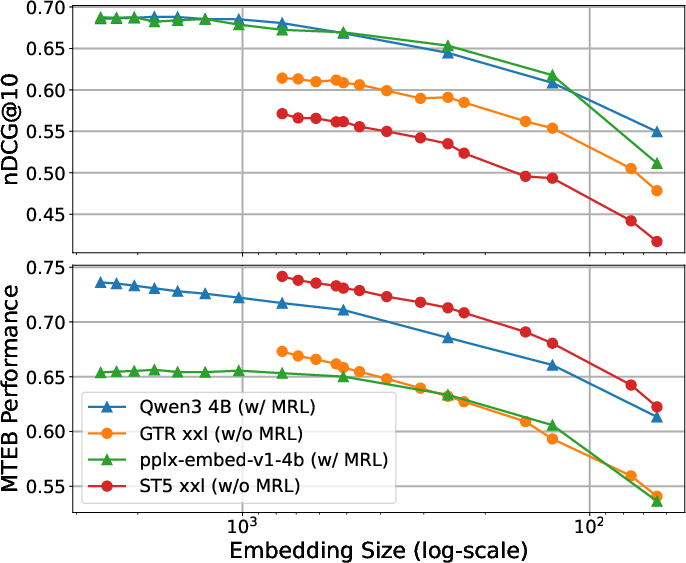
Figure 6: Absolute performance of larger models at varying truncation levels.
Theoretical and Practical Implications
The findings cast doubt on the general efficacy of allocating model and training complexity to MRL when moderate dimensionality reductions suffice. The robustness of modern (contrastively trained) embeddings to simple deterministic truncation suggests an inherent efficiency in current representation learning objectives and architectures. MRL’s benefit is confined to extreme dimensionality constraints, as might be crucial for edge deployment or high-volume query scenarios. The implication is that MRL should only be considered when targeting vector size reductions above 80%, or where predictable compression points are crucial.
Compression strategies that rely solely on random truncation retain higher overall downstream efficacy across a wide truncation spectrum and avoid the computational/tuning overheads associated with MRL training, provided heavy truncation is not required.
Beyond practical model deployment, this challenges the assumption that information is evenly or usefully distributed across dimension order in MRL-trained models, and raises the possibility of hybrid approaches or novel objectives that promote more uniform information distribution across all dimensions.
Future Directions
Potential research avenues include:
- Designing new objectives that promote robust, truncation-insensitive embeddings across a flexible range of dimensionalities, not just those predetermined at training time.
- Extending controlled experiments to larger-scale models and more diverse training datasets to generalize the findings.
- Exploring regularization or architectural interventions that achieve the perceived information compaction of MRL without the drawbacks observed at moderate truncation levels.
Additionally, understanding whether increasing lower-dimension variance (as induced by MRL) can be beneficial for other downstream properties — e.g., interpretability, transfer, or task-specific adaptation — remains an open question.
Conclusion
This work demonstrates that text embedding models, when trained with standard contrastive objectives, are robust to truncation up to substantial levels, obviating the need for Matryoshka Representation Learning except under scenarios of very high (≥80%) dimensionality reduction. The empirical evidence is robust across model sizes, tasks, and architectures.
Only under severe compression does MRL's induced information compaction in lower embedding dimensions confer measurable advantages. For most practical scenarios, especially those requiring moderate compression, random or deterministic truncation of non-MRL embeddings achieves competitive or superior results. These findings suggest that research on embedding compression might more productively focus on general-purpose robustness and efficient truncation strategies beyond the MRL paradigm, and motivate new approaches to embedding design under resource constraints.
(2605.16608)

