Published 15 May 2026 in cs.AI and cs.LG | (2605.15960v1)
Abstract: We propose a novel definition of model exploitation in reinforcement learning. Informally, a world model is exploitable if it implies that one policy should be strictly preferred over another while the environment's true transition model implies the reverse. We analogize our definition with a prior characterization of reward hacking but show that the associated proof of inevitability does not transfer to exploitation. To overcome this obstruction, we develop a general theory of reward hacking and model exploitation that proves that exploitation is essentially unavoidable on large policy sets and yields the corresponding claim for hacking as a special case. Unfortunately, we also find that the conditions that guarantee unhackability in finite policy sets have no counterpart that precludes exploitation. Consequently, we introduce a relaxed notion of exploitation and derive a safe horizon within which it can be avoided. Taken together, our results establish a formal bridge between reward hacking and model exploitation and elucidate the limits of safe planning in world models.
The paper demonstrates that model exploitation arises from value inversions in policy rankings between distinct transition models.
It employs gradient analysis and analytic methods to prove that non-equivalent models are inherently exploitable in rich policy spaces.
The findings imply that safe planning in model-based RL requires either reducing the planning horizon or improving model accuracy to mitigate exploitation.
Ordinal Safety in Model-Based Reinforcement Learning: Analysis of "Imperfect World Models are Exploitable" (2605.15960)
Introduction
This work provides a rigorous theoretical analysis of model exploitation in reinforcement learning (RL), focusing on the inherent limitations of planning with imperfect world models. The authors propose an ordinal (policy-ordering) notion of safety for world models, contrast exploitability with reward hacking, and develop a unified theory describing when model exploitation is inevitable. The findings systematically delineate the boundary between safe and unsafe model-based planning, introducing formal results on the (un)avoidability of policy-order reversals across transition models and connecting these concepts to practical criteria regarding the planning horizon, model accuracy, and policy space. This essay summarizes and contextualizes the main contributions, technical results, and implications for future research.
Formalizing Model Exploitation and its Relationship to Reward Hacking
The key conceptual advance is the introduction of a new definition of model exploitation as a value inversion in policy rankings between two transition models: given a fixed reward function, a pair of models is exploitable if there exists a pair of policies such that the models disagree in their strict ordering over value. This contrasts with reward hacking (inversion between two reward functions for a fixed model), as studied by Skalse et al. (2022). Model exploitation generalizes the notion of unsafe optimization when the planning model diverges from the true environment, formalizing the failure mode where optimization yields a policy preferred under the learned model but dispreferred under reality.
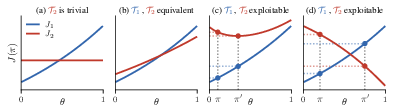
Figure 1: Taxonomy of possible relationships between transition models in a 3-state MDP, highlighting cases of equivalence, triviality, and exploitation via policy ranking inversions.
An important distinction argued here is that, unlike reward functions (which inhabit a linear space), transition models live on a product of probability simplices and induce values that are non-linear and less tractable, leading to fundamentally richer geometric properties for policy evaluation. The paper rigorously demonstrates that many results known for reward hacking do not transfer to model exploitation, identifying both the limitations of linear analytic tools and the failure of reward-hacking unhackability results to apply in model classes.
Unavoidability of Exploitability in Large Policy Spaces
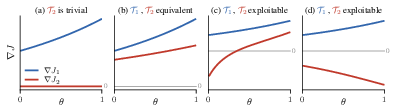
A central technical contribution is the proof that, on any sufficiently rich (open) policy set, every non-trivial, non-equivalent pair of transition models is inevitably exploitable: it is always possible to find policies whose ordinal value ranking is inverted between the two models. This result is established by constructing value function gradients and invoking properties of real-analytic and rational functions on policy space. Specifically, the analysis shows that whenever the gradients of the value functions under the two models are not positively proportional throughout some open subset of policy space, an exploiting pair of policies (i.e., a value inversion) can be constructed.
Figure 2: Value gradients under different transition model pairs demonstrate conditions for equivalence (proportional gradients) and exploitation (opposite-sign gradients) across policy space.
The formal theorem asserts that in policy spaces containing an open subset—such as full stochastic, ε-suboptimal, or δ-deterministic policy classes—non-trivial non-equivalent world models can always be exploited (Corollary: Imperfect world models are exploitable). In sharp contrast, for reward hacking, unhackability is guaranteed for any finite policy set under mild regularity conditions; such a guarantee fails for transition models due to their richer geometry and the inability to escape exploitability except in low-dimensional, highly restricted policy sets. The paper further provides explicit constructions and counterexamples to show that even with finite policy sets and non-collinear visitations, there is no universal guarantee of unexploitability.
Unification and Technical Generalization
A unification of model exploitation and reward hacking is obtained by showing that any instance of exploitability between transition models can be reduced to an instance of reward hacking. This reduction is constructed via the mapping of policy-induced discounted visitation distributions to reward functions, ensuring that the existence of a value inversion under models implies a corresponding inversion under rewards. However, the converse is not true: hackability between rewards does not entail exploitability between models.
The use of rationality and analyticity of the value function—proved via properties of the Bellman equation and homeomorphisms in policy space—enables the authors to package both hacking and exploitation into a single geometric framework based on gradient analysis and level set topology. Lemmas establish that negatively correlated gradients between value functions always produce an exploiting policy pair, while positively proportional gradients ensure equivalence of the induced rankings.
Relaxation: ε-Exploitability and the Safe Planning Horizon
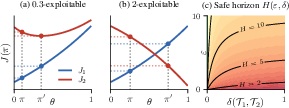
The binary notion of exploitability is recognized as overly rigid for practical purposes. The authors therefore generalize to ε-exploitability, quantifying the magnitude of value inversions. Using a tight form of the simulation lemma, they derive a safe horizon function H(ε,δ) characterizing the maximal effective planning horizon for which ε-unexploitability is guaranteed, given the maximal per-state total variation distanceδ between models:
H(ε,δ)=2(1+ε)+(1−ε)2+4ε/δ
If the effective planning horizon 1/(1−γ) is less than H(ε,δ), no policy pair will induce an inversion exceeding δ0 in value.
Figure 3: Illustration of δ1-exploitable policy pairs and the contour of the safe horizon δ2 as a function of tolerance and model divergence.
This formalizes and quantifies the intuition from prior empirical studies that imperfect models should not be trusted for long-horizon planning, and provides a principled guideline for limiting planning depth as a function of model mismatch and the tolerable error in ordinal value. The bound is proven tight and is shown to subsume and extend earlier model-based RL results on compounding error and planner overfitting risk.
Implications and Prospects for Model-Based RL
The implications for model-based and world model RL are substantial. The identification of irrevocable exploitability in policy-rich settings raises fundamental concerns about the safety of optimizing under any imperfect world model, regardless of the predictive accuracy on held-out trajectories. This result demands a shift from measuring model quality merely in terms of cardinal prediction error to an explicit consideration of ordinal safety—i.e., the preservation of policy rankings. The tight safe horizon bound concretely links model discrepancy, planning horizon, and practical safety: successful large-horizon planning in complex domains mandates highly accurate models, or, absent this, principled regularization by reducing the planning depth.
(Figure 1), (Figure 2), and (Figure 3) collectively illustrate the taxonomy of model relationships, the mechanism by which exploitability emerges via gradient opposition, and the empirical relationship between model divergence, planning horizon, and safety.
Furthermore, relaxing to δ3-exploitability opens the door to quantitative metrics for the robustness of policy synthesis from models. An immediate implication is that model-based methods should dynamically adjust planning horizon according to estimated model error, corroborating previous empirical advice (e.g., [jiang2015dependence]), but now justified at the level of value-inversion safety.
From a theoretical standpoint, the key open question raised is whether any simple, necessary, and sufficient conditions for unexploitability can exist on finite (possibly structured) policy sets—a direction that appears fraught due to the geometric nonlinearity revealed by this work.
Conclusion
"Imperfect World Models are Exploitable" (2605.15960) rigorously establishes the inevitability of policy-order reversals between world models in any sufficiently rich policy class, sharply contrasting with the corresponding reward-hacking results and exposing hard limitations for model-based RL safety. By introducing an ordinal notion of exploitability, reducing it to reward hacking, and quantifying the precise horizon limits for safe planning with imperfect models, the paper offers a crucial theoretical foundation for both the critique and improvement of model-based decision-making systems. Future research will need to grapple with finite and structured policy spaces, continuous domains, and more granular metrics for exploitability. Practically, the findings necessitate a deeper integration of ordinal safety criteria and dynamic horizon adaptation in the design of safe, robust world model-based RL systems.