- The paper introduces continued pre-training (LongPT) to extend LVLM context from 32K to 128K tokens, achieving a 7.1% absolute improvement in VQA scores.
- It leverages a long-document VQA synthesis pipeline and a balanced extraction-to-reasoning ratio to enhance retrieval and multimodal reasoning capabilities.
- The approach preserves short-context performance while generalizing robustly across diverse tasks and even operating beyond its training context window.
Effective Training of Long-Context Vision-LLMs with Generalization Beyond 128K Context
Introduction
Scaling large vision-LLMs (LVLMs) to handle long multimodal contexts is key for enabling advanced applications such as long-document understanding, extended video analysis, and agentic workflows that require persistent context management. The methodological core of this study is a systematic investigation into continued pre-training (“LongPT”) for extending the context window of an open-weight LVLM (Qwen2.5-VL-7B) from 32K to 128K tokens, aiming to delineate how data composition, mixture strategy, and training protocols affect long-context generalization.
Design and Curation of Long-Context Multimodal Data
Document Pool and Token-Length Distribution
The success of long-context capability in LVLMs critically depends on constructing and curating large-scale, diverse, high-fidelity multimodal document pools. The pool used here comprises over 1.5 million PDF documents, spanning numerous domains such as science, engineering, and the social sciences. The domain distribution is illustrated in Figure 1.
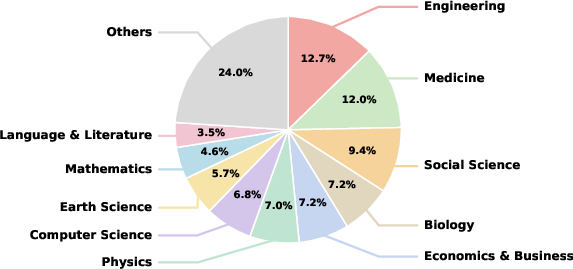
Figure 1: The document domain distribution of the document pool used for data synthesis.
These documents are rendered into images and parsed using an OCR expert model that produces fine-grained, layout-aware blocks, facilitating granular and structure-aware downstream data synthesis.
Long-Document VQA Synthesis Pipeline
The authors identify long-document visual question-answering (VQA) as a superior data synthesis strategy relative to dense OCR transcription. The long-document VQA pipeline takes document segments (8–15 pages), generates targeted QA pairs using an LVLM (with evidence page annotation), and embeds the QA back in the full document context, creating instances where answer evidence is localized but retrieval requires global context scanning.
The distribution of the VQA training data in the pool-native setup is detailed in Figure 2.
Figure 2: Long-document VQA data in the pool-native distribution with lengths spanning 32K–128K tokens.
Three VQA task classes are synthesized: (i) single-page extraction, (ii) multi-page extraction, and (iii) reasoning, with the latter requiring non-trivial aggregation or computation across multiple pages or document modalities.
Comparison of Supervision Sources
Direct comparison demonstrates that long-document VQA supervision leads to substantially higher downstream VQA performance than OCR transcription, even when the latter is followed by short-context SFT. The instruction-formatted, evidence-localized, and task-diverse signals in VQA enable large retrieval and reasoning gains, and, critically, show that high-quality long-context data can preserve short-context capabilities even in the absence of explicit short-context mixing.
Training Methodology
The model is extended to 128K using the Dynamic-NTK approach for scaling RoPE base frequency and trained under a fixed 5B-token budget. Experiments focus on three axes:
Sequence-Length Distribution
A key finding is that balanced, naturally occurring (“pool-native”) sequence length distributions outperform long-biased distributions where the majority of sequences are near the upper context bound (≥100K tokens). Empirically, generalizability across arbitrary lengths and positions is superior, with pool-native sampling yielding up to 1.7 points higher VQA scores in some settings.
Multi-Task Long-Context Mixtures
Grid search over extraction-to-reasoning ratios reveals that moderately extraction-heavy balancing (8:2 extraction to reasoning) produces optimal long-context performance. This supports the claim that key-information retrieval, not purely complex reasoning, is the limiting factor for long-context LVLMs, but modest reasoning data is necessary to provide regularization and avoid overfitting to pure retrieval.
Short-Context Data Mixing
Contrary to practices in LLM long-context pre-training, ablations show that pure long-document VQA training preserves short-context skills with negligible performance degradation (∼1 point drop on short-context benchmarks), given that the data itself is instruction-following and diverse.
Empirical Results
Long-Document VQA
The final recipe yields 7.1% absolute improvement over the Qwen2.5-VL-7B baseline (from 50.59 to 57.70 average VQA score) in the 64K–128K range, outperforming open-source LVLMs up to 14B parameters and rivaling some 32–72B models. Notably, the model generalizes beyond its training context window, with only mild performance decay at 256K and 512K contexts (retaining over 52% macro-average scores at 512K, compared to baseline collapse).
Generalization to Diverse Multimodal Long-Context Tasks
The model demonstrates robust transfer to various evaluation settings:
- On the MM-NIAH benchmark (webpage-based multimodal needle retrieval), average performance more than doubles the 7B baseline (from 20.0 to 49.4 at 128K).
- On VTCBench (long-context vision-text compression), overall scores jump by nearly 5 points, with improvements in reasoning and memory under compressed contexts.
- For long-video understanding (Video-MME, MLVU, LongVideoBench), the approach yields consistent gains over strong baselines without using video-specific data.
Practical and Theoretical Implications
This work provides a data-efficient blueprint for extending LVLM context beyond 128K using a modest (5B-token) budget, emphasizing that:
- Instruction-centric, retrieval-heavy, and heterogeneous VQA signals are the most effective for robust long-context generalization.
- Long-context ability is not a discrete feature acquired only at the maximum training length; it emerges from broad calibration over variable sequence lengths and positions.
- Short-context capability is retained without explicit mixture if the long-context data is well-formatted and diverse. This calls into question prevailing practices of maintaining high proportions of short data during continued pre-training.
- The recipe demonstrates strong backbone transferability: when applied to Qwen3-VL-8B (already containing native long-context training), performance still improves on unseen evaluation, indicating architectural robustness.
Future Directions
Open directions include scaling these ablation findings to larger model sizes (e.g., 30B, 70B LVLMs), pushing context length to 1M or more, and devising lower-cost, robust evaluation protocols capable of handling the diversity of open-ended multimodal tasks.
Conclusion
This study provides clear empirical and methodological evidence for how to extend LVLMs to very long contexts (128K and beyond), achieving substantial improvements on document VQA, retrieval, and multimodal reasoning tasks, while maintaining or improving generalization. The data synthesis and mixture strategies developed here set a rigorously validated foundation for future multimodal long-context model design and training (2605.13831).