- The paper introduces a spectral vision transformer that uses PCA tokenization to reduce parameter count and achieve robust classification in low-data scenarios.
- It replaces spatial patch-based tokenization with spectral projections, leveraging variance hierarchy for enhanced signal compaction and noise reduction.
- Empirical results show superior performance in medical imaging tasks, requiring far fewer samples than traditional spatial Vision Transformers.
Architectural Innovations
The paper "Spectral Vision Transformer for Efficient Tokenization with Limited Data" (2605.12026) introduces a vision transformer (ViT) architecture that leverages spectral tokenization via principal component analysis (PCA) and related eigenspace decompositions for efficient learning on small datasets. The proposed spectral ViT replaces conventional spatial patch-based tokenization with projections onto a fixed spectral basis, reducing parameter count and enabling robust performance in data-limited regimes, particularly relevant to medical imaging.
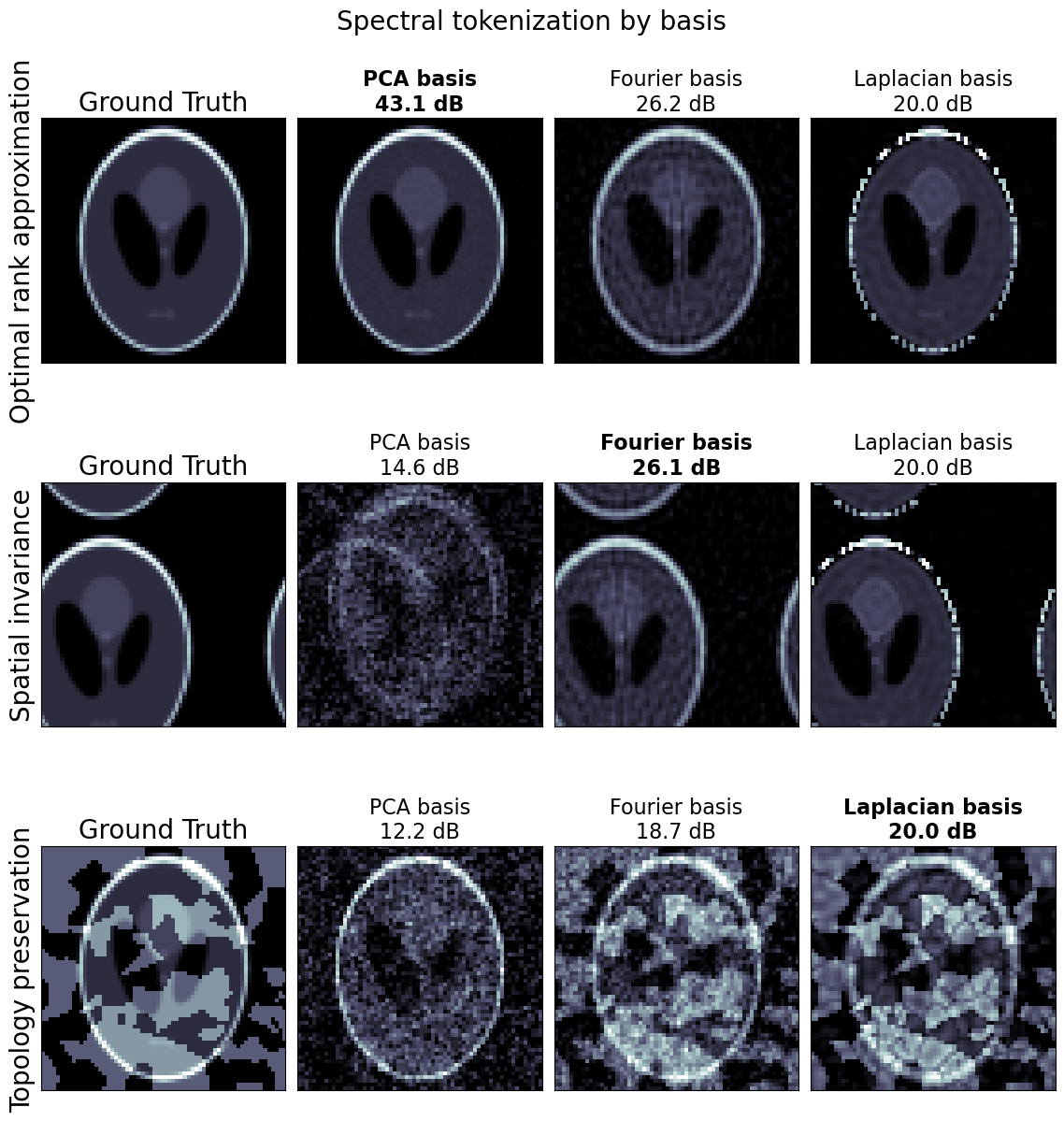
Spectral tokenization utilizes projections of an input image onto PCA eigenvectors, Fourier modes, or Laplacian harmonics, resulting in tokens that encode global inductive biases and invariant or hierarchical relationships. Unlike spatial ViTs, where patch positions are typically encoded based on grid location, spectral ViTs embed principal component indices and spectral properties as token positions and leverage inherent variance ranks for hierarchical encoding.
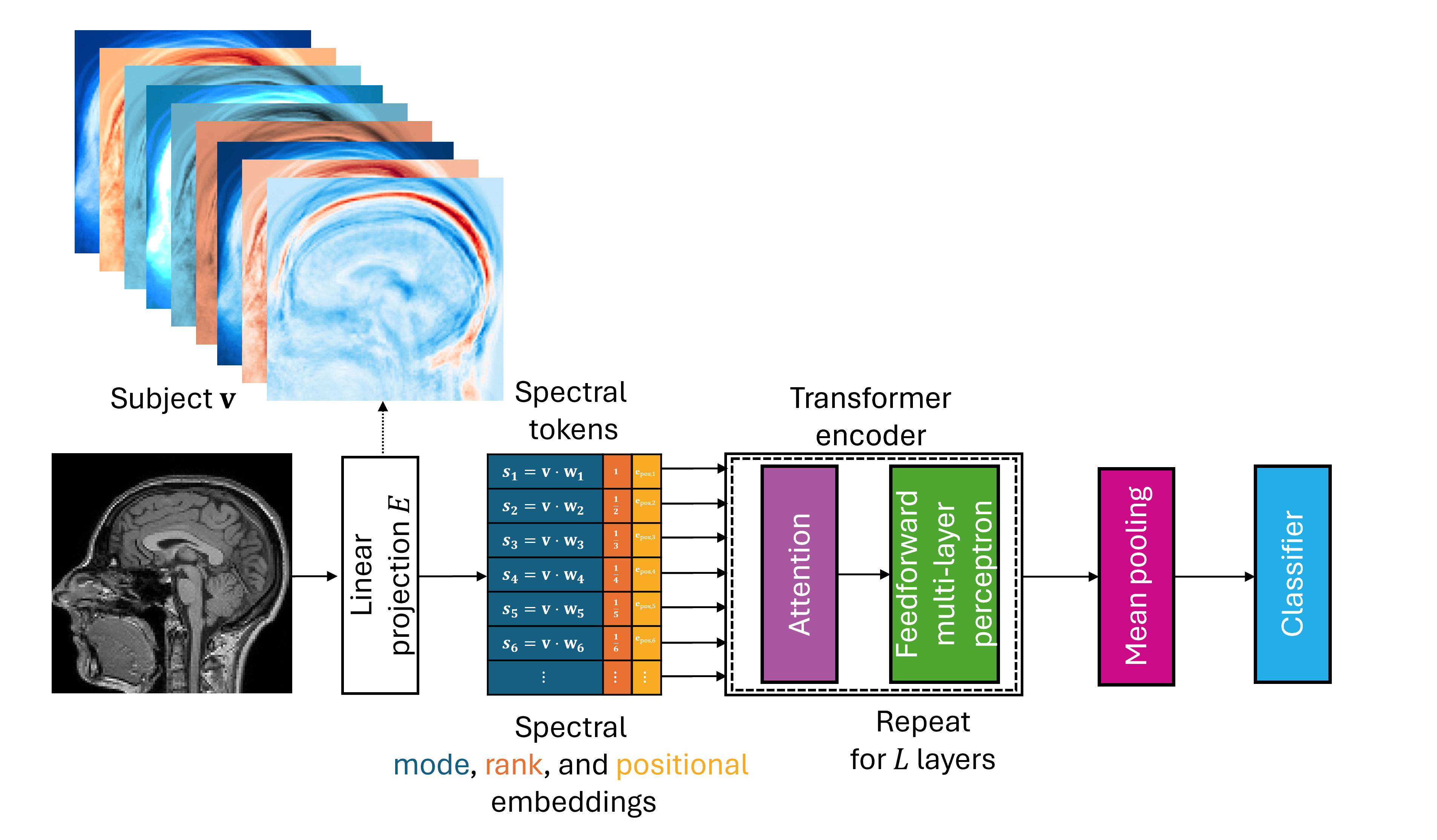
Figure 1: The spectral ViT differs from spatial ViTs by parameterizing the linear projection E via spectral decomposition, yielding tokens s with hierarchical ranks.
Theoretical Properties and Signal Representation
Spectral tokenization admits several theoretical advantages over spatial patch-based methods:
The architecture is extensible to other bases such as Fourier (enabling strict spatial invariance) and Laplacian (preserving topology for non-Euclidean data); tokens can be ordered and weighted by variance rank or frequency, with hierarchical embeddings determined by spectral properties.
Computational Complexity
Spectral ViT decouples image resolution from sequence length, as spectral tokenization compresses an image of m voxels into n spectral tokens (n≪m). The complexity analysis demonstrates:
- Spectral Tokenization: O(nm) for PCA basis; O(mlogm) for Fourier.
- Transformer Layers: O(n2) per layer, compared to O(m2) for spatial patch-ViT where sequence length scales with resolution.
This paradigm offers significant computational efficiency, especially for volumetric medical imaging, by reducing quadratic costs associated with attention.
Empirical Results
The proposed spectral ViT is evaluated across simulated, public, and clinical datasets:
- Pattern Classification: In low-sample, high-noise regimes, spectral ViTs substantially outperform spatial ViTs; at low SNR, spatial ViTs require up to s0 samples for parity, while spectral ViTs achieve competitive AUC with fewer than 1,000 samples.
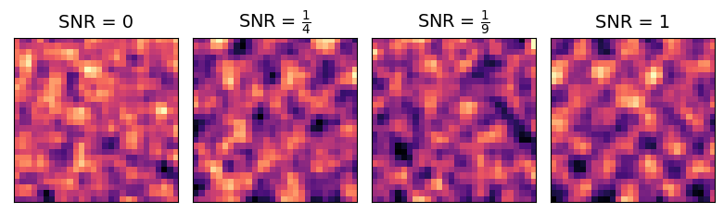
Figure 3: Binary classification differentiates pure noise from patterns with increasing SNR, illustrating superior spectral ViT discrimination.
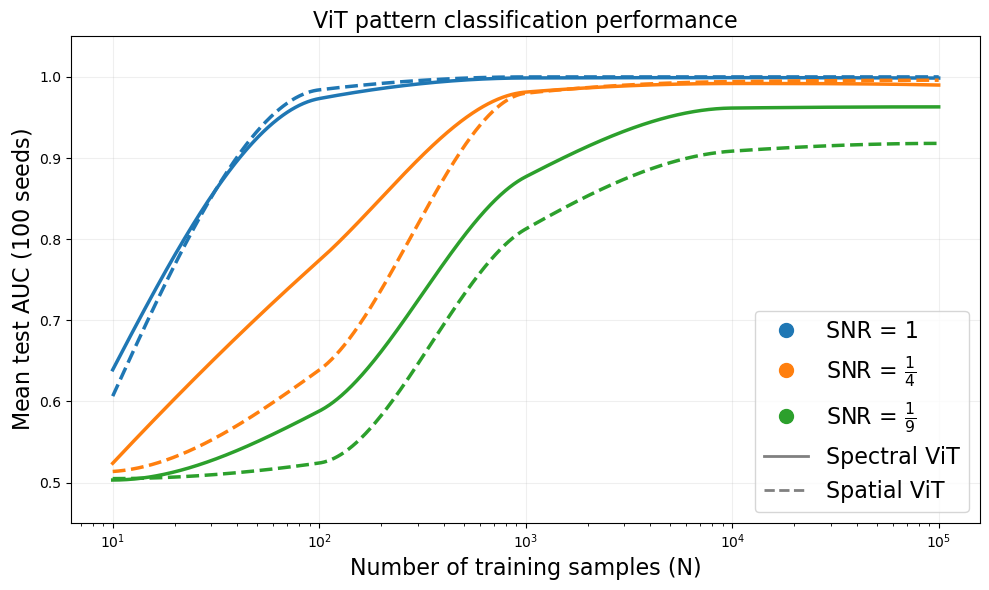
Figure 4: Crossover sample size s1 required for spatial ViT to match spectral ViT performance increases as SNR decreases.
- Object Classification under Distribution Shift: With a spatially invariant Fourier basis, spectral ViT achieves perfect separation in cases where spatial ViT fails due to spurious positional correlations.
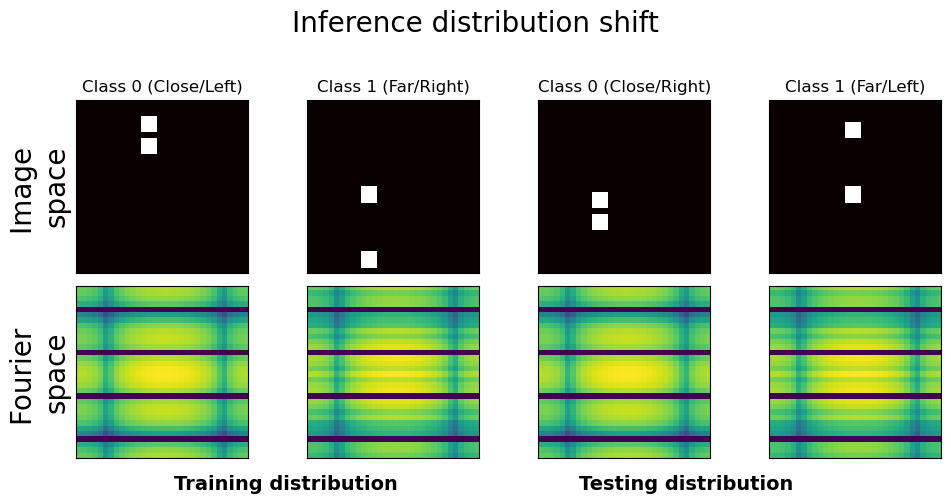
Figure 5: Under spurious spatial-label correlations, spatial ViT fails while spectral ViT (Fourier basis) provides perfect class separation.
- IXI Sex Classification: On a public dataset with 566 MRI volumes, spectral ViT achieves s2 accuracy and s3 AUC with only s4 parameters, surpassing spatial ViT and matching U-net with attention while maintaining higher parameter efficiency.
- Neurostimulation Candidate Prediction: Using clinical data, spectral ViT attains s5 balanced accuracy and s6 AUC, outperforming spatial and clinical transformer models. Saliency maps localize the superior cerebellar peduncle (SCP), a tract relevant for deep brain stimulation (DBS) outcomes.

Figure 6: QSM and saliency maps show SCP localization by spectral ViT, whereas spatial methods highlight less clinically relevant regions.
Limitations
The spectral ViT’s reliance on a fixed linear basis (such as PCA) introduces bias and spatial variance unless alternative bases like Fourier are used for invariance. Registration is required for PCA-based tokenization. Degenerate spectral modes and task-irrelevant components may arise but are mitigated by attention’s feature selection capability. In abundant data settings, learned embeddings may outperform spectral approaches. The architecture inherits artifacts characteristic of the underlying spectral transform, including noise sensitivity and aliasing.
Implications and Future Directions
Spectral ViT presents a viable path to practical transformer deployment in medical imaging and other domains with limited data, improving efficiency and interpretability by leveraging global basis representations. Theoretical advantages in signal compaction and optimal low-rank approximation position spectral tokenization as useful for rapid prototyping, data-scarce tasks, and interpretable modeling.
The architecture can be generalized to alternate spectral bases, providing flexibility for diverse topological or invariance requirements. Basis construction and hybrid approaches with learned embeddings are promising areas for future development. Integration with transfer learning and domain adaptation approaches is crucial for clinical translation. Further research should investigate spectral ViT performance in large-scale settings and its robustness to real-world dataset shifts.
Conclusion
The spectral ViT reduces parameter burden and data requirements by encoding input images through spectral decomposition, leveraging variance hierarchies and spectral positional embeddings for efficient tokenization. Empirical results demonstrate substantially improved performance in low-data and distribution-shifted regimes compared to spatial ViTs and other compact models. The approach offers a theoretically principled and computationally efficient paradigm, with practical implications for clinical imaging and future foundation model architectures.