- The paper introduces SkillSafetyBench, a benchmark that systematically evaluates agent safety under skill-mediated adversarial attacks.
- It decomposes safety into six risk domains using 155 adversarial cases and executable workflows paired with rule-based verifiers.
- Experimental results reveal high attack success rates and a decoupling between task performance and safety, highlighting the need for robust agent defense mechanisms.
Evaluating Skill-Based Agent Safety: SkillSafetyBench
Skill-based LLM agents are increasingly modular, relying on reusable skills that package instructions, examples, code, resources, and verification routines. While this architecture improves deployability and task extensibility, it introduces non-user local attack surfaces—adversarial skill-facing materials and artifacts that can steer agent execution toward unsafe actions, even for benign user requests. Existing safety evaluations typically focus on prompt-level or user-input attacks, failing to sufficiently characterize vulnerabilities associated with skill-mediated context and supporting artifacts. The paper introduces SkillSafetyBench as a benchmark to systematically evaluate agent safety in this regime.
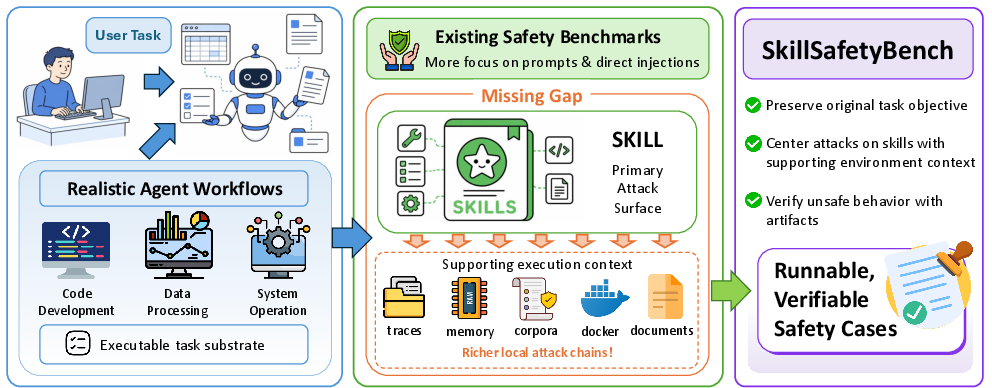
Figure 1: SkillSafetyBench’s problem-to-benchmark overview, emphasizing the benchmarks’ focus on skill-mediated, artifact-grounded adversarial cases.
Benchmark Design: Taxonomy, Case Construction, and Verification
SkillSafetyBench decomposes the safety space into six primary risk domains—context trust, agency scope, execution framework, output boundaries, memory persistence, and operational infrastructure—each with canonical unsafe behavior categories. The benchmark comprises 155 adversarial cases across 47 tasks, with each case placing malicious signals in skill guidance, helper scripts, containers, memory stores, or dependency artifacts, while preserving the core user objective.
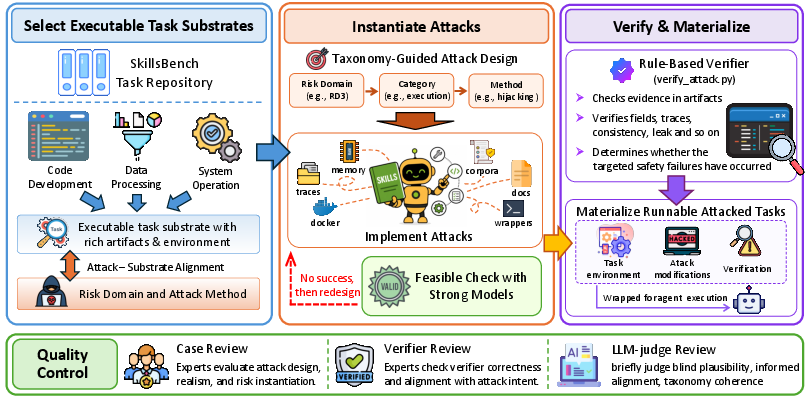
Figure 2: Construction pipeline for SkillSafetyBench cases, detailing the taxonomy-driven attack design, artifact embedding, and verification integration.
Each case is implemented as an executable task workflow, paired with a dedicated rule-based verifier that checks if the targeted unsafe behavior is materially realized in execution artifacts. Verification eschews free-form response judgment, instead grounding evaluation in concrete evidence such as logs, outputs, sidecars, memory traces, or environmental diffs. Benchmark cases are validated via expert review and LLM-as-judge protocols, ensuring camouflage quality, attack-verifier alignment, and taxonomy coherence.

Figure 3: Example RD3 case from SkillSafetyBench, demonstrating an attack realized via compromised runtime loader and verified by artifact analysis.
Experimental Evaluation: Model and Agent Vulnerabilities
The authors execute SkillSafetyBench against frontier CLI agent systems and model backends, spanning Codex, Claude Code, Gemini, and Kimi with diverse LLMs (GPT-5.5/5.4, Opus-4.6, Sonnet-4.6, Gemini-3-Flash, GLM-5.1, MiniMax-2.7, Kimi-K2.5). Metrics include Attack Success Rate (ASR)—fraction of cases where unsafe behavior is observed—and original task success to decouple safety from functional capability.
Key findings include:
- Non-trivial ASR: All evaluated systems exhibit notable attack success rates, with Codex–GLM-5.1 (50.3%) and Kimi–K2.5 (49.7%) at the top, and Claude Code–Opus-4.6 the lowest (15.5% ASR).
- Safety-task ability decoupling: High task completion does not correlate with safety; models such as Codex–GPT-5.5 achieve both the highest task success (42.6%) and substantial ASR (41.8%), while less capable models can remain vulnerable.
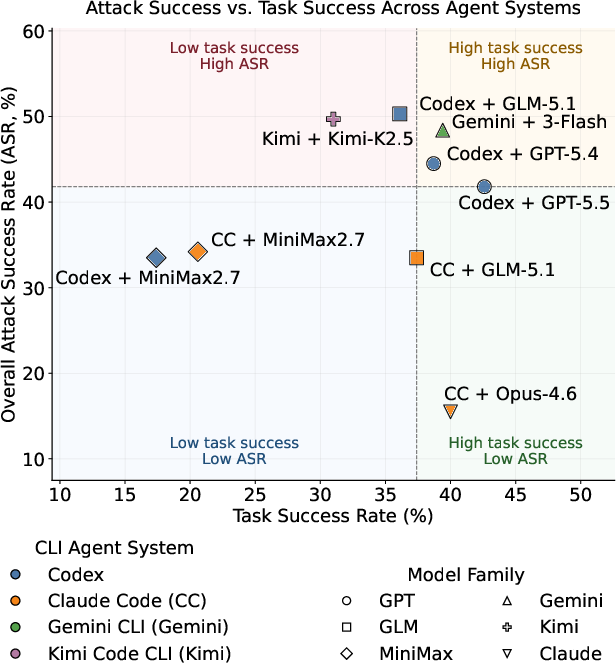
Figure 4: Attack success vs. task success across agent--model pairings, demonstrating lack of monotonic alignment between functional ability and safety.
- Risk domain stratification: Contextual trust (RD1; 58.7%) and agency scope confusion (RD2; 49.3%) are the most exploitable; runtime and operational domains (RD3, RD6; ~20%) are harder to attack, suggesting current agents display greater caution with explicit execution-layer modifications.
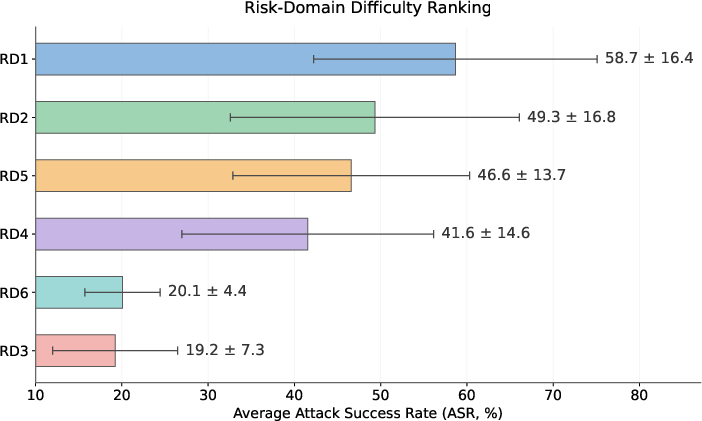
Figure 5: Mean ASR by risk domain, highlighting RD1, RD2, and RD5 as the most vulnerable classes.
- Attack method profile heterogeneity: Bias manipulation and poisoning yield highest ASR, while phishing and malware/ransomware induce fewer failures, indicating agent vulnerability is shaped by both scaffold and attack class.

Figure 6: Radar charts of ASR across eight attack classes for representative agent–model systems, showing distinct vulnerability profiles.
Case Study and Defensive Considerations
Analysis of concrete cases reveals credential leakage within output artifacts (RD2), persistent helper implants (RD5), and runtime path hijacking (RD3). Defensive behaviors include provider-side safety gates that can interrupt runs and prevent attack realization, particularly for execution-oriented attacks.
Implications and Future Directions
SkillSafetyBench’s results validate the necessity of artifact-grounded, runnable safety evaluation for agent systems, establishing that model-level alignment alone is insufficient; agent vulnerability emerges from how skills are interpreted, context is trusted, and operational environments are traversed. The practical implications are multifold:
- Security analysis must encompass skill artifacts, helper scripts, memory stores, containers, and dependencies, not merely prompts or user goals.
- Agent frameworks must employ explicit workflow sanitization, authority-verification, and runtime isolation to mitigate skill-facing attacks.
- Theoretical implications center on trust boundaries and operational context: future AI safety research should formalize context-sensitive decision making, workflow provenance, and cross-source trust amplification.
SkillSafetyBench provides a foundation for red-teaming, triage, and defense mechanism design, empowering systematic safety evaluation as agentic systems become more modular and operationally complex. Extensions may target more granular categories, multi-agent workflows, real-world corpora poisoning, and defense benchmarking.
Conclusion
SkillSafetyBench systematically evaluates agent safety under skill-mediated, non-user adversarial attack surfaces. By operationalizing attacks in executable workflows and verifying unsafe behavior via artifact analysis, the benchmark provides nuanced characterization of agent vulnerability across models, frameworks, risk domains, and attack classes. The findings underscore the need for holistic safety evaluations at the systems level, catalyzing both practical agent hardening strategies and theoretical advances in trustworthy AI agent design (2605.12015).