- The paper proposes a modality-aware PEFT strategy integrating convolutional MoE-LoRA for efficient multi-modal adaptation in RGB-D VSOD.
- It employs hierarchical feature fusion using universal interaction modules and gated receptive blocks to enhance spatial precision and temporal consistency.
- Experimental results show significant improvements in E-measure and MAE across datasets, outperforming SAM-based baselines.
Multi-Modal Mixture-of-Experts with Memory-Augmented SAM (M4-SAM) for RGB-D Video Salient Object Detection
Overview and Motivation
M4-SAM addresses the adaptation of foundation segmentation models, specifically SAM2, to RGB-D video salient object detection (VSOD). Traditional VSOD methods using RGB-D modalities are constrained by dataset scale and limited generalization; moreover, direct application of SAM2 encounters three major challenges: restricted spatial modeling in linear LoRA, lack of exploitation of multi-scale features, and dependency on explicit prompts for memory initialization. M4-SAM overcomes these technical issues via modality-aware parameter-efficient fine-tuning (PEFT) using convolutional mixture-of-experts (MoE-LoRA), hierarchical feature fusion with gating, and a prompt-free memory initialization strategy using pseudo-guided mask bootstrapping.
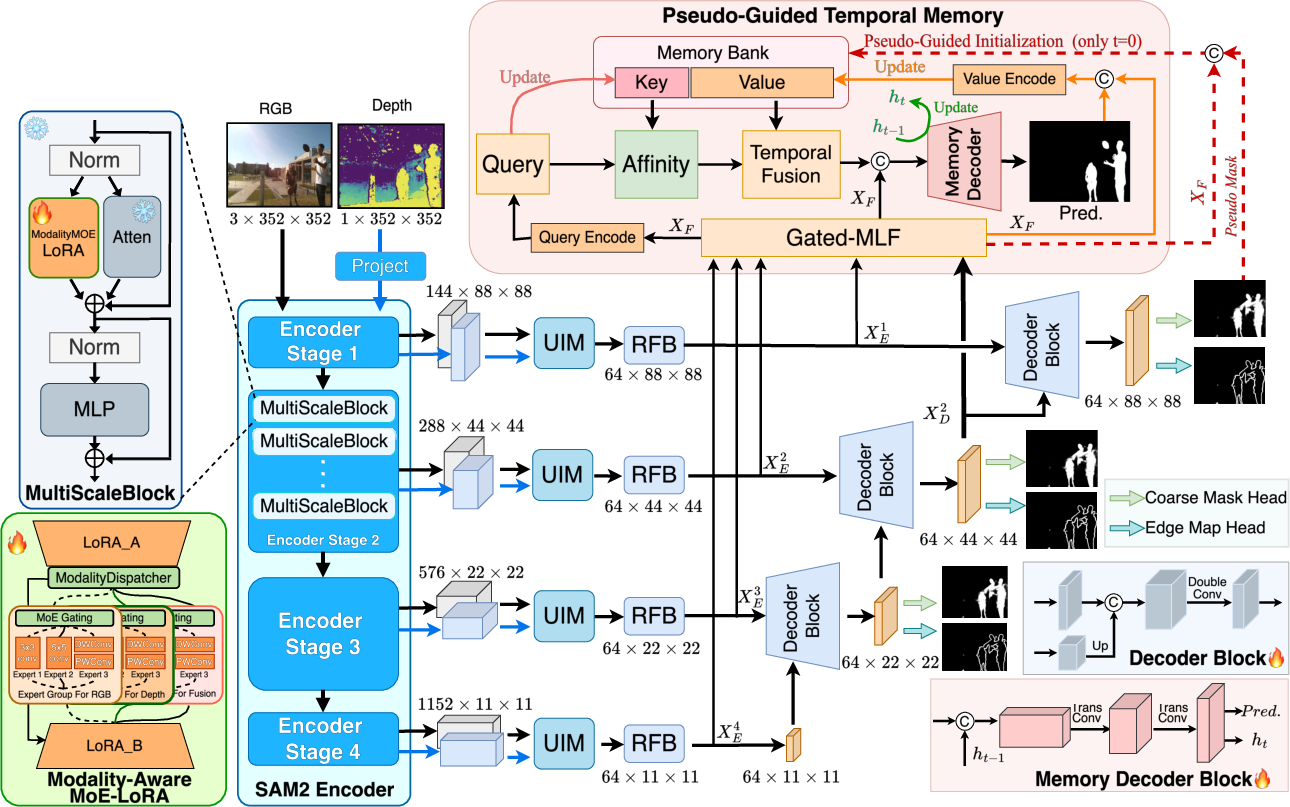
Figure 1: The overall architecture of M4-SAM, integrating modality-aware MoE-LoRA, hierarchical feature fusion, and prompt-free memory initialization for RGB-D VSOD.
Methodological Innovations
Modality-Aware MoE-LoRA Encoder
The encoder employs a shared Hiera backbone augmented with the Modality-Aware MoE-LoRA module. Each LoRA branch is replaced with convolutional experts of varying kernel sizes, introducing locality priors. The MoE Gating mechanism adaptively selects the top-K experts based on input context; this is further extended with modality-specific grouping (RGB, depth, fusion), coordinated by a Modality Dispatcher, enabling unified and efficient RGB-D feature extraction. This design significantly reduces memory overhead in multi-modal adaptation and avoids redundant computation intrinsic to dual-encoder strategies.
Hierarchical Feature Fusion and Decoder
Multi-level RGB and depth features extracted by the encoder are fused through Universal Interaction Module (UIM) and Receptive Field Block (RFB) to produce unified multi-modal representations. The hierarchical decoder utilizes skip connections and upsampling, generating coarse segmentation masks and edge maps at multiple levels for auxiliary supervision, enhancing spatial precision and boundary delineation.
Pseudo-Guided Temporal Memory
M4-SAM implements a prompt-free temporal memory design that hierarchically aggregates multi-scale features via a Gated Multi-Level Feature Fusion module. Feature fusion is performed using gated weights that balance shallow and enhanced representations, subsequently concatenated with mid-level decoder features for temporal modeling. Cross-attention between current features and the memory bank facilitates consistent predictions across frames. Memory initialization is pseudo-guided: a coarse mask derived from early decoder layers is used to bootstrap the memory bank without explicit user prompts, exploiting attention-based affinity suppression to mitigate erroneous initialization.
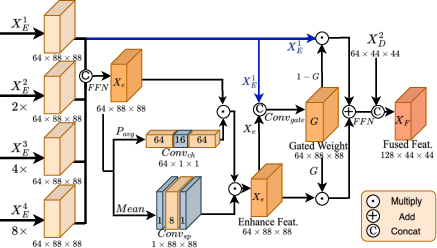
Figure 2: The Gated Multi-Level Feature Fusion module provides adaptive aggregation of multi-scale encoder features to optimize spatial-semantic balance.
Experimental Results
Extensive experimentation was conducted across three RGB-D VSOD datasets: DViSal, RDVS, and ViDSOD-100. Evaluation metrics include E-measure, S-measure, F-measure, and mean absolute error (MAE).
Numerical Highlights:
- On DViSal, M4-SAM achieved E-measure of 0.925 and F-measure of 0.828, outperforming the second-best KAN-SAM by 4.5% and 5.7%.
- On RDVS, E-measure reached 0.927, surpassing DCTNet+ by 2.0%.
- On ViDSOD-100, E-measure and MAE were 0.936 and 0.016, with 2.6% and 0.009 improvements over KAN-SAM.
- Compared to SAM-based baselines (MDSAM, SAM2-UNet, KAN-SAM), M4-SAM demonstrates average improvements of 6.9%, 7.6%, and 2.9% in E-measure, affirming that gains are not merely due to backbone selection.
Ablation Studies:
Implications and Future Directions
The M42-SAM framework sets a new operational paradigm for foundation model adaptation in multi-modal video settings. The modality-aware MoE-LoRA design provides an efficient pathway for fine-tuning large encoders across modalities, and the hierarchical fusion mechanism ensures preservation of fine spatial structure and semantic context, critical for dense prediction tasks. The pseudo-guided initialization strategy presents a scalable solution for prompt-free deployment, eliminating manual intervention while leveraging pseudo priors.
Practically, these advances enable robust salient object detection in real-world, unconstrained RGB-D video streams, beneficial for applications in robotics, surveillance, and automated visual analysis. Theoretically, the approach generalizes principles of PEFT into multi-modal fusion regimes, potentially extensible to other vision-language or sensor fusion tasks. Future directions may focus on further scaling generalization, domain adaptation, and application to compound tasks such as video grounding, multi-modal action recognition, and lifelong video understanding.
Conclusion
M43-SAM introduces a modality-aware, prompt-free adaptation of SAM2 for RGB-D VSOD, combining convolutional mixture-of-experts fine-tuning, gated hierarchical feature aggregation, and pseudo-guided temporal memory initialization. The model outperforms prior SOTA approaches across all major video RGB-D benchmarks and establishes a principled methodology for efficient, scalable multi-modal foundation model adaptation. The framework’s modularity and efficiency suggest promising avenues for future research in advanced multi-modal video tasks.


