- The paper introduces a differentiable BCJR-based soft relaxation to replace the non-differentiable Viterbi argmax in trellis-coded quantization.
- It demonstrates a fused Triton kernel implementation that yields a 6.57× speedup and improves per-layer MSE and KL distillation performance.
- The study highlights training challenges like schedule overshoot and proxy gap, with observed super-additive effects in multi-layer quantization.
Differentiable Trellis-Coded Quantization via BCJR-QAT
Efficient quantization of large-scale transformer models to ultra-low bit-widths is a key enabler for deployment on commodity hardware. While scalar and vector quantization are effective at 4 bits per weight (bpw), significant performance degradation is observed at 2 bpw, necessitating more structured quantization approaches. Trellis-Coded Quantization (TCQ), particularly as instantiated in QTIP, currently sets the frontier for 2-bit PTQ of dense transformers by leveraging codewords structured as Viterbi paths through a finite-state trellis.
However, further quality improvements at these quantization rates require Quantization-Aware Training (QAT). Direct application of QAT to trellis-coded quantization is obstructed by the non-differentiability of the Viterbi decoding step: the global argmax over exponentially many paths precludes standard gradient flow. BCJR-QAT ("BCJR-QAT: A Differentiable Relaxation of Trellis-Coded Weight Quantization" (2605.10655)) addresses this by proposing a continuous, differentiable relaxation of the trellis decoding stage using the forward–backward (BCJR) algorithm, enabling end-to-end gradient propagation through the structured quantizer.
Method: Softening Viterbi via BCJR Relaxation
Trellis Structure and Quantization
The approach begins by adopting a Gaussian HYB trellis with fixed block size and state count. After applying QuIP/QTIP-style incoherence processing via random Hadamard rotations, each block of weights is encoded as a sequence of trellis transitions emitting codebook values. The codeword selection corresponds to an argmax over all legal paths, efficiently computed by the Viterbi algorithm in O(LS2) time.
Differentiable Relaxation with Temperature Annealing
BCJR-QAT introduces a finite-temperature (soft) variant of the trellis decoding wherein, rather than a hard argmax, the codeword at each position is taken as the expectation under a Boltzmann path distribution at temperature T. As T→0, the path distribution concentrates on the optimal Viterbi path, recovering the hard quantizer. For positive T, the forward–backward (BCJR) algorithm computes the marginal posteriors over trellis states, yielding a soft codeword that is differentiable with respect to both the weights and the trellis emission parameters. Crucially, the relaxation mirrors the transfer-matrix approach for 1D Ising spin chains, providing an exact, tractable, and stable mechanism for differentiable discrete path selection.
Efficient Implementation
A fused Triton kernel is introduced to execute the forward–backward passes in a single autograd operation, yielding a 6.57× end-to-end speedup compared to a reference autograd-native PyTorch implementation, with memory optimizations critical for tractability on commodity GPUs.
Training Protocols and Schedules
Per-layer greedy QAT is employed, initializing from QTIP-PTQ solutions. A temperature annealing schedule is key for performance: conventional high–T starts (e.g., Tinit=1.0) are shown to degrade performance. Skipping to a lower initial temperature (Tinit=0.3) avoids what the authors term "schedule overshoot," where gradient information is suppressed and the optimizer is driven into suboptimal Voronoi basins.
Empirical Analysis and Results
Proxy Gap in Per-Layer MSE Optimization
Experiments on OLMoE-1B-7B under per-layer MSE objectives demonstrate that BCJR-QAT outperforms QTIP-PTQ significantly on per-layer reconstruction metrics (2.9% lower per-layer MSE in geometric mean for BCJR-QAT-v2 over N4).
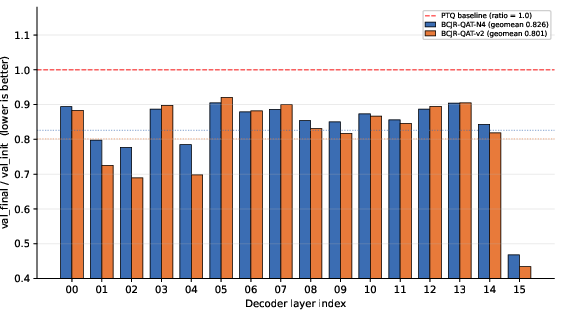
Figure 1: Per-layer val_final/val_init ratio for BCJR-QAT-N4 and BCJR-QAT-v2 across the 16 OLMoE decoder layers; v2 achieves a 2.9% improvement over N4 on the reconstruction objective.
However, this reduction in proxy loss does not translate into improvements in end-to-end perplexity or downstream task accuracy; instead, both configurations yield approximately 1.3 PPL higher than the QTIP-PTQ baseline. This empirically confirms the existence of a substantial "proxy gap" at 2 bpw: local reconstruction metrics are insufficient surrogates for end-task performance in this regime.
End-to-End KL Distillation and Schedule Overshoot
The study then turns to Llama-3.2-1B, quantizing individual decoder layers with full forward-KL distillation against an FP16 teacher. This change of objective eliminates the proxy gap: with the correct temperature annealing schedule (skip-high-T), BCJR-QAT achieves a -0.084 PPL improvement over QTIP-PTQ at 2 bpw on WikiText-2. In contrast, using the "naive" high–T schedule overshoots into inferior Voronoi cells, even though the optimizer escapes the initial basin.
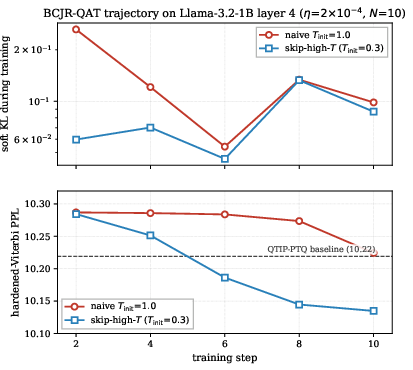
Figure 2: BCJR-QAT training trajectory on Llama-3.2-1B layer 4: high-T0 ("naive") schedule induces non-monotonic, inferior hardened-Viterbi PPL, while skip-high-T schedule yields monotonic improvement and surpasses the QTIP-PTQ baseline.
Empirical runs with different drift budgets, learning rates, and step counts confirm that schedule overshoot is a primary failure mode, distinct from mere capacity to move between basins.
Multi-Layer Super-Additivity
Jointly installing two BCJR-QAT-trained layers (one with skip-high-T, one with naive schedule) yields a -0.077 PPL gain over the joint QTIP-PTQ baseline, exceeding the sum of individual gains ("cooperation surplus"). This demonstrates that BCJR-driven codeword updates at different layers reinforce each other non-additively, in contrast to PTQ-optimized codewords which optimize for purely local objectives.
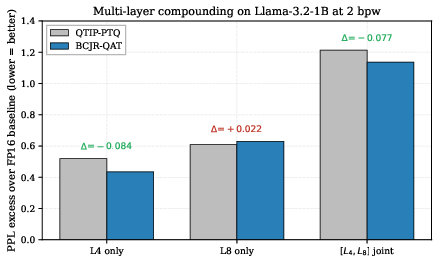
Figure 3: Multi-layer compounding test quantifying PPL excess over FP16 baseline for layer 4, layer 8, and joint installations; joint compounding of BCJR-QAT-trained codewords outperforms the expected sum, indicating super-additive effects.
Drift-Budget Feasibility and Boundaries
The feasibility of escaping PTQ-local minima is controlled by the per-step drift in the latent weights relative to the Voronoi cell radius, given by T1. Runs below this threshold show no movement; above threshold, improvement or regression depends on the schedule and gradient direction.
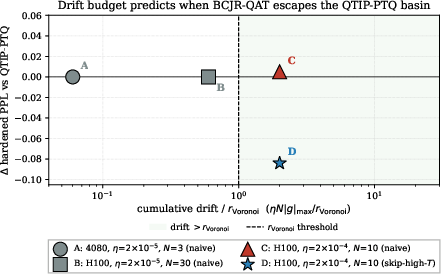
Figure 4: Empirical confirmation of the drift-budget bound; above-threshold drift is necessary for basin movement, but positive PPL improvements require an informative training objective and schedule.
Theoretical and Practical Implications
The results have both practical and theoretical implications:
- End-to-End Training Objective: Per-layer losses (e.g., MSE) are unreliable proxies at high compression ratios, intensifying the need for integrating end-task objectives, such as KL divergence against a teacher.
- Temperature Regimes: Effective temperature scheduling for soft-relaxations is nontrivial; classical simulated annealing intuition fails for this instance, and gradient informativeness at finite T2 is critical.
- Scalable Implementation: The efficient Triton kernel provided makes it feasible to extend these differentiable relaxations to full-model QAT on commodity hardware, with further gains expected on cloud-scale infrastructure.
- Super-Additive Compounding: Empirical super-additivity observed in the multi-layer compounding test suggests that coordinated joint training across layers may yield even larger model-level gains; whether this effect scales linearly, sub-linearly, or saturates is an open question.
From a theoretical standpoint, the relaxation to a BCJR-based marginalization is structurally identical to transfer-matrix methods in statistical physics, underlining a connection between discrete codeword selection in quantization and statistical mechanics of spin chains. This point is emphasized as aligning with broader efforts to develop a "scientific theory of deep learning" anchored in physics-inspired perspectives.
Limitations and Future Directions
Current demonstrations are limited to single- or dual-layer QAT due to hardware constraints. Full end-to-end, all-layer BCJR-QAT with skip-high-T3 scheduling is the natural progression, now accessible due to efficient kernelization. The method so far freezes the emission codebook; BCJR-QAT readily supports joint optimization of emission parameters, potentially yielding further rate-distortion improvements, particularly for non-Gaussian weight distributions. Calibration domain sensitivity and stability across seeds warrant further investigation. Additionally, more expressive trellis structures or alternative relaxation schemes might be considered for further gains at even lower bit rates.
Conclusion
BCJR-QAT establishes a mathematically principled, computationally tractable pathway to differentiable quantization-aware training of trellis-coded quantizers. The central innovation—replacing Viterbi's non-differentiable argmax with the BCJR soft marginalization—enables accurate, end-to-end gradient propagation, overcoming the critical bottleneck that limited prior art at ultra-low quantization rates. Empirical results confirm nontrivial perplexity reductions over state-of-the-art PTQ when optimizing the correct global loss, and identify both a novel proxy gap and schedule overshoot phenomenon critical for practitioners. Released code and kernels render the method accessible for broad investigation and deployment, with clear pathways identified for scaling and further refinement.
References:
- BCJR-QAT: A Differentiable Relaxation of Trellis-Coded Weight Quantization (2605.10655)

