- The paper introduces MulTaBench, a benchmark that rigorously evaluates multimodal tabular learning using target-aware representation tuning.
- It curates 40 diverse datasets, ensuring that the joint signal of structured and unstructured modalities is essential for improved prediction.
- Empirical findings demonstrate that target-aware adaptation consistently outperforms frozen embeddings across various model types and tasks.
MulTaBench: A Principled Benchmark for Multimodal Tabular Learning with Text and Image
Motivation and Background
Multimodal Tabular Learning (MMTL) problems—where structured tabular data is combined with unstructured modalities such as free-text or images—are increasingly prevalent in high-impact fields spanning healthcare, e-commerce, and the social sciences. While Tabular Foundation Models (TFMs) [van_breugel_position_2024, hollmann_tabpfn_2022, grinsztajn_tabpfn-25_2026] have established state-of-the-art results for purely structured data, they lack native support for unstructured modalities, instead relying on frozen, pretrained embeddings. This design choice enforces a separation between representational learning for text/image and the downstream tabular prediction task, creating information bottlenecks detrimental to fine-grained, multimodal problems.
MulTaBench is introduced to address both methodological and benchmarking deficiencies in current MMTL research. Existing benchmarks primarily target the coexistence of multiple modalities but fail to systematically identify scenarios where joint modeling and task-specific fine-tuning are genuinely required. Consequently, the relative benefits of model adaptation and architectural advancements in multimodal settings are confounded by excessive task heterogeneity and weak unstructured signals.
Benchmark Curation and Design
The central contribution is the formalization and operationalization of two key desiderata for MMTL datasets:
- Joint Signal: Each modality must contribute independent, complementary information to the target prediction. Removal of any modality should reduce downstream predictive performance.
- Task-awareness: For a given target, naive task-agnostic embeddings (frozen encoders) must be insufficient. Only target-aware representation (TAR) tuning—i.e., adaptation of encoder parameters w.r.t. the supervision signal—should recover the crucial predictive information that off-the-shelf embeddings lose due to semantic smoothing and lossy compression.
The curation protocol rigorously tests candidate datasets under four experimental conditions—unimodal structured, unimodal unstructured, joint frozen, joint TAR—across multiple families of tabular learners. A dataset is selected for inclusion only if it satisfies both properties via consistent, significant gains in the Joint TAR setting across a majority of models.
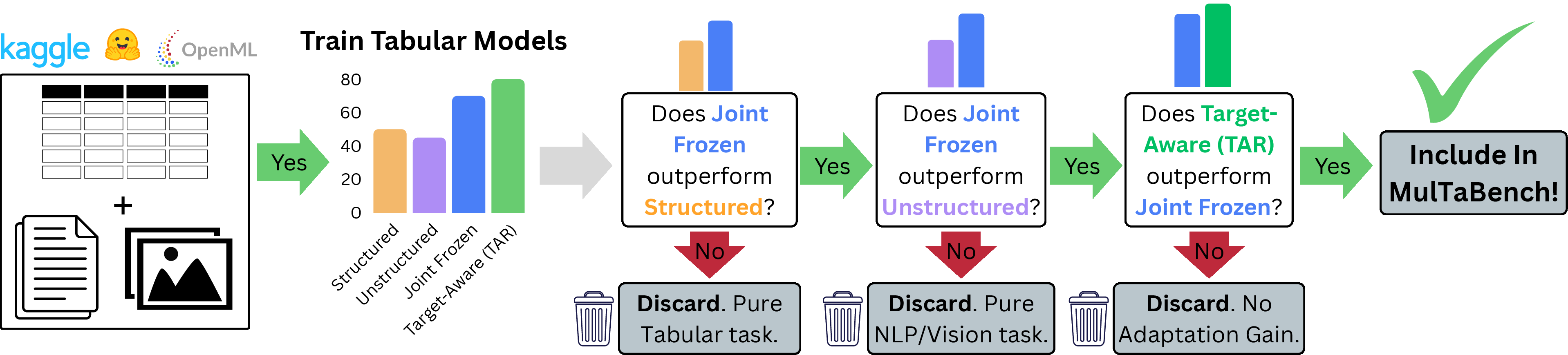
Figure 1: The curation pipeline selects only datasets where joint modeling and target-aware adaptation for unstructured modalities (text/image) robustly improve performance over standard baselines.
This protocol filters out datasets where the unstructured modality is redundant or trivially captured by frozen embeddings, leading to benchmarks more representative of the actual MMTL research frontier.
MulTaBench Composition and Characteristics
MulTaBench contains 40 datasets—20 image-tabular, 20 text-tabular—normalized to balance classification and regression, task size, domain, and number of structured/unstructured features. Notably, it is the largest, most diverse image-tabular benchmark to date, representing fields such as medical imaging, e-commerce, and social media.
For text-tabular, rigorous curation across all established sources reveals that only 41% of published datasets meet the Joint Signal and Task-awareness criteria (Table \ref{tab:text_curation_rates}), confirming the historic overestimation of benchmark difficulty in the literature.
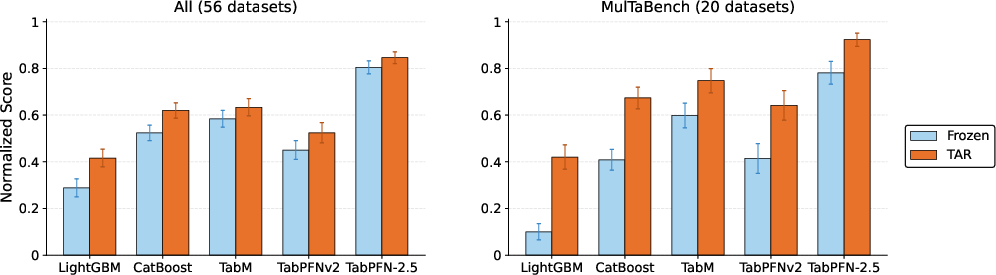
Figure 2: Across curated text-tabular datasets, target-aware tuning robustly delivers gains over frozen encoders for all model classes in both the overall pool and the MulTaBench subset.
Curation for image-tabular tasks is especially stringent due to data availability and reproducibility issues, with less than one-third of candidates qualifying and refined via careful preprocessing—dropping trivially predictive features, enforcing single image columns, and transforming targets as required.
Numerical Results and Empirical Insights
Extensive empirical evaluation confirms several strong, generalizable results:
- Target-aware adaptation consistently and significantly improves predictive performance across all learners, encoder architectures, and PCA projection dimensions.
- These improvements are not eliminated by scaling up encoder size; even large encoders with greater representational capacity are still suboptimal if not adapted for the target.
- Boosted decision trees (GBDTs) benefit most from TAR, but the pattern extends to MLPs, TFMs, and state-of-the-art foundation models such as TabPFNv2 and TabPFN-2.5.
- For both classification and regression tasks, TAR outperforms frozen embeddings within each task subtype.
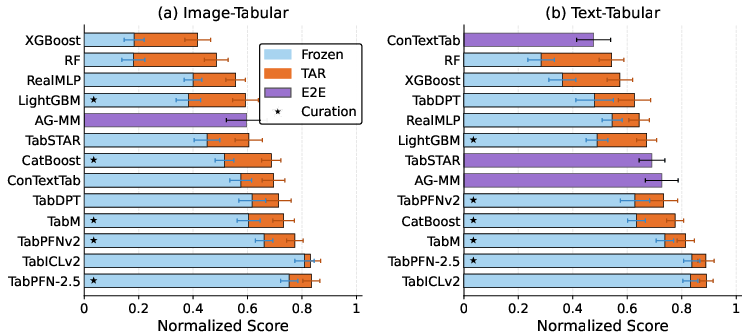
Figure 3: All major tabular learner classes exhibit consistent, statistically significant improvements from target-aware representation tuning across the MulTaBench datasets.
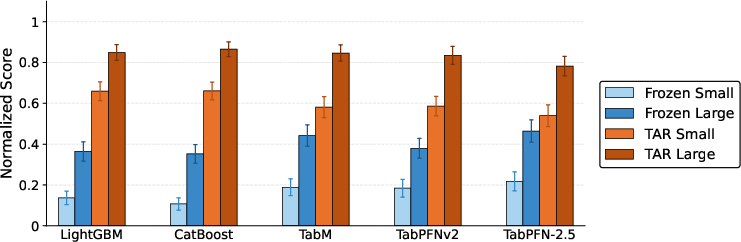
Figure 4: Target-aware variants are consistently superior to frozen representations at both small and large encoder scale, indicating that representational adaptation cannot be overlooked even for high-capacity models.
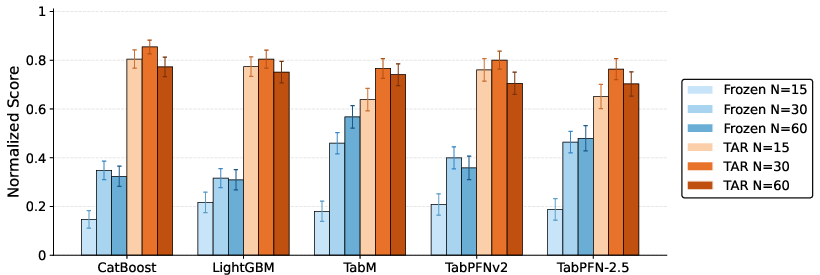
Figure 5: Target-aware representation gains are stable with respect to the choice of embedding dimension, ruling out the hypothesis that improvements are reducible to PCA compression artifacts.
Visualization of image encoder [CLS]-to-patch attention after target-aware tuning demonstrates marked shifts in model focus—from irrelevant backgrounds and global details to specific, clinically or semantically relevant regions congruent with the prediction target.






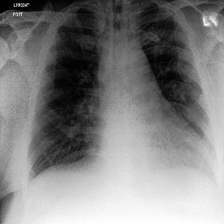
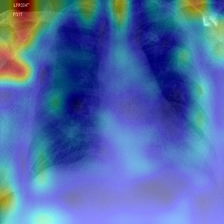
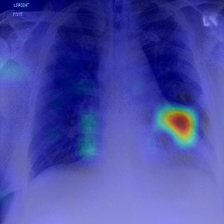
Figure 6: Attention maps in DINO-v3-small before and after TAR; adaptation redirects the model’s focus to regions reflecting the prediction target (e.g., lung area for CheXpert, facial features for Celeb Attractiveness).
These findings are robust to the inclusion of new tabular learners (e.g., XGBoost, TabM, TabDPT), new end-to-end text/image models (TabSTAR, AutoGluon-Multimodal), and to ablations removing PCA altogether.
Implications, Limitations, and Future Research
MulTaBench isolates the truly challenging axes of MMTL for the community, refocusing development away from generic cross-modal pipelines towards architectures capable of target-aware representation alignment and joint optimization. Current architectures—frozen-embedding TFMs and in-context learners—fail to satisfy MMTL demands when unstructured modalities encode high-entropy, non-semantic details tied to downstream labels.
The explicit, dataset-level requirement for TAR as a property ensures that benchmarks reflect not co-occurrence but the necessity of contextually adaptive representations, aligning MMTL more closely with the vision-language paradigm’s trajectory (e.g., deep cross-modal alignment in VQA and dense retrieval).
A primary limitation is that the curation protocol itself entwines algorithmic and dataset properties; the process cannot guarantee immunity from selection bias in favor of specific learners, and the necessary cost and complexity of encoder adaptation raises practical concerns for deployment and reproducibility at scale.
Looking forward, MulTaBench supports:
- The principled development and evaluation of fully end-to-end multimodal tabular foundation models.
- Research into cost-efficient TAR adaptation methods (e.g., adapters, LoRA, cross-attention contextualization) to minimize computational burden in practical settings.
- Expansions into multi-modality (e.g., text-image-tabular, audio), synthetic-data-driven pretraining, and integration with very large foundation models for tabular in-context learning.
- Revised benchmarks and curation logic as new model classes close the gap on existing datasets.
Conclusion
MulTaBench fundamentally raises the bar for benchmarking in multimodal tabular learning by enforcing that only tasks which genuinely require joint modality modeling and target-aware adaptation are included. The widespread, statistically robust numerical improvements from contextualized representation tuning across modalities, encoders, and learning paradigms indicate that progress for MMTL is predicated on developing architectures and tuning protocols that exploit label information to adapt unstructured representations, rather than on scaling or naive fusion.
MulTaBench is thus poised to become a standard for evaluating and guiding the next generation of multimodal tabular foundation models, unifying benchmarking protocol and task difficulty with the practical demands of real-world scientific and industrial settings.
Figure 1: MulTaBench Curation Pipeline—datasets are admitted based on mandatory joint signal and target-aware representation gains.
Figure 2: Target-Aware Representations yield superior normalized scores versus frozen across all text-tabular datasets, robustly confirmed in MulTaBench.
Figure 3: Target-aware representation tuning universally improves downstream performance of all tabular learner classes on the MulTaBench evaluation suite.
Figure 4: Larger embedding models confer additional benefit, but TAR consistently outpaces frozen representations even at higher scales.
Figure 5: Target-aware tuning remains effective beyond typical PCA projection sizes, showing stability across a range of embedding dimensions.
Figure 6: DINO-v3-small Attention Maps—fine-tuning shifts attention from diffuse or global features to task-relevant regions in diagnostic images.