- The paper introduces E-TCAV, a framework that uses penultimate layer proxies to approximate TCAV and reduce computation time while retaining interpretability.
- It demonstrates that SignalCAV reduces variance and enhances inter-layer agreement, offering a more stable alternative to conventional SVM-based methods.
- Empirical results reveal over 30% runtime improvements and strong conceptual alignment across vision and NLP architectures.
Introduction
The paper "E-TCAV: Formalizing Penultimate Proxies for Efficient Concept Based Interpretability" (2605.10261) systematically addresses multiple persistent challenges in the use of TCAV (Testing with Concept Activation Vectors) for model interpretability. TCAV offers a post-hoc method for quantifying the influence of human-interpretable concepts on neural network prediction, leveraging directional derivatives in latent spaces. However, its adoption has been hindered by computational bottlenecks, instability arising from latent classifier variability, and inconsistencies of interpretability scores across layers.
E-TCAV is introduced as a rigorous and efficient approximation framework, grounded in the empirical and theoretical analysis of three axes: (1) the role of latent classifiers (including SignalCAV and SVMs) in stabilizing TCAV scores; (2) inter-layer agreement of TCAV scores, with a focus on penultimate and preceding layers; and (3) the use of the penultimate layer as a high-fidelity, computationally efficient proxy for earlier layers. These axes are explored across multiple architectures and both vision and NLP tasks.
Theoretical Underpinnings
Degeneracy of Directional Sensitivity at Penultimate Layers
It is analytically proven that when the network's classifier head is affine (a property satisfied by the penultimate-to-output mapping of most CNNs and many transformer heads in inference), directional sensitivity at the penultimate layer becomes sample-independent. Explicitly, for an affine classifier hk(a)=wk⊤a+bk, the TCAV sensitivity reduces to wk⋅vC, independent of input. As a result, the entire computation of TCAV for a concept/class pair at this layer is reducible to a single dot product, eliminating the need for per-sample gradient evaluation and facilitating runtime improvements that scale with both dataset and model size.
Layer-Wise Agreement: The Penultimate Proxy Principle
The authors introduce a TCAV agreement score, essentially $1$ minus the mean absolute error of TCAV scores across concepts, to quantify conceptual consistency between network layers. Empirically, strong agreement (frequently >0.75) is observed between the penultimate layer and up to four preceding layers across architectures and modalities, justifying the practical use of the penultimate TCAV computation as a proxy for these layers without material loss of interpretability fidelity.
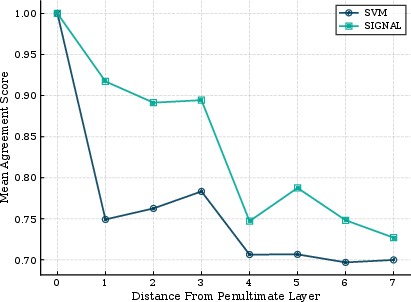
Figure 1: Behavior of TCAV scores at different layers and their mean agreement with penultimate-layer scores, averaged across datasets and architectures.
SignalCAV and Classifier-Induced Stability
The study demonstrates that substantial variance in TCAV scores—previously attributed to inherent instability of concept-based interpretability—can be traced to the choice of latent classifier used to compute the concept activation vector (CAV). SignalCAV, computed as the (normalized) covariance between activations and binary concept labels, is substantially less sensitive to random fluctuations and non-concept sample selection than typical SVM-based approaches. This deterministic formulation results in lower statistical variance, improved p-values, and higher inter-layer agreement.
Numerical results across datasets—CelebA, ISIC-2019, SCDB, ImageNet, and the Wikipedia Toxicity dataset—show standard deviation reductions up to an order of magnitude and consistent improvements in statistical significance of TCAV scores using SignalCAV versus SVMs.
E-TCAV Framework and Computational Complexity
Building upon the aforementioned observations, E-TCAV is formalized as follows:
- Employ SignalCAV (or an alternative deterministic classifier, if justified) for CAV construction.
- For layers in the terminal network block (typically within four layers of the penultimate/affine layer), approximate their TCAV scores using only the penultimate-layer calculation.
The resulting complexity reduces from O(N⋅(Cfp(l)+Cbp(l)+Dl)) (where N is the number of evaluation samples and Cfp/bp are costs of forward/backward passes) to O(Dp) for penultimate-layer computation; classification training cost O(T(M,Dp)), for M concept samples, is unchanged but amortized over the substantial reduction in per-sample sensitivity calculations.
Pragmatically, per-experiment speedups exceeding wk⋅vC0 are reported across several architectures, and the gains scale linearly with model parameter count.
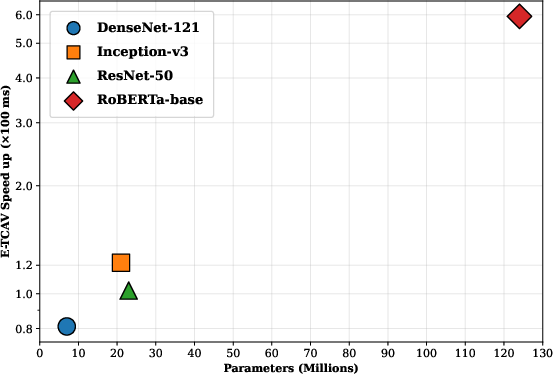
Figure 2: Observed linear improvement in runtime reduction by E-TCAV as a function of neural network parameter count.
Empirical Evaluation
Concept Direction Validation
Using CelebA (specifically, hair color and necktie concepts), both SVM and SignalCAV approaches identify correct concept directions, as verified by statistical and ground-truth attributes. SignalCAV is shown to yield more stable results with negligible loss in interpretability efficiency compared to SVM.
Cross-Domain Robustness
The evaluation spans four vision architectures (including ResNet50, DenseNet121, InceptionV3) and RoBERTa-base for text, with consistent results on agreement and stability observed across both domains. Notably:
- Inter-layer TCAV agreement exceeding 0.75 persists across up to four layers prior to the penultimate for both vision and NLP networks.
- SignalCAV systematically yields higher agreement scores than SVM, except in high-complexity scenarios (e.g., ImageNet) where SVM may produce marginally better alignment, suggesting that classifier selection should remain task-dependent in E-TCAV.
Efficiency and Variance Reduction
Wall-clock experiments confirm that runtime reductions are strictly monotonic with model scale, and standard deviation analyses show that SignalCAV dominates in terms of variance minimization, affirming the framework's operational reliability in concept-based interpretability.
Implications and Future Directions
E-TCAV introduces a robust, theoretically-grounded approach to dramatically accelerate concept-based interpretability, with several immediate consequences:
- Scalable, Real-Time Interpretability: By linearizing the complexity w.r.t. dataset and model size, E-TCAV enables integration of conceptual interpretability tools into the model training loop, notably for real-time or batchwise concept-guided training.
- Layer Selection Formalization: The strong empirical agreement across late network layers informs best practices for layer probing in interpretable model auditing: practitioners can confidently restrict focus to penultimate or near-penultimate layers for semantic analysis, with justified efficiency gains.
- Reliability and Consistency: By attributing most TCAV variance to latent classifier selection and providing a stable alternative (SignalCAV), E-TCAV enables more reliable and statistically sound interpretability reports.
While E-TCAV is shown to be most effective in the final network block, divergence in deeper layers underscores limitations for approximating non-terminal layer conceptual behavior. Future work should explore principled approximation schemes (potentially leveraging learned mappings) for earlier layers, as well as expanded analysis on cases (e.g., ultra-high class cardinality tasks) where SVMs may outperform SignalCAV.
Conclusion
This work establishes E-TCAV as a scientifically and empirically rigorous framework for accelerating concept-based neural interpretability. Through an overview of analytical degeneracy in directional sensitivities, robust metricization of inter-layer agreement, and classifier stabilization, E-TCAV delivers linear runtime improvements and more consistent TCAV evaluations. Adoption of E-TCAV holds practical utility for efficient and reliable post-hoc explanation, bias assessment, and iterative model debugging across domains. Future research on extending penultimate-layer proxies deeper into neural architectures could further broaden the impact of these findings.