Verifier-Free RL for LLMs via Intrinsic Gradient-Norm Reward
Published 11 May 2026 in cs.LG and cs.AI | (2605.09920v1)
Abstract: While Reinforcement Learning with Verifiable Rewards (RLVR) has recently emerged as a promising post-training paradigm for LLMs, its dependency on the gold label or domain-specific verifiers limits its scalability to new tasks and domains. In this work, we propose Verifier-free Intrinsic Gradient-Norm Reward (VIGOR), a simple reward that uses only the policy model itself. Given a prompt, VIGOR samples a group of completions and assigns higher within-group rewards to outputs that induce smaller $\ell_2$ norms of the teacher-forced negative log-likelihood gradients under the current parameters. Intuitively, lower gradient norms suggest the completion aligns better with the current policy, serving as an intrinsic preference signal for policy optimization. To make this intrinsic signal practical for RL, we correct the systematic length bias of averaged token-level gradients with a $\sqrt{T}$ scaling, and apply group-wise rank shaping to stabilize reward scales across prompts. Across mathematical reasoning benchmarks, VIGOR outperforms the state-of-the-art Reinforcement Learning from Internal Feedback (RLIF) baseline, and it also exhibits cross-domain transfer to code benchmarks when trained only on math data. For instance, on Qwen2.5-7B-Base post-trained on MATH, VIGOR improves the average math accuracy by +3.31% and the average code accuracy by +1.91% over this baseline, while exhibiting more stable training dynamics. The code is available at https://github.com/ZJUSCL/VIGOR.
The paper introduces VIGOR, a method using gradient-norm rewards derived from a model’s training dynamics to guide post-training without external verifiers.
It employs length bias correction and groupwise rank normalization to stabilize reward signals and prevent exploitation during reinforcement learning.
Experimental results show significant gains in math and code benchmarks, validating its effectiveness over traditional and other intrinsic reward methods.
Verifier-Free Reinforcement Learning for LLMs via Intrinsic Gradient-Norm Reward (VIGOR)
Introduction
The research introduces VIGOR, a novel reinforcement learning (RL) framework for post-training LLMs that entirely eliminates reliance on external, domain-specific verifiers or gold labels. Traditional RL approaches for LLM post-training, particularly in domains such as mathematical reasoning and code synthesis, have depended on programmatic verifiers or exact-match answer checking to generate reward signals. These dependencies restrict the scalability of RL protocols to open-ended or under-resourced tasks. Recent alternatives have turned to majority-voting or entropy-based intrinsic rewards, but they suffer from limited applicability, instability, or are susceptible to reward exploitation as policies adapt.
VIGOR proposes using the policy model’s own parameter-space training dynamics as an intrinsic reward. For each sampled completion to a prompt, the method computes the ℓ2 norm of the gradient (with respect to the model parameters) of a mean negative log-likelihood (NLL) loss. Outputs inducing lower gradient norms are preferred, as they indicate alignment with the current model’s “stationary regions” and are hypothesized to reflect more stably learnable or consistent behaviors.
Figure 1: The VIGOR intuition: completions yielding small gradient norms are assumed to better align with the current model, and are rewarded accordingly.
Methodology
The objective is to incentivize LLM behaviors that maximize downstream utility without access to external correctness signals. Given a prompt x and sampled completions {yi}:
Per-Completion Gradient Norm Computation: For each yi, compute the mean-token NLL loss and obtain its gradient norm ∥g(x,yi)∥2.
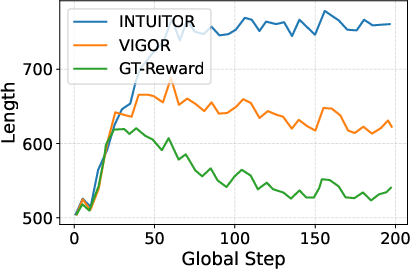
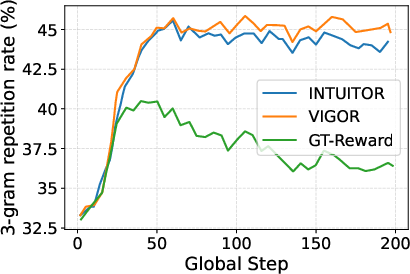
Length Bias Correction: Without normalization, gradient norms decrease with output length due to averaging, leading to “length hacking.” Empirically, scaling by T (where T is completion length) neutralizes this bias and ensures reward signals are length-invariant.
Groupwise Rank-Based Reward Shaping: For a group of completions, their (corrected) gradient norms are rank-normalized across the group to [−1,1], ensuring stable relative reward assignment and addressing inter-prompt variability.
This intrinsic reward is then integrated with a Group Relative Policy Optimization (GRPO) framework, which is conceptually close to PPO but computes per-sample standardized advantages within each prompt group.
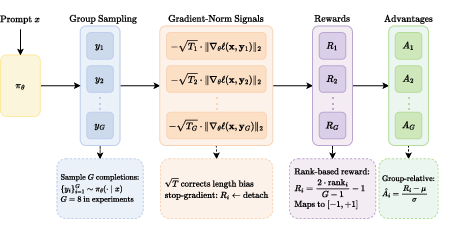
Figure 2: The VIGOR RL post-training pipeline: gradient norms are computed, length-corrected, and mapped to intra-group rewards which are then used for policy optimization.
A stop-gradient operation ensures that the intrinsic reward signal is held constant through policy optimization, maintaining a tractable first-order update.
Experimental Evaluation
Experimental Design
VIGOR was evaluated on Qwen2.5-3B and Qwen2.5-7B base models, leveraging MATH and CodeContests for training and an extensive benchmark suite—GSM8K, MATH500, AMC (math), LiveCodeBench, CRUX (code), MMLU-Pro (multi-task), and IFEval (instruction following)—for evaluation. The method was compared against standard RL post-training with verifiable ground-truth rewards (GT-Reward) and the recent verifier-free RLIF baseline "INTUITOR," which uses policy likelihood (self-certainty) as an intrinsic reward.
Main Results
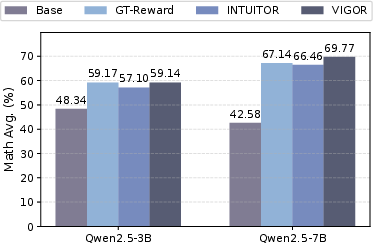
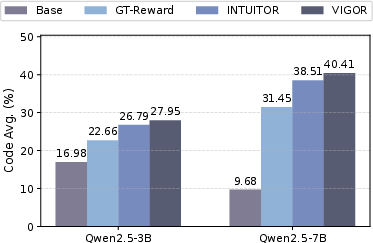
VIGOR consistently yields robust improvements on both in-domain and cross-domain tasks. On Qwen2.5-7B-Base post-trained on MATH, average math accuracy increased from 42.58% (base) to 69.77% (VIGOR), surpassing INTUITOR by +3.31 percentage points. Notably, cross-domain code benchmarks improved by +1.91 points compared to INTUITOR, despite training exclusively on math tasks.
Figure 3: Average performance on math benchmarks for Qwen2.5 models post-trained with VIGOR and baselines.
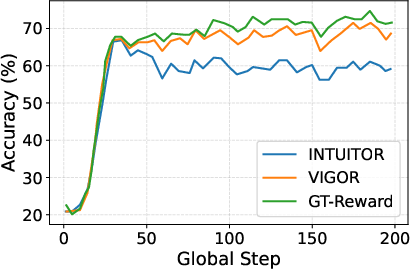
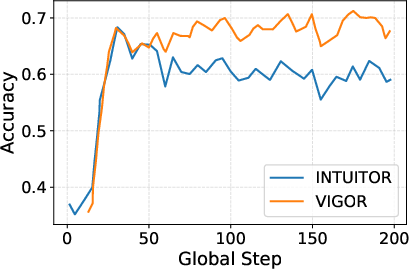
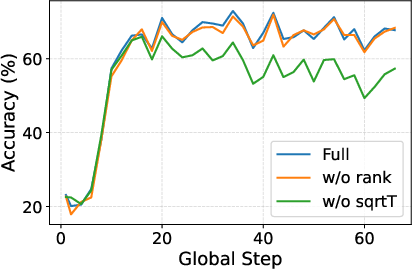
Figure 4: Training accuracy dynamics, demonstrating improved stability and higher ultimate accuracy for VIGOR compared to verifier-free RLIF.
VIGOR’s improvements are most pronounced in math domains but also carry over to code, multi-task, and instruction evaluation. The method demonstrates stable training behavior (in contrast to marked late-stage accuracy collapse for RLIF methods), and top-25% reward-ranking alignment with correctness remains high throughout training, indicating resistance to reward degeneration.
Ablation Studies
Crucially, ablation demonstrates:
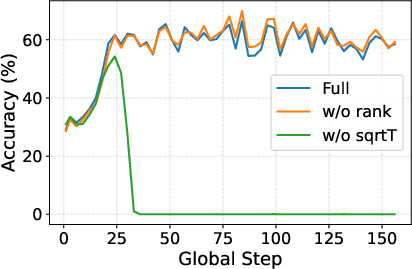
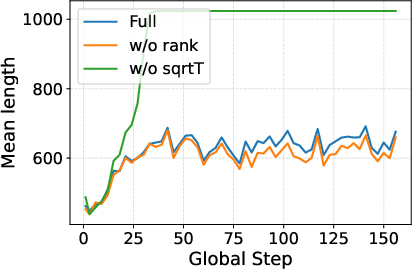
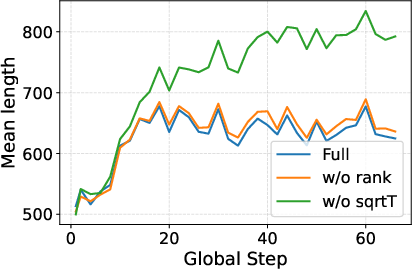
Length correction (T) is essential—removing it causes accuracy collapse and severe length hacking, confirming that raw gradient norm is trivially exploitable.
Groupwise rank normalization reduces reward outlier sensitivity and is vital for generalization on larger models and multi-task settings.
Variants such as LM-head-only gradient-norm computation retain nearly all performance while significantly reducing compute/memory requirements.
Figure 5: 3B model accuracy under ablations, illustrating that absence of length correction (T) induces rewards that drive degenerate solutions.
Theoretical and Practical Implications
This work reframes RL post-training for LLMs as a verifier-free problem using parameter-space metrics. The gradient-norm reward correlates with behavioral stationarity, resulting in smoother training and higher reliability, as shown by empirical stability and rank–accuracy monotonicity. Practically, this eliminates the need for gold or programmatic verifiers, broadening the reach of RL-based post-training to open-ended or under-resourced domains. The effectiveness of VIGOR’s reward shaping and the simplicity of its integration into policy optimization pipelines make it viable for further adoption in LLM training workflows.
Theoretically, these results support intrinsic reward approaches grounded in optimization landscape geometry, aligning with first-order stationary behavior as an implicit supervision signal.
Limitations and Future Directions
While robust for mathematical and code-based reasoning, it remains unresolved how well VIGOR extends to less verifiable, open-ended generation tasks such as dialogue or long-form text. There is also a non-trivial compute overhead due to the per-completion gradient computation—albeit partially mitigated with LM-head-only calculation. Finally, as gradient norm is still an imperfect proxy for downstream utility, pathological reward hacking remains possible, requiring future research into reward regularization and further correlates of human utility.
Conclusion
VIGOR presents a significant advance in verifier-free RL for LLMs, demonstrating that intrinsic, length- and rank-normalized gradient-norm rewards yield stable and transferable improvements across math, code, and multi-task settings. Its results suggest that parameter-space signals can serve as reliable supervision even in the absence of ground-truth answers or verifiers, with strong empirical stability and performance.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.