- The paper introduces CTQWformer, a framework that integrates continuous-time quantum walk dynamics with graph Transformer and GNN architectures to enhance classification performance.
- It employs a Quantum Walk Encoder, Transformer bias injection through CTQW propagation probabilities, and a recurrent module to capture both static and dynamic information from graphs.
- Empirical evaluations on six benchmark datasets show state-of-the-art results, particularly in bioinformatics, highlighting the benefits of embedding quantum-inspired dynamics.
Introduction
CTQWformer introduces a novel framework for graph classification by integrating continuous-time quantum walk (CTQW) dynamics with graph neural network (GNN) and Transformer architectures. The model is motivated by the limitations of both GNNs—such as their struggle with capturing global topological dependencies and over-smoothing—and graph Transformers, which, despite their prowess in modeling long-range dependencies, often overlook nuanced local structural information. CTQWformer leverages the physically grounded dynamics of CTQW, a quantum analogue of classical random walks governed by the Schrödinger equation, to encode rich, non-trivial structural and dynamical information into representations suitable for graph classification.
Model Architecture
At the core, CTQWformer comprises three synergistic components: the Quantum Walk Encoder (QWE), the Quantum Walk-Graph Transformer (QWGT), and the Quantum Walk-Graph Recurrent (QWGR) module. This hybrid framework allows the model to integrate both static, physically grounded structural biases from quantum dynamics and dynamic temporal evolution patterns into deep trainable representations.
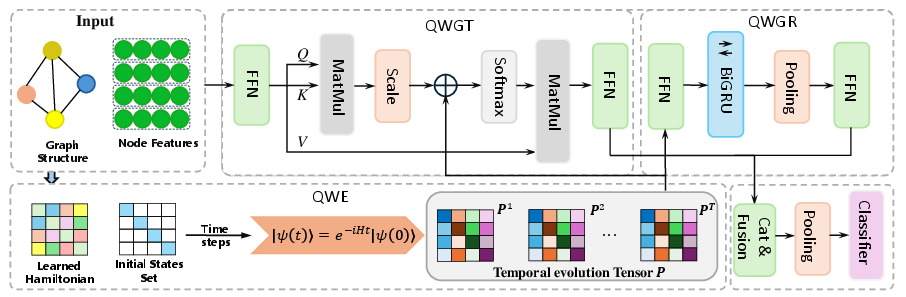
Figure 1: Schematic of CTQWformer. QWE encodes CTQW-based structure and features; QWGT injects final-time CTQW propagation probabilities as Transformer bias; QWGR captures node-level CTQW temporal evolution using BiGRU; outputs are layer-wise fused and pooled for classification.
Quantum Walk Encoder (QWE)
QWE simulates the temporal evolution of CTQW on attributed graphs using a parameterizable, trainable Hamiltonian that fuses graph topology and node features via an edge-dependent, neural-parameterized weighting scheme. The CTQW evolution for each graph yields a temporal tensor P∈RT×n×n, stacking node propagation probability matrices across T discrete time steps. This enables the encoding of both graph connectivity and dynamic propagation patterns into a differentiable representation space, making the CTQW process fully amenable to end-to-end learning.
QWGT addresses the limitations of vanilla graph Transformers in capturing intrinsic structural information. By integrating the final-time CTQW propagation probability matrix (PT) as an explicit, normalized, log-scaled additive bias within the attention computation, QWGT enforces that attention weights reflect not just feature similarity but also structural relationships uncovered by quantum walks. This explicit CTQW bias provides a deterministic, physically interpretable inductive bias, enhancing the model's ability to capture global graph topology in its learned representations.
Quantum Walk-Graph Recurrent (QWGR)
QWGR complements the QWGT by modeling the inherently oscillatory, non-convergent temporal dynamics of CTQW. For each node, it extracts the diagonal (self-propagation) probabilities from the CTQW tensor across all time steps, yielding temporal node evolution sequences. These are processed through a bidirectional GRU (BiGRU), capturing both forward and backward temporal correlations. Aggregation across nodes results in a graph-level dynamical embedding.
The outputs of QWGT and QWGR are concatenated and fused, thereby combining static quantum-structural and dynamic-temporal features. This fusion is repeated across stacked layers, with global mean pooling and a classifier producing the final graph prediction.
Computational Complexity Analysis
CTQWformer incurs an O(Tn3) time complexity in simulating CTQW for n nodes over T time steps, primarily due to matrix exponentiation and dense evolution tensor storage (O(Tn2)). The QWGT module follows Transformer scaling: O(BL(n2h+nh2)) for B batch size, L layers, T0 embedding dimension. QWGR’s primary cost is associated with BiGRU processing (T1), though diagonal extraction and projection are sub-dominant. The end-to-end cost is dominated by CTQW simulation for moderate/large graphs, with QWGT dominating inference for smaller-to-moderate graphs.
Experimental Evaluation and Numerical Results
CTQWformer was empirically evaluated on six benchmark datasets spanning bioinformatics and social networks, including MUTAG, PTC(MR), PROTEINS, DD, IMDB-B, and IMDB-M. Node features were normalized and supplemented as per common GNN practices. Evaluation utilized 10-fold cross-validation, with hyperparameters tuned by grid search and early stopping.
Key Numerical Outcomes: Across five of six datasets, CTQWformer achieved state-of-the-art performance:
- MUTAG: 92.54 ± 5.39% (best, surpassing all GNN and kernel baselines)
- PTC(MR): 69.16 ± 5.17%
- PROTEINS: 78.53 ± 2.34%
- DD: 81.24 ± 3.43%
- IMDB-B: 76.40 ± 1.91%
- IMDB-M: 47.47 ± 7.84% (comparable, not best)
These results show that CTQWformer consistently outperforms both traditional R-convolution and CTQW-based graph kernels, as well as leading GNN and Transformer baselines, especially in bioinformatics domains. The largest observed gains are on datasets with rich node features, underscoring the benefit of joint topology/feature-aware CTQW modeling.
Ablation studies showed that omitting the QWGR (dynamic) module leads to a drastic performance drop (e.g., MUTAG falls to 74.97%), substantiating the necessity of capturing temporal quantum dynamics, while the static bias (QWGT) offers moderate contributions.
Sensitivity and Hyperparameter Analysis
Comprehensive sensitivity experiments were conducted varying time steps (T2) and network depth (T3):
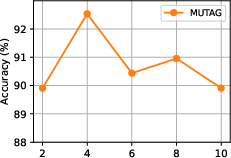
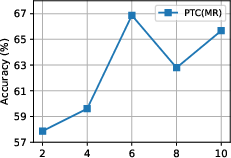
Figure 2: Influence of CTQW time steps T4 on classification accuracy (MUTAG, PTC(MR)).
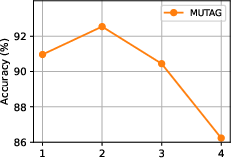
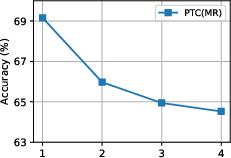
Figure 3: Influence of CTQWformer depth T5 on classification accuracy (MUTAG, PTC(MR)).
- Best performance typically occurs with a moderate T6 (e.g., T7 for MUTAG; T8 for PTC(MR)), indicating a tradeoff between capturing sufficient CTQW evolution and over-smoothing due to excessive quantum interference.
- Network depth T9 is generally optimal; deeper networks lead to overfitting or representational collapse on small-scale datasets.
Theoretical and Practical Implications
CTQWformer’s design offers several fundamental and applied implications:
- Physical Inductive Bias: Injecting CTQW-based structural priors into attention mechanisms provides a physically interpretable, data-driven bias, enriching the expressivity of graph Transformers beyond purely data-adaptive mechanisms.
- Temporal Evolution Modeling: By explicitly modeling CTQW’s non-convergent, oscillatory node evolution, CTQWformer captures temporal dependencies and multi-path interference effects, which are inaccessible to classical message-passing or static random walk models.
- Task Generality: The joint architecture is applicable to general attributed graphs and can potentially be adapted for node classification or link prediction tasks, suggesting its extensibility.
- Scalability Considerations: The primary computational bottleneck remains CTQW simulation, especially for large-scale graphs. Approximations or sparse methods for quantum evolution may enable practical deployment in industrial-scale settings.
Perspectives and Future Directions
The integration of differentiable quantum walk dynamics into deep graph representation learning sets a new paradigm for physically informed, end-to-end trainable architectures. Promising directions include improving CTQW simulation efficiency, exploring integration with discrete-time or hybrid quantum walks, extending to heterogeneous or dynamic graphs, and developing hardware implementations for quantum-inspired computation in graph learning.
Conclusion
CTQWformer pioneers the combination of continuous-time quantum walk dynamics with Transformer-based graph representation learning, achieving strong empirical performance and offering a fruitful fusion between quantum-inspired inductive biases and deep geometrical learning. Its layered fusion of static and dynamic quantum-derived features provides a new avenue for capturing both local and global graph characteristics, and its extensibility promises ongoing relevance for theoretical and applied research in graph machine learning.

