- The paper presents a novel image quality metric, ML-CLIPSim, that leverages multi-layer CLIP embeddings to quantify latent machine utility.
- It employs pairwise predictive-consistency supervision on the PCMP dataset to obtain soft preference labels from diverse downstream models.
- ML-CLIPSim outperforms traditional and deep perceptual metrics in optimizing rate–task trade-offs in learned image compression and various vision tasks.
Machine-Oriented Image Quality Assessment via Multi-Layer CLIP Similarity
Motivation and Background
Traditional IQA frameworks predominantly focus on signal fidelity or human perceptual alignment, often employing metrics such as PSNR, SSIM, and more recent feature-based approaches (e.g., LPIPS, DISTS). However, the emergence of machine-vision pipelines—where images are consumed by downstream models like classifiers, detectors, segmenters, and VLMs—necessitates rethinking IQA objectives. Notably, distortions yielding comparable fidelity scores can induce disparate model behaviors. Thus, a quality metric optimized for visual similarity does not guarantee preservation of information critical for robust machine prediction. This paper proposes a paradigm shift: machine-oriented image quality assessment, characterized by latent machine utility that quantifies the preservation of prediction-relevant information across a population of downstream models.
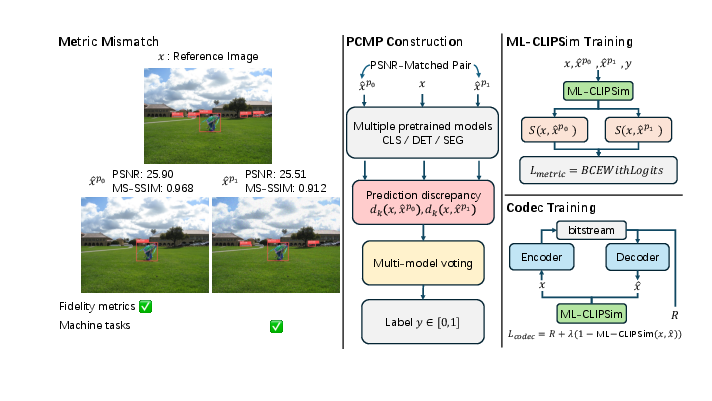
Figure 1: Schematic of the proposed pipeline, highlighting the misalignment between traditional fidelity metrics and actual downstream model behavior, the construction of PSNR-matched distortion pairs and soft labels via multi-model voting, and the deployment of ML-CLIPSim for learned image compression.
Predictive Consistency Dataset for Machine Perception (PCMP)
The authors operationalize latent machine utility through pairwise predictive-consistency supervision. The PCMP dataset is constructed by sampling PSNR-matched distortion pairs (to eliminate confounding from distortion magnitude) and deriving continuous soft preference labels via predictive-consistency voting from a heterogeneous model pool (classifiers, detectors, segmenters). Distortions span classical codecs, learned codecs, blur/noise, resampling, and color/tone shifts. Each pair receives a label proportional to the fraction of models preferring one variant over the other, thus reflecting aggregate consensus on task-relevant preservation.
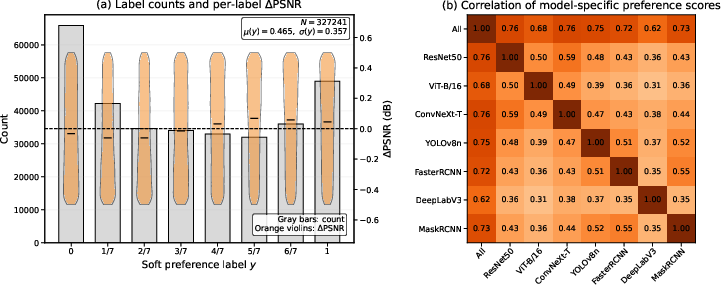
Figure 2: Distribution of preference labels and PSNR differences, and model-level correlation matrix on PCMP, demonstrating broad label diversity and substantial cross-model consistency in preference trends.
This framework circumvents the pitfalls of absolute quality scores—which are not naturally calibrated across models and tasks—by leveraging soft pairwise comparisons. Such an approach enables scalable supervision without human annotation, robustly addressing the heterogeneity intrinsic to machine-oriented quality.
ML-CLIPSim: Multi-Layer CLIP Similarity Metric
ML-CLIPSim is a differentiable, full-reference IQA metric trained on PCMP supervision. Unlike prior methods relying solely on final-layer global CLIP embeddings, ML-CLIPSim aggregates multi-layer patch-token similarities and global image embeddings extracted from a frozen CLIP visual encoder (ViT-B/16). This architecture is motivated by the necessity to capture both localized evidence degradation (e.g., object boundaries, textures) and high-level semantic consistency—key determinants of downstream model stability.
The metric computes mean cosine similarity between corresponding patch tokens across layer groups (early, middle, late), with learnable softmax-weighted aggregation, and combines it with global embedding similarity via a learnable gate. This structured representation enables ML-CLIPSim to accurately mirror latent machine utility as indicated by multi-model consistency votes.
Quantitative Evaluation
ML-CLIPSim demonstrates strong numerical superiority on PCMP: accuracy (0.8284), SRCC (0.7937), KRCC (0.6182), and PLCC (0.7364), outperforming PSNR, MS-SSIM, LPIPS, DISTS, and global CLIP similarity. This aligns with the bold claim that deep feature-based metrics trained via multi-model predictive consistency more reliably predict machine utility than both classical and learned perceptual metrics.
Cross-dataset generalization is validated on MPD, where ML-CLIPSim yields consistent improvements over DISTS, LPIPS, and CLIPScore across severe/mild distortion, NSI/SCI/AIGI, YoN/MCQ/VQA/CAP, and other subsets.
Importantly, ML-CLIPSim achieves competitive correlation with human opinion scores on TID2013 and LIVE IQA datasets, reflecting partial overlap between human and machine-oriented quality despite the distinct supervision protocol. This underscores the metric's versatility and potential for broad deployment.
Machine-Oriented Learned Compression
ML-CLIPSim is directly employed as a distortion term for learned image compression, optimizing codecs (MLIC++) for downstream task performance rather than conventional rate--distortion objectives. Comprehensive evaluation across ImageNet, VOC, COCO, and VLM benchmarks (SEEDBench, POPE) reveals that ML-CLIPSim-attuned codecs consistently achieve the best rate--task trade-offs versus strong baselines including UG-ICM and CLIPScore.
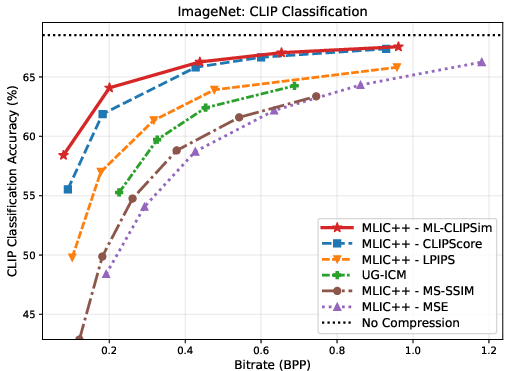
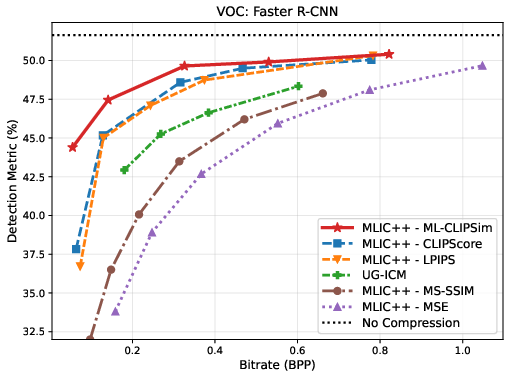
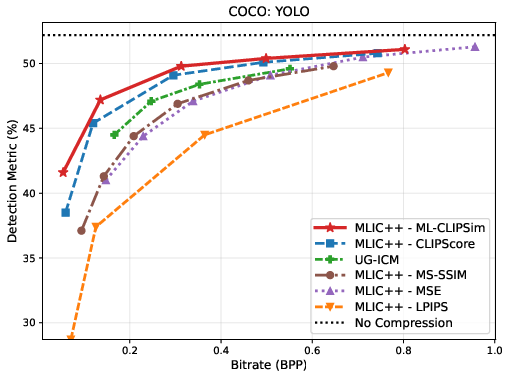
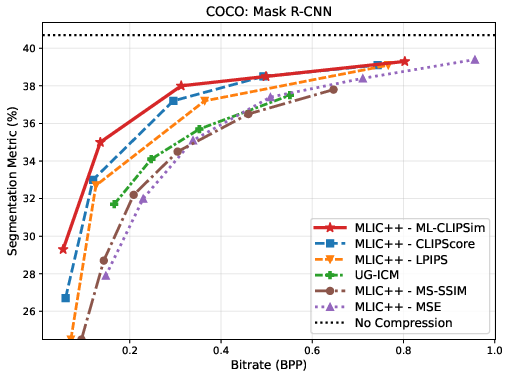
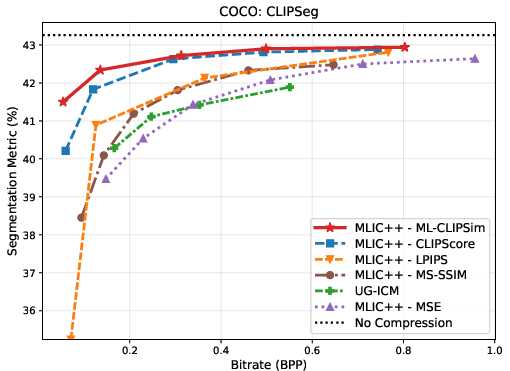
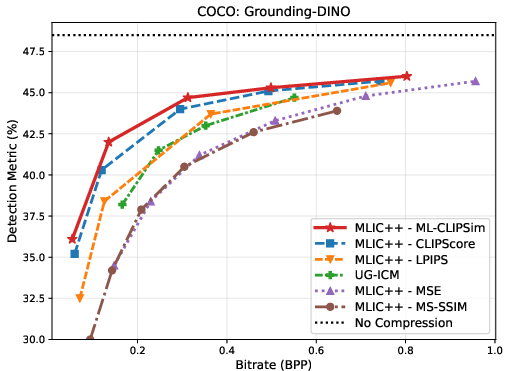
Figure 3: Rate--task curves on ImageNet, VOC, and COCO, indicating superior trade-offs across classification, detection, and segmentation tasks when ML-CLIPSim is used for compression optimization.
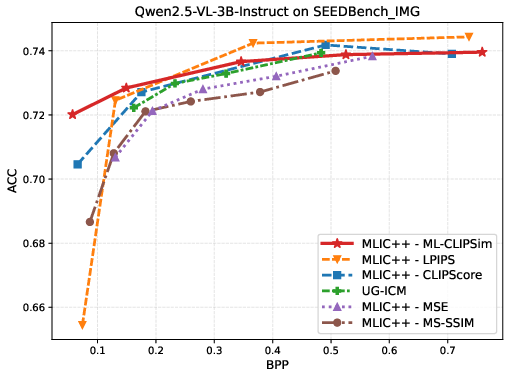
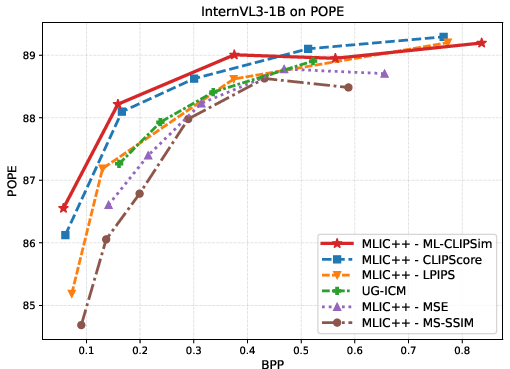
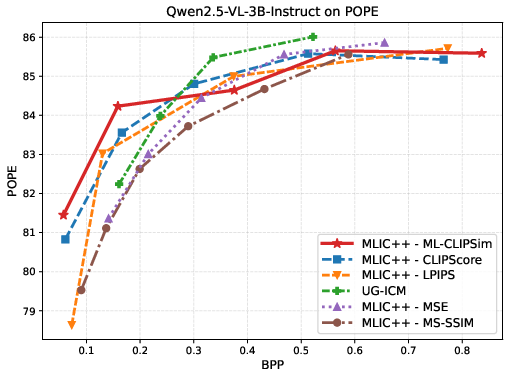
Figure 4: VLM evaluation on SEEDBench and POPE with InternVL3-1B and Qwen2.5-VL-3B-Instruct, showing ML-CLIPSim's dominance in rate--task performance.
BD-Rate experiments reinforce these findings: ML-CLIPSim yields large negative BD-Rate improvements (up to −80.7%), confirming its effectiveness in preserving model-relevant information at reduced bitrate across diverse machine-vision tasks.
Ablation and Architectural Contributions
An ablation study highlights critical design choices: multi-layer token modeling, group-wise aggregation, and soft pairwise supervision all contribute significant gains over baseline global CLIP similarity. This empirically validates the claim that structured, learned aggregation over hierarchical CLIP features is essential for robust, machine-driven quality estimation.
Implications and Future Directions
The ML-CLIPSim framework embodies a scalable, differentiable surrogate for latent machine utility, enabling model-agnostic, task-agnostic evaluation and optimization. Practically, this unlocks new research avenues in utility-preserving compression, systematic benchmarking, and cross-task IQA. Theoretically, the paper advances understanding of the divergence between human- and model-centric quality and proposes a principled approach to bridging this gap.
Possible extensions include adaptive integration of ML-CLIPSim into end-to-end vision pipelines, direct optimization for specific downstream analytics, and expansion of the PCMP protocol to cover more diverse models and tasks (e.g., multi-modal inference, medical imaging pipelines).
Conclusion
This study introduces the PCMP dataset and ML-CLIPSim metric, rigorously redefining IQA from a machine-centric perspective. Empirical results substantiate the superiority of ML-CLIPSim in aligning with latent machine utility and improving downstream analytics across tasks and codec architectures. The dataset and the metric lay the groundwork for further research in machine-oriented IQA, utility-driven compression, and task-agnostic visual communication (2605.09479).