- The paper introduces a comprehensive taxonomy categorizing attention-based graph neural networks into GRANs, GATs, and Transformer architectures.
- It details the methodological evolution from recurrent to local and global attention, highlighting benefits like parallelism and enhanced expressivity.
- The survey identifies scalability, interpretability, and depth as key challenges, setting clear directions for future research in diverse applications.
Comprehensive Survey of Attention-based Graph Neural Networks
Introduction and Motivation
Attention-based mechanisms have rapidly transformed the landscape of graph representation learning. The survey "Attention-based graph neural networks: a survey" (2605.08679) provides an exhaustive taxonomy and technical review of the integration of attention within GNN architectures, systematically covering developmental history, architectural variants, and practical implications. Unlike prior fragmented summaries, this work establishes a two-level taxonomy, organizing the field by developmental stages and architectural perspectives, and synthesizes the merits, limitations, and open challenges of attention-based GNNs for diverse data modalities and downstream tasks.
Taxonomy and Developmental Stages
The survey delineates three principal developmental stages for attention-based GNNs: Graph Recurrent Attention Networks (GRANs), Graph Attention Networks (GATs), and Graph Transformers. Each stage is characterized by distinct aggregation strategies, scalability properties, and theoretical expressiveness:

Figure 1: Three developmental stages of attention-based graph neural networks highlight the shift from recurrent architectures to localized neighborhood attention and finally to global-attentive, transformer-based models.
GRANs employ attention mechanisms within RNNs (GRU/LSTM) to learn node and graph representations, but inherit recursive bottlenecks and sequential ordering constraints. GATs adopt local neighborhood attention (e.g., masking, feed-forward alignments) that enable parallelism, robust weighting of neighbors, and improved handling of graph noise. Graph Transformers generalize the transformer paradigm to graph domains, positing global self-attention for direct modeling of long-range dependencies, but incur severe computational complexity in large-scale graphs.
Data Modalities and Message Passing
Graph-structured data encompasses sequence, grid, and general relational topologies. Standard GNNs utilize spatial and spectral message-passing mechanisms, leveraging adjacency and feature matrices for iterative aggregation and update operations:
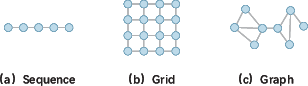
Figure 2: Examples demonstrate the structural heterogeneity among sequence-structured, grid-structured, and graph-structured data.
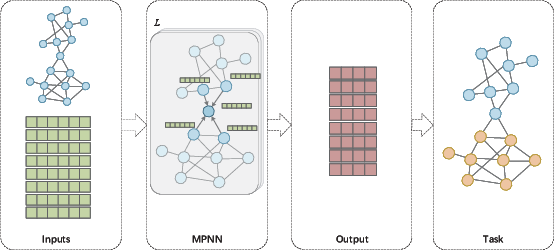
Figure 3: Message-passing architecture illustrates neighborhood aggregation, update functions, and propagation across layers.
The attention mechanism is formalized as an adaptive weighting framework, with alignment, distribution, and weighted sum functions. Attention can be local (neighborhoods), global (all nodes), or fusion-based (cross-feature spaces):
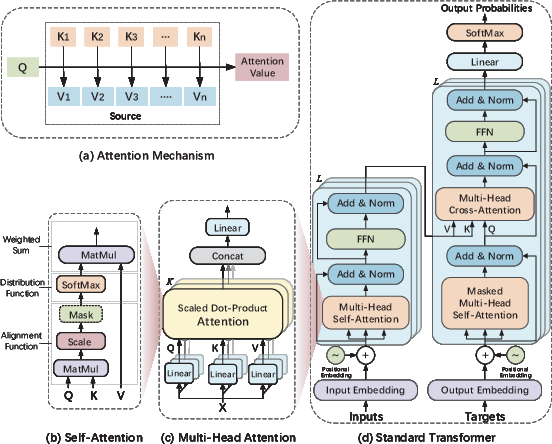
Figure 4: Modular architecture of attention, self-attention, multi-head attention, and standard transformer layers.

Figure 5: Local attention distinguishes immediate neighbors, global attention encompasses all nodes, and feature fusion integrates multiple representations.
Architectural Classification
A detailed classification of attention-based GNNs captures the proliferation of architectural choices, including intra-layer and inter-layer GATs, higher-order and relation-aware attention, hierarchical schemes, attention-guided sampling/pooling, and hypergraph-attentive extensions:
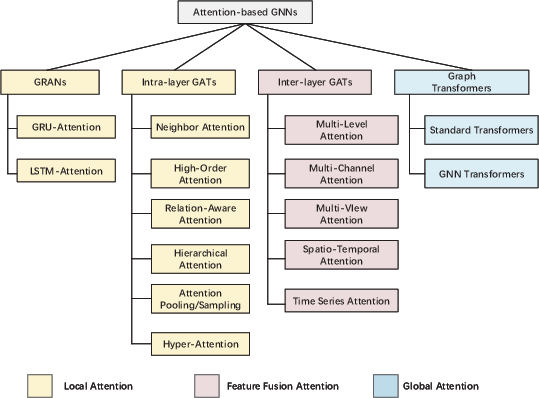
Figure 6: Taxonomy provides a hierarchical breakdown of attention-based GNN methods by developmental stage and architectural subcategories.
Intra-layer and Inter-layer GATs
Intra-layer GATs operate local attention within the single neural network layer, while inter-layer GATs perform feature fusion across multiple layers, channels, views, or spatio-temporal slices. Higher-order attention and path-based aggregation mitigate the neighborhood locality bottleneck:
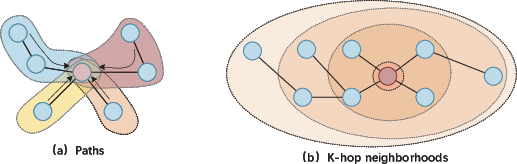
Figure 7: Aggregation mechanisms for higher-order message passing span meta-paths and multi-hop neighborhoods.
Relation-aware and Hierarchical Attention
Relation-aware GNNs extend attention to encode signed edges, multi-relational heterogeneity, and knowledge graph logic:
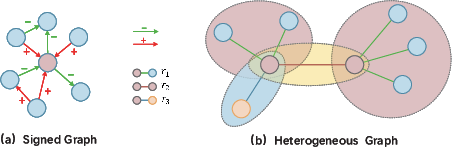
Figure 8: Signed graphs and heterogeneous graphs exemplify relation-aware neighborhood modeling.
Hierarchical attention models multiple levels (node/path/relation/group) for fine-grained semantic aggregation:
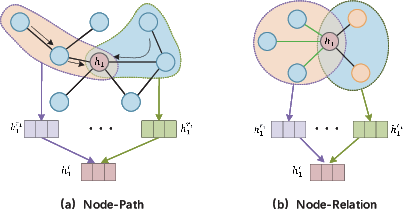
Figure 9: Stacked hierarchical attention layers operate over node-path and node-relation hierarchies.
Sampling, Pooling, and Hypergraphs
Attention-based sampling improves efficiency for large graphs and is utilized in message aggregation. Pooling leverages attention for selection and hierarchical readout:
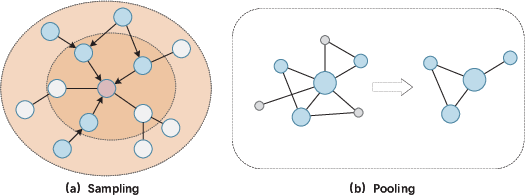
Figure 10: Sampling and pooling demonstrate attention-enabled node selection and graph-level readout.
Hyper-attention mechanisms generalize GNNs to hypergraphs, modeling multi-node interactions:
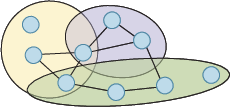
Figure 11: Hypergraph architectures encode complex, higher-order relationships via attention across variable-size hyper-edges.
Feature Fusion: Multi-level, Multi-channel, Multi-view
Attention facilitates fusion from multiple receptive fields, channels (frequency information), and views (topological variations):
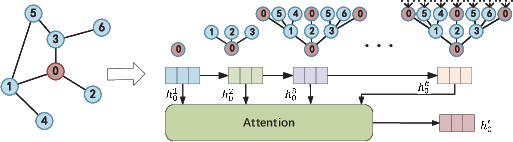
Figure 12: Multi-level attention integrates representations from different neighborhood orders.
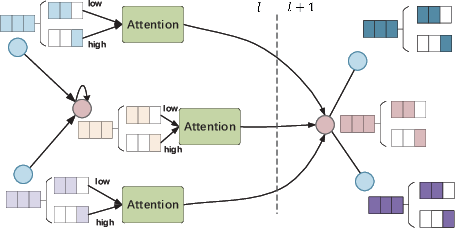
Figure 13: Multi-channel attention adapts aggregation of low/high-frequency signals.
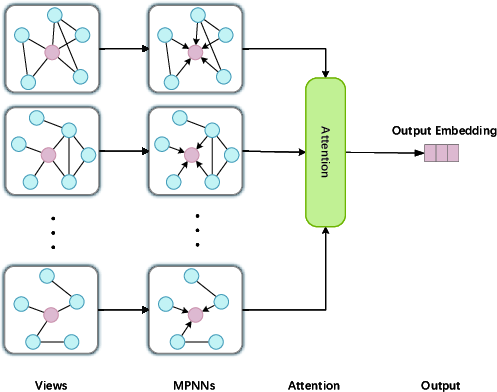
Figure 14: Multi-view attention fuses representations from diverse graph constructions.
Spatio-temporal and time-series attention-based GNNs explicitly model evolution and dependencies across time slices and spatial relations:
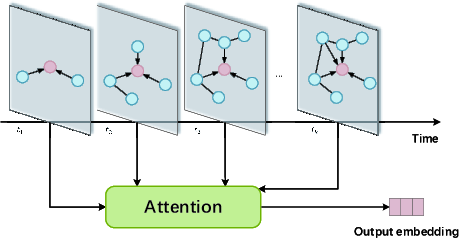
Figure 15: Spatio-temporal attention fuses time-sliced messages in dynamic graphs.
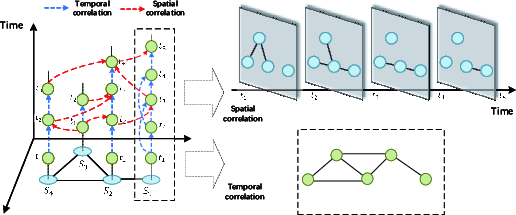
Figure 16: Graph-based modeling of time series incorporates temporal and spatial correlations.
Graph Transformers offer global attention, fully connecting all nodes and ignoring explicit adjacency matrices:
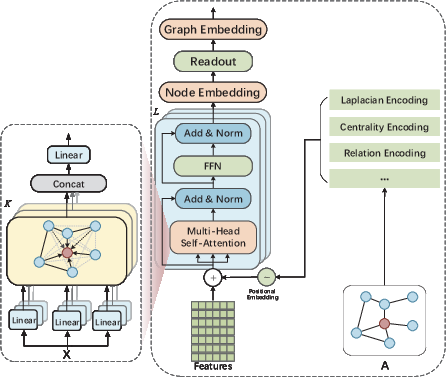
Figure 17: Graph Transformer architecture visualizes global self-attention analogous to fully-connected GATs.
GNN Transformers combine explicit neighborhood aggregation and transformer-style attention:
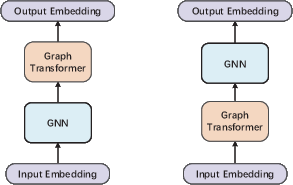
Figure 18: Serial/parallel stacking of GNN and transformer layers enables local-global message fusion.
Comparative Analysis and Discussion
The survey systematically compares the characteristics and expressivity of major attention-based GNN subclasses, examining local/global aggregation, path-awareness, relational structure, temporal processing, and reliance on prior knowledge. Computational complexity is addressed, emphasizing recursive bottlenecks in GRANs, parallelism in GATs, and the prohibitive scaling issues for Graph Transformers.
Key claims include the limitation of traditional GNNs for long-range dependencies, necessity of attention for dynamic and heterogeneous graphs, and the critical tradeoff between expressivity (global modeling) and scalability (parallelism/sparsity).
Open Challenges and Future Directions
The paper identifies several open issues:
- Scalability: High computational cost of global attention impedes real-world deployment in massive graphs. Sampling, subgraphing, and approximate attention are promising, but incomplete.
- Interpretability: Theoretical understanding of attention-based GNN discriminative power remains superficial; formal analysis and motif/subgraph explainability are required for trust and adoption.
- Deeper Models: Over-smoothing and over-squashing in deep stacks necessitate architectural innovations (decoupling transformation/propagation, global attention, higher-order structures).
- Complex Graphs: Universality for complex (heterogeneous, temporal, hypergraph) structures is an open challenge; current models require extensive adaptation.
- Novel Applications: While attention-based GNNs have demonstrated efficacy for NLP, CV, traffic, recommendation, and multimodal systems, further generalization to combinatorial optimization and biochemical graphs is anticipated.
Conclusion
This survey constitutes a definitive technical reference for attention-based GNNs, detailing architectural evolution, specialized attention mechanisms, and challenges for practical scalability and interpretability. Immediate research priorities include formal complexity-accuracy tradeoff analyses, universal attention mechanisms for heterogeneous and temporal graphs, and interpretable attentional explanations. As graph-structured data has become pervasive, the ongoing refinement of attention-based GNNs will critically shape AI systems capable of dealing with relational, dynamic, and multi-modal environments.