- The paper proposes ETCTrack, which introduces an adaptive token compression module coupled with a hierarchical interaction encoder to eliminate redundancy in visual tracking.
- The methodology employs a learnable global attention mechanism to prune up to 60% of tokens, achieving significant computational savings with negligible accuracy loss.
- Empirical evaluations on benchmarks like GOT-10k and LaSOT demonstrate that ETCTrack achieves state-of-the-art performance with enhanced speed and robustness.
Efficient Token Compression for Visual Object Tracking: An Expert Analysis
Motivation and Context
Transformer-based visual trackers have achieved substantial robustness and accuracy through the integration of large numbers of historical template frames, enabling richer spatio-temporal context modeling. However, the resulting proliferation of visual tokens induces significant computational overhead and introduces detrimental visual redundancy, limiting practical deployment and hampering performance, particularly in multi-frame settings. This paper proposes ETCTrack, a compress-then-interact framework, which leverages adaptive token compression to efficiently and dynamically eliminate redundancy, followed by hierarchical, deep feature interaction for improved target localization.
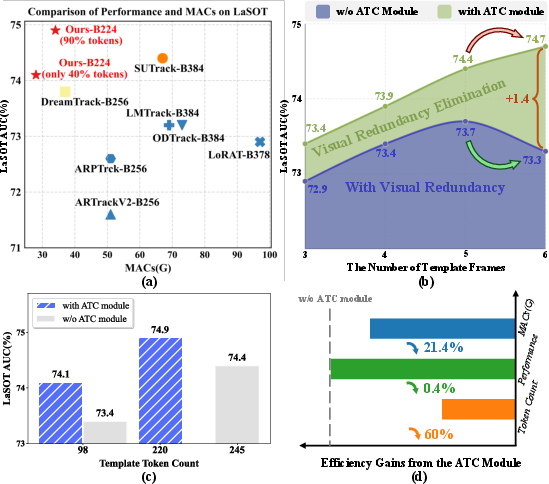
Figure 1: AUC and MACs comparison; performance decline in baseline after 5th frame due to redundancy; ATC impact; ATC efficiency gains.
Framework Overview and Main Contributions
ETCTrack comprises two pivotal modules:
- Adaptive Token Compressor (ATC): The ATC module utilizes a learnable global attention mechanism to assign contextual importance scores to template tokens, dynamically filtering out non-informative and redundant tokens. Instead of relying on handcrafted selection metrics–e.g., fixed spatial heuristics or attention map thresholds–ATC directly optimizes for discriminative features with respect to end tracking objectives, ensuring that only the most informative token subset is retained.
- Hierarchical Interaction Encoder (HIBlock): HIBlock is constructed as a stack of hierarchical blocks designed for deep, asymmetric multi-stage interaction between compressed template and search region tokens. This achieves context-aware enrichment, unified feature modeling, and template-guided refinement, culminating in enhanced features for the prediction head.
The ETCTrack pipeline operates by partitioning both historical template and search frames into patches, embedding them, applying ATC compression to the templates, and then performing hierarchical interaction (see architectural illustration below).
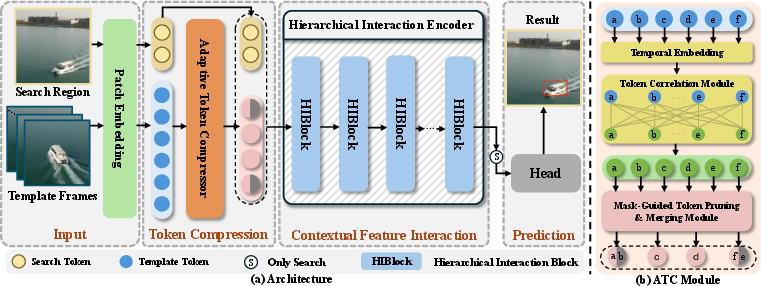
Figure 2: ETCTrack overall architecture and detailed ATC structure.
Adaptive Token Compression Details
ATC receives spatial-temporal template features, restores explicit structure with learnable temporal positional embeddings, and processes them through a Token Correlation Module (TCM) composed of stacked self-attention layers. Following contextualization, a mask-guided pruning and merging mechanism assigns token importance scores via fixed random projections, separating tokens into target and source sets. Low-scored tokens are greedily absorbed into their most semantically similar high-scored tokens based on cosine similarity–a strategy that preserves semantic context without direct discarding. This eliminates up to 60% of tokens with negligible accuracy loss and substantial computational savings.
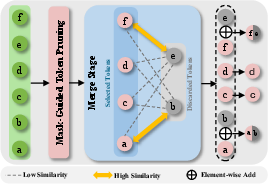
Figure 3: Mask-guided pruning and merging module for token selection.
Hierarchical Interaction Encoder
Feature interaction occurs in a multi-stage, hierarchical manner:
- Compressed template tokens are contextually enriched via cross-attention with search tokens.
- Template and search tokens are concatenated and modeled jointly through backbone blocks.
- Outputs are split, and a template-guided search refinement follows via another cross-attention.
- Final search features undergo convolutional FFN refinement before bounding box prediction.
This design ensures adaptive, deep exchange of spatial-temporal cues, enabling precise localization even with reduced token counts.
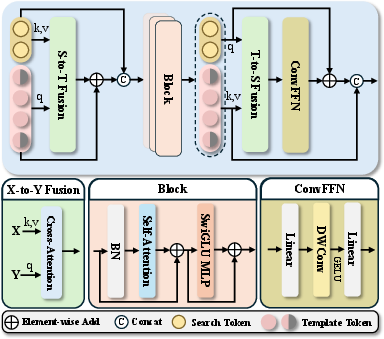
Figure 4: Hierarchical Interaction Block structure.
Empirical Results and Ablations
ETCTrack achieves SOTA performance on seven challenging visual tracking benchmarks: GOT-10k, LaSOT, LaSOT_ext, TrackingNet, TNL2K, NfS, and OTB100. Notable metrics include:
- ETCTrack-B224: 79.2% AO on GOT-10K, a 21.4% reduction in MACs with only a 0.4% accuracy drop compared to non-compressed variants.
- ETCTrack-B384: 75.9% LaSOT AUC, consistently outperforming high-resolution competitors in both accuracy and efficiency.
Ablation studies reveal that both ATC and HIBlock drive substantial gains. The ATC module alone yields +0.7 AUC improvement via redundancy elimination, while the HIBlock provides +0.7 via deep contextual modeling. Their integration is synergistic, with combined performance gains greater than either individually.
On the LaSOT benchmark, the number of template frames initially correlates with improved accuracy; however, beyond five, redundancy leads to performance decline in baseline trackers. With ATC, however, ETCTrack maintains sustained performance, indicating successful redundancy mitigation.
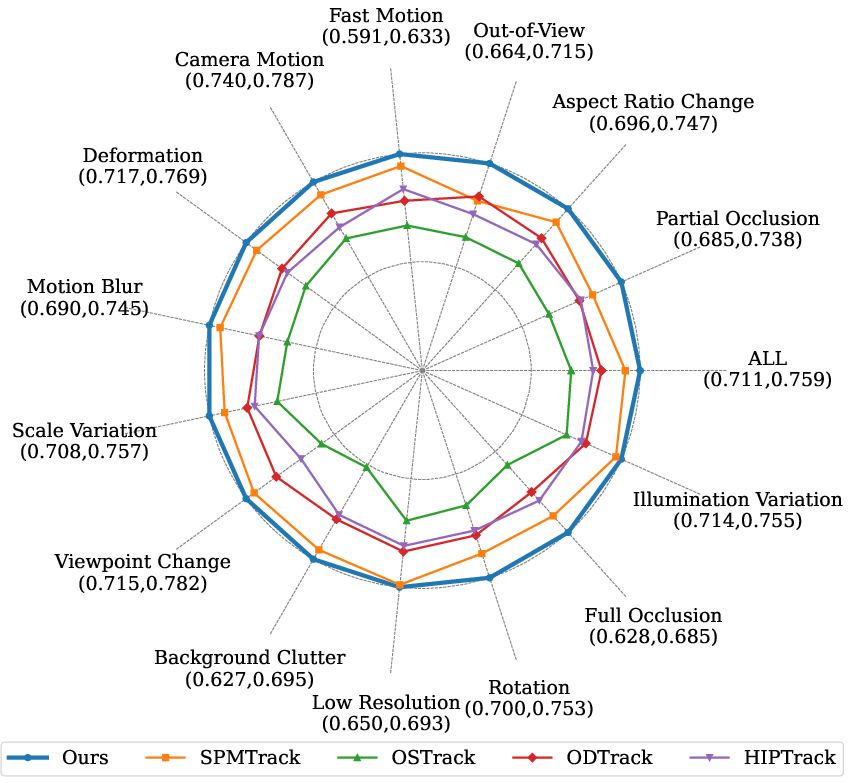
Figure 5: AUC scores for various attributes on LaSOT.
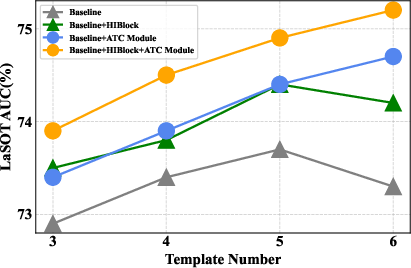
Figure 6: LaSOT AUC as a function of template frame count for ETCTrack variants.
Compressive ratios and architectural variants were analyzed. A keep ratio r of 0.9 eliminates 60% of tokens without accuracy degradation, reducing MACs significantly. The Fast-iTPN backbone and TCM provide optimal tradeoffs between speed and accuracy. Visualizations highlight that token pruning is concentrated in intermediate frames, which are most redundant; initial and latest frames retain more tokens for reliable appearance and dynamic cues.

Figure 7: Visualization of token elimination indicating redundancy pruning in intermediate frames.
Practical and Theoretical Implications
ETCTrack validates that information condensation via explicit token compression is essential for efficiency and performance trade-offs in transformer-based visual tracking. Unlike prior works relying on non-learnable heuristics, the adaptive, context-aware compressor aligns token selection with task objectives and maintains robustness under changing target representations.
In practice, ETCTrack enables high-speed, low-resource deployment of transformer trackers, particularly relevant for edge devices and real-time applications in robotics and surveillance. Theoretically, this work demonstrates the criticality of dynamic token pruning architectures and advances principles from MLLMs into vision-only tracking.
Future Outlook
The authors highlight dynamic, fully adaptive token compression mechanisms as a promising direction, with compression rates modulating in real-time according to tracking complexity or target volatility. Such mechanisms could further optimize latency, robustness, and adaptability for resource-constrained scenarios and volatile environments.
Conclusion
ETCTrack introduces a novel compress-then-interact paradigm for multi-frame visual object tracking, combining adaptive token compression and hierarchical deep feature interaction. Experimental evidence consistently shows state-of-the-art accuracy with drastic computational savings across multiple challenging benchmarks. Future research should pursue dynamic compression strategies and self-adaptive models for further gains in efficiency and robustness.
Citation: "An Efficient Token Compression Framework for Visual Object Tracking" (2605.08329)