- The paper presents a modular RL framework using decomposed state representations to enable efficient foraging with limited computational resources.
- It employs independent multi-armed bandit learners with a Gaussian-weighted voting council to merge sensor-specific actions, reducing memory from exponential to linear scaling.
- Experimental results demonstrate robust, scalable coordination in swarm robotics, even under mis-specified rewards and dense collision scenarios.
Modular Reinforcement Learning for Cooperative Swarms: A Technical Analysis
The paper addresses the challenge of deploying reinforcement learning (RL) for cooperative robot swarms under severe real-world hardware constraints: extremely limited computational resources and restricted communications. In such settings, conventional multi-agent RL (MARL) approaches face state-space explosion, as spatial interaction states scale combinatorially with the number of agents and sensor granularity. Furthermore, the reliance on deep networks for implicit state generalization is infeasible given the hardware limitations (RAM budgets often under 200KB). The paper’s central proposal is a modular, decomposed state representation in which each spatial feature (i.e., the sensor reading in a given direction) is assigned an independent learner and action preference, with a council-based fusion architecture to select the robot’s action. This method linearly scales with the number of spatial features instead of the exponential scaling faced by tabular methods. The work is situated in the context of the canonical swarm foraging problem, where each agent seeks to collect as many pucks as possible and return them to designated bases in arenas of increasing complexity.



Figure 1: Layout of Arenas 1 (center base), 2 (corner base), and 3 (two bases), with pucks and size reference.
Modular RL Architecture
The modular RL framework partitions the robot’s perceptual space by direction. For each sensor (eight in the described experiments), a dedicated learning process selects an action (out of a fixed set of direction vectors, also eight in the experimental evaluation), yielding a significant reduction in memory and computational requirements. Crucially, the action fused from independent learners must be composable—this justifies the use of vectorial actions rather than macro-actions (such as parameterized collision avoidance algorithms), which are not easily amenable to fusion.
Each learner operates a multi-armed bandit algorithm (continuous-time UCB1), choosing a preferred action. All learners are triggered concurrently upon a relevant event (e.g., imminent collision detection by any sensor), and the council merges their preferences via a softmaxed Gaussian-weighted voting scheme, promoting compounding and compromise in motion direction.
Experimental Validation
Extensive evaluations were conducted in high-fidelity simulations. Three arena setups were used to vary the density and structure of agent interactions.
- Arena 1: Single centrally positioned base.
- Arena 2: Single base in a corner, increasing spatial interference.
- Arena 3: Two bases at opposing corners, lowering local density.
Performance was quantified as the mean number of pucks retrieved per evaluation episode after a learning phase of 12 simulated hours.
Modular Representation vs. Full-State RL
The modular RL architecture was compared to:
- Full-State R-Learning and Q-Learning: Tabular methods using all binary sensor states (28 states for 8 sensors).
- Dynamic Window: A fixed, informed collision avoidance controller.
- Random: Baseline with actions sampled uniformly at random.
The results demonstrated that modular RL achieves competitive or superior foraging throughput compared to the stateful RL approaches, particularly excelling in memory efficiency (linear vs. exponential scaling in state representation).
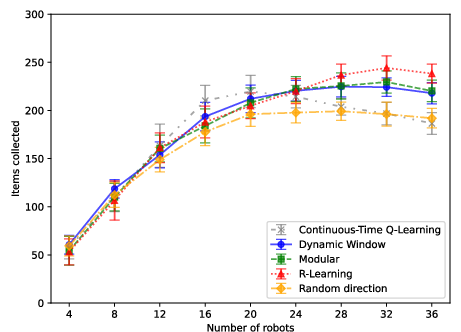
Figure 2: Modular RL and comparative algorithms in Arena 1 (central base): modular approach matches stateful RL with substantial state compression.
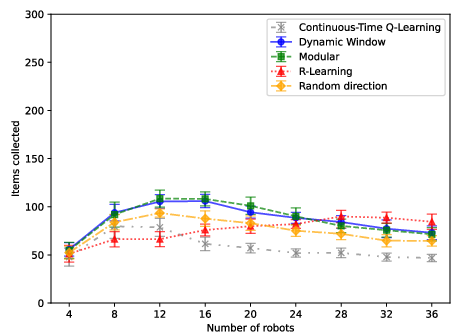
Figure 3: In Arena 2 (corner base), modular RL remains robust to dense collisions, outperforming baseline methods at lower memory budgets.
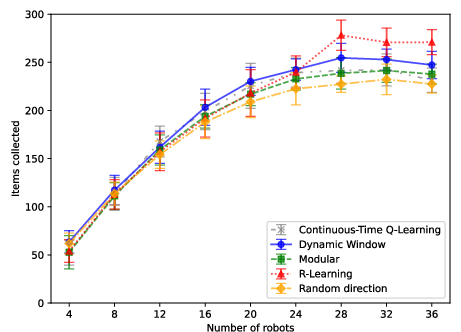
Figure 4: In Arena 3 (two bases), distributed modular RL exhibits consistency, though ambiguity due to multi-base structure leads to marginal loss relative to fixed strategies.
Robustness to Reward Function
The architecture’s robustness to reward variation was interrogated by replacing the difference reward (aligned with team objective) with a raw, self-interested reward. The modular representation exhibited remarkable invariance to this perturbation, unlike the dramatic performance degradation observed in stateful RL methods. This suggests a degree of inherent stability to mis-specified or noisy reward signals conferred by the independence and aggregation in the modular paradigm.
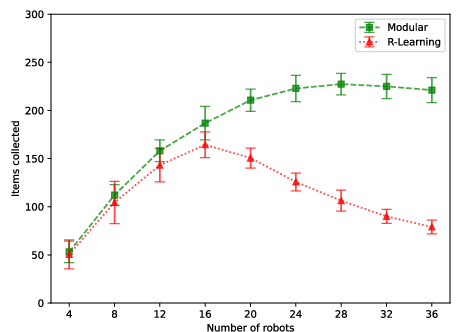
Figure 5: Modular and R-learning algorithms in Arena 1, comparing Δki(π) (difference reward) and self-interested reward: modular RL’s performance remains steady.
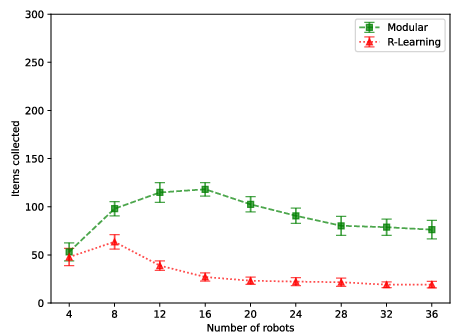
Figure 6: Modular and R-learning in Arena 2 under swapped rewards: modular RL outperforms stateful methods as rewards become misaligned.
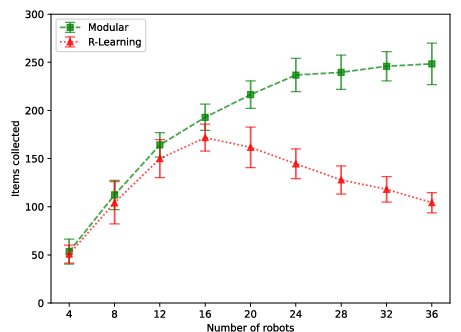
Figure 7: Arena 3 robustness comparison: only modular RL retains efficiency under reward noise.
Action Space Analysis
The necessity of vectorial action spaces was empirically validated by comparing the performance of R-learning with vectorial actions versus an action set composed of macro collision-avoidance algorithms. Vectorial actions afforded higher throughput and, crucially, enabled modular action arbitration, further justifying their use.
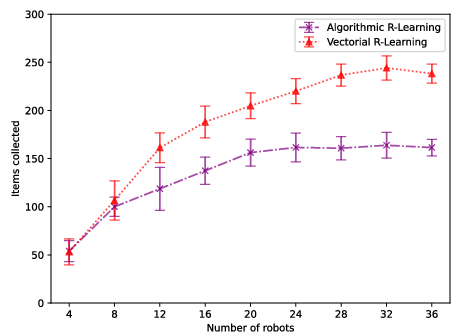
Figure 8: Arena 1 comparison: R-learning with vectorial action set surpasses algorithmic action set.
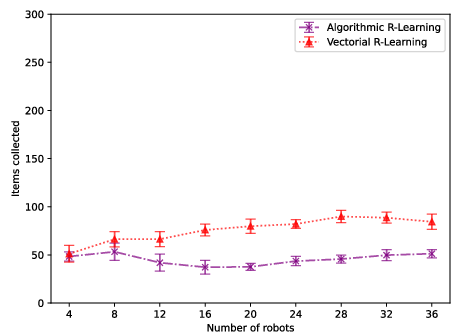
Figure 9: Arena 2 comparison confirms vectorial actions’ superiority in dense agent regimes.
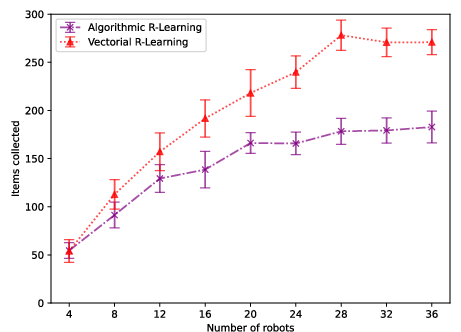
Figure 10: Arena 3: Vectorial actions again provide notable performance gains over algorithm-selection policies.
Theoretical and Practical Implications
The modular RL approach demonstrates that fully distributed swarms with extreme resource constraints can efficiently learn effective coordination strategies without incurring the computational or memory costs typical of tabular RL or deep RL architectures. The linear state representation enables deployment on microcontroller-based robots, facilitating scalable MARL in physical domains.
The robustness to reward model misspecification is particularly notable. Modular RL’s stability suggests that independent local policies, with appropriate fusion, can mitigate issues in reward design that often plague multi-agent RL—an avenue warranting further theoretical analysis.
From a theoretical perspective, by structurally aligning the per-feature local policies and using a composable action space, the framework bypasses the intractable combinatorics of conventional MARL while retaining policy quality in dense, decentralized interactions.
Future Directions
The results encourage extension in several directions:
- Generalization to other structured multi-agent tasks beyond foraging.
- Investigating alternate or adaptive aggregation (council) mechanisms beyond fixed Gaussian-weighted compositional fusion.
- Integration with partial communication or role specialization.
- Formal analysis of robustness properties under misspecified rewards or partial observability.
- Exploration of multi-modal sensors or higher-dimensional modular decompositions.
Conclusion
This work presents a modular approach to reinforcement learning for cooperative swarms, leveraging state decomposition and independent per-feature policies to address the memory and computation bottlenecks endemic to physical swarm robotics. The framework achieves memory-efficient, robust, and effective policy learning, validated across complex foraging environments with varying spatial coordination burdens. The modular RL representation offers a promising path toward scalable, decentralized MARL systems deployable on micro-robot hardware and warrants further investigation for theoretical properties and broader applicability.