- The paper proposes a precision-engineered LLM framework that uses vulnerability-aware prompts and AST-based context extraction to enhance detection accuracy.
- The framework employs a dataset of 31,165 annotated vulnerabilities from over 3,200 smart contracts, achieving average positive recall of 0.92 and negative recall of 0.85.
- The approach integrates chain-of-thought reasoning in prompt design, reducing false positives and improving the identification of diverse vulnerabilities across blockchain ecosystems.
Vulnerability-Specific LLM Analysis for Smart Contract Security
Motivation and Background
Smart contracts underpin decentralized systems by embedding logic directly onto blockchain platforms, introducing unique requirements for correctness and security. The immutable deployment and the absence of intermediaries amplify the risks associated with vulnerabilities—errors can be exploited irreversibly. Classical security analysis approaches, including formal verification, symbolic execution, and static/dynamic analysis, typically rely on expert-crafted rules and are frequently brittle when confronted with novel, cross-cutting vulnerability patterns. Recent research highlights that these approaches struggle with adaptability, coverage, and scalability for diverse, evolving smart contract ecosystems.
The emergence of LLMs, particularly models like GPT-4, has demonstrated an ability to reason over complex codebases and generalize across tasks through robust prompt engineering. However, prior attempts at leveraging LLMs for vulnerability detection suffer from poor negative recall, yielding high false positive rates that burden auditors and limit practical adoption. This paper addresses the gap by proposing a precision-engineered framework for LLM-based smart contract vulnerability detection, emphasizing context specificity, vulnerability-aware prompt design, and practical deployment considerations.
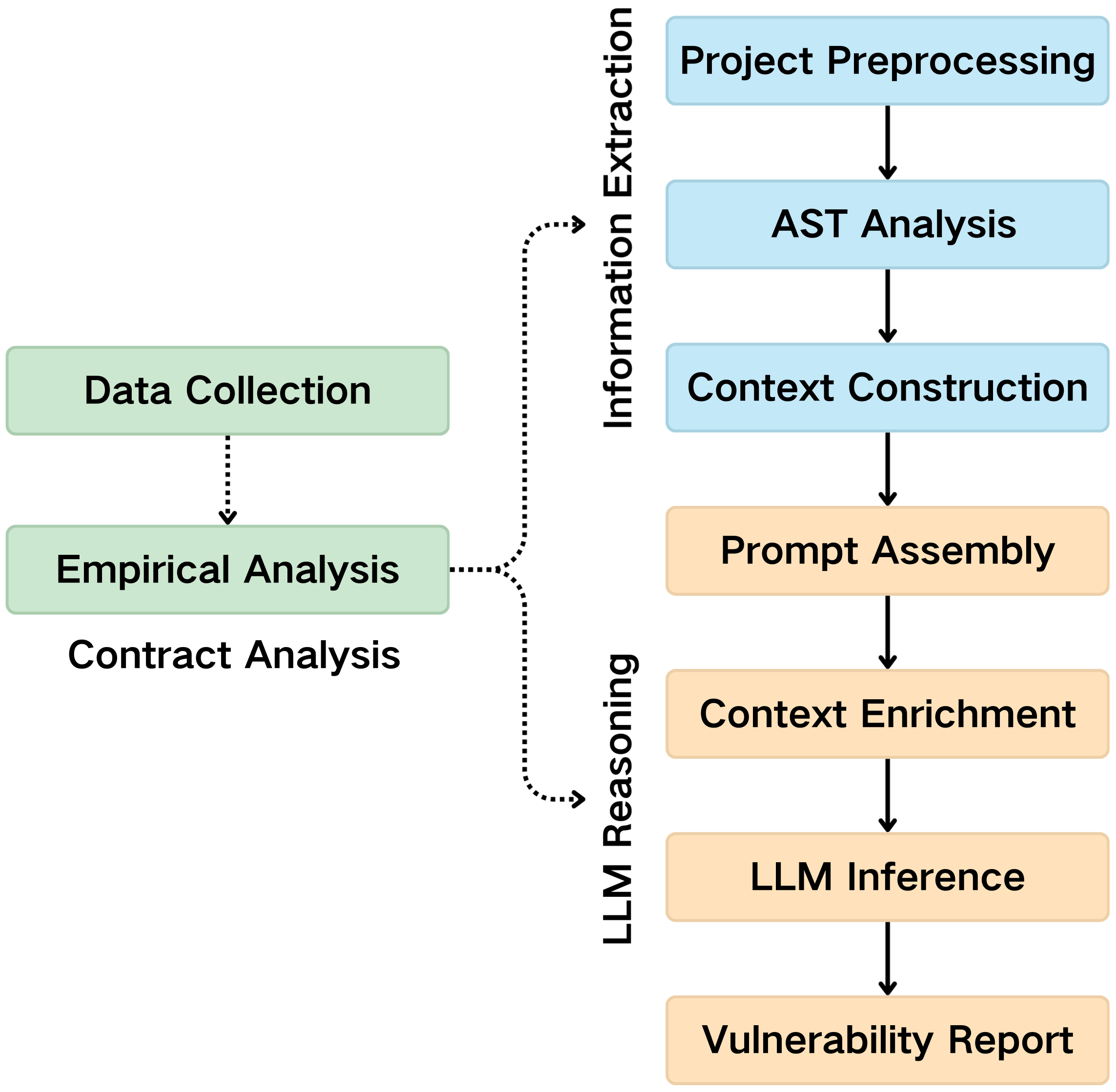
Figure 1: Overview of the proposed LLM-based smart contract vulnerability detection framework, illustrating data collection, precise context construction, and prompt-led LLM inference.
Dataset Construction and Empirical Foundation
A notable contribution is the release of a large-scale benchmark dataset comprising 31,165 professionally annotated vulnerability instances from over 3,200 real-world projects sourced across 15 blockchain ecosystems. The data pipeline involves systematic extraction of security audit reports, linking them to exact code commits and repositories, thereby ensuring high fidelity and reproducibility. The corpus encompasses a wide spectrum of vulnerability types (13 categories, including reentrancy, centralization, flashloan attack, event omission, and more), enabling robust empirical grounding for both model-training and evaluation.
The dataset’s breadth supports comprehensive statistical analysis of vulnerability distributions and characteristics, informing the subsequent model architecture and prompt engineering efforts. This approach minimizes sampling bias and maximizes coverage for practical auditing workflows, setting a rigorous baseline for LLM-based detection systems.
AST-Based Context Extraction and Modular Analysis
Direct code ingestion by LLMs often results in dilution of vulnerability signals due to noise and context overload. The framework introduces AST-based context filtering, substantially refining code representations. Contracts are parsed and reduced to symbolic structures, isolating components most relevant to specific vulnerability classes (e.g., internal states, call stacks, modifiers, event emissions). A two-tier pipeline first applies coarse filtering to retain only security-critical contracts, followed by fine-grained extraction of function-local interactions and related elements.
Notably, vulnerability localization is informed by dataset-driven heuristics—for example, reentrancy risks are typically concentrated in externally-callable functions, while input validation issues are associated with functions processing user inputs. The AST pipeline leverages a dedicated parser, such as python-solidity-parser, for fine-grained code structuring.
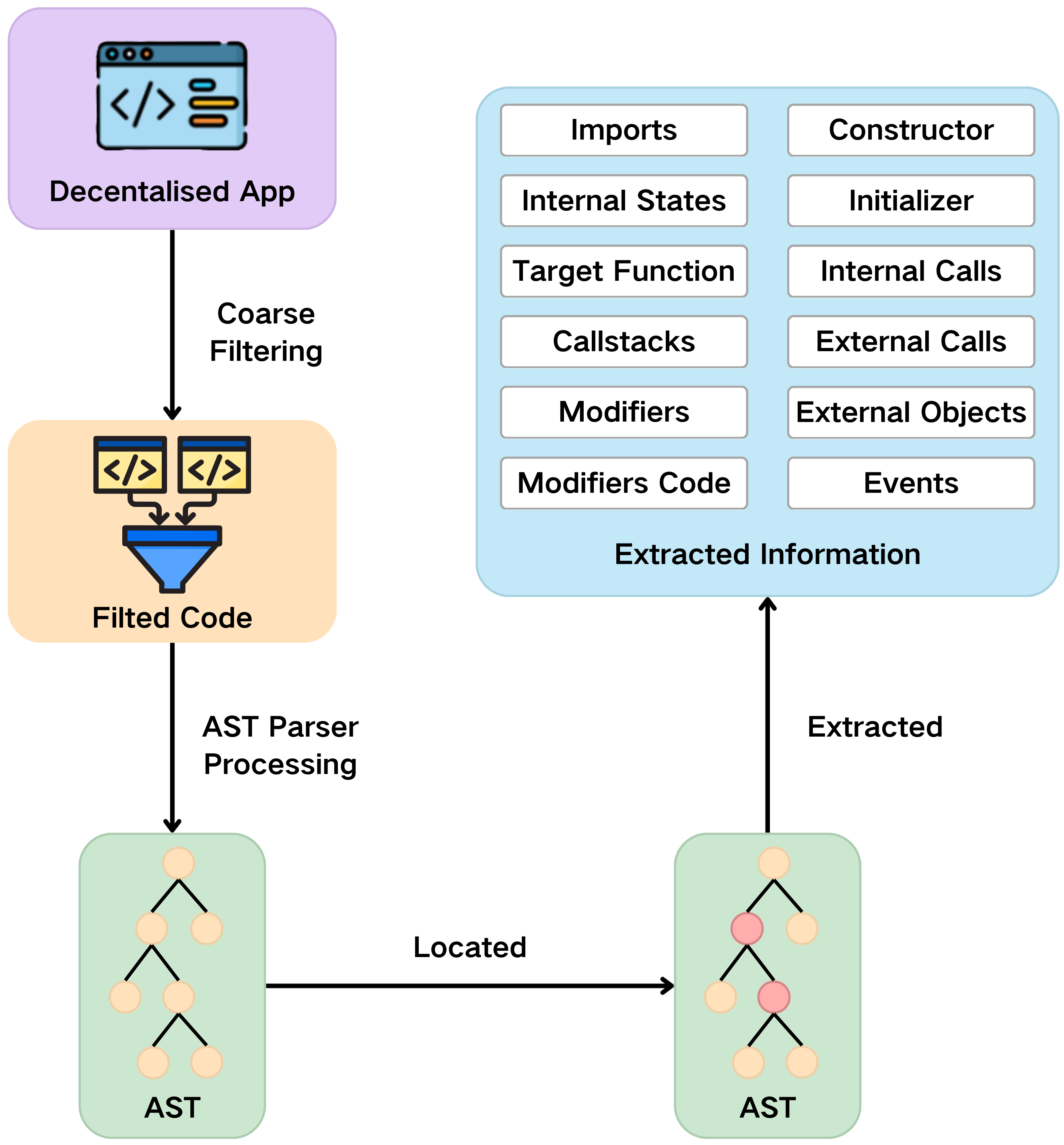
Figure 2: AST information extraction overview, depicting the staged filtering and context construction methodology.
This modular context extraction results in JSON-formatted, vulnerability-aware code fragments optimized for LLM consumption, substantially mitigating context overload and enhancing detection precision.
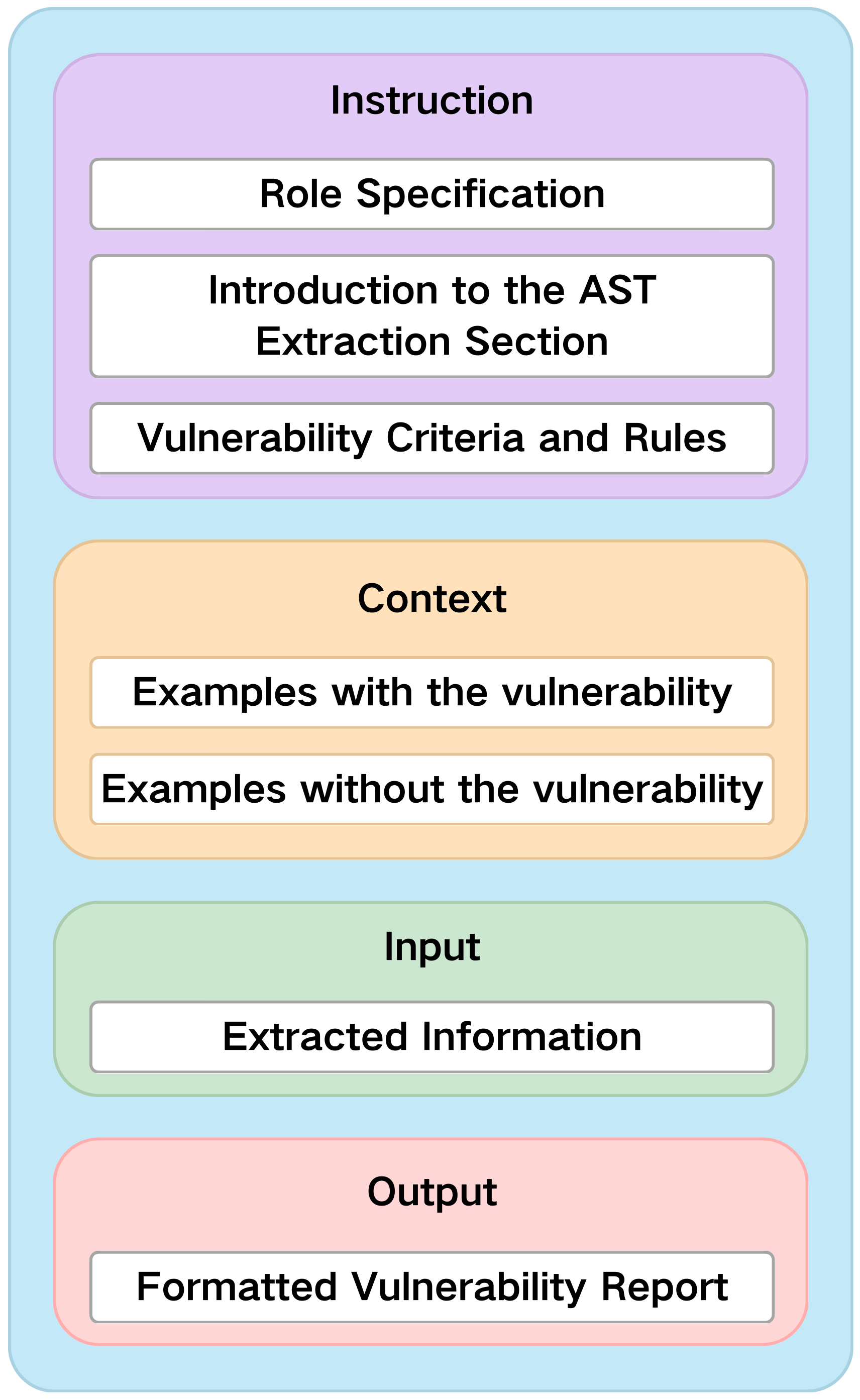
Prompt Template Design and Context-Enriched Few-Shot Learning
Detection effectiveness hinges on prompt engineering. The authors propose a unified prompt template dynamically instantiated for each vulnerability class, consisting of:
Empirical analysis demonstrates that integrating CoT reasoning into prompt construction yields measurable improvements in accuracy, especially in reducing false positives (negative recall). Model inference is performed using GPT-4, with careful token budgeting to comply with API restrictions.
Experimental Results and Comparative Evaluation
Detection performance is evaluated across the 13 vulnerability categories, using stratified sampling to construct balanced evaluation sets for positive and negative instances. The average positive recall is 0.92, and the average negative recall is 0.85, with precision and accuracy also consistently high (average accuracy of 0.91). Some categories, like "Return Value Check" and "Error Message," approach near-perfect recall and precision metrics (positive recall > 0.98), while others, notably "Missing Event," exhibit a tradeoff between high positive recall (0.98) and moderate negative recall (0.60).
These metrics establish the framework’s superiority over prior prompt-only LLM approaches, resolving critical issues in practical deployment by reducing auditor workload and minimizing misclassification costs. The methodology’s modularity allows prompt template and example refinement for future vulnerability patterns, although fully automated adaptability remains an open problem.
Practical and Theoretical Implications
The integration of AST-based context construction and CoT-enriched prompting establishes a scalable paradigm for leveraging general-purpose LLMs in security-critical tasks without requiring domain-specific model fine-tuning. This approach bridges formal program analysis with flexible neural inference mechanisms, enabling detection systems to address complex, multi-contract, and dynamically evolving vulnerabilities.
Practically, the framework equips auditors and developers with a high-precision tool compatible with mainstream blockchain ecosystems (EVM-compatible), facilitating secure development and real-time vulnerability assessment. The released dataset catalyzes reproducibility and further research. Theoretically, the system’s performance highlights the importance of context specification and boundary-case reasoning for task generalization, inviting exploration of automated prompt optimization, adaptive context extraction, and integration with static analysis claims.
Future Directions
The paper identifies limitations in manual prompt refinement and suggests future work in automated, adaptive prompt generation to address unseen vulnerability classes. Additionally, the possibility of integrating cross-contract analysis, hybrid reasoning frameworks combining symbolic and neural methods, and direct fine-tuning on evolving vulnerability datasets represent promising pathways for advancing LLM-based smart contract security.
Conclusion
This work presents a comprehensive, empirically validated LLM framework for tailored, vulnerability-specific smart contract security analysis, combining large-scale real-world datasets, AST-informed context extraction, and modular prompt design with chain-of-thought reasoning. The reported detection rates substantiate the practical viability of the approach, supporting scalable, high-fidelity vulnerability screening across decentralized application ecosystems. The architecture offers a template for future developments in adaptive security analysis and formal-neural hybrid systems for blockchain infrastructure.