- The paper introduces a revised RL agent that restructures the action space by generalizing qubit routing operations along precomputed paths using Dijkstra's algorithm.
- It demonstrates a significant reduction in circuit execution time—up to 38%—and improved scalability across varying circuit depths on distributed quantum architectures.
- The agent achieves computational efficiency gains by reducing wall-clock training time by 64% through structured Q-value approximation and enhanced action masking.
Action-Space Engineering for RL-Based Circuit Routing in Distributed Quantum Systems
Introduction and Motivation
The scalability challenges of monolithic quantum architectures have led the community to modular and distributed quantum computing (DQC), where multiple smaller quantum processor modules are interconnected via quantum channels. One core problem in this landscape is quantum circuit compilation: mapping and routing quantum circuits across these modules efficiently, minimizing execution time given local and non-local connectivity constraints, and the stochastic, resource-intensive nature of remote entanglement (Figure 1).
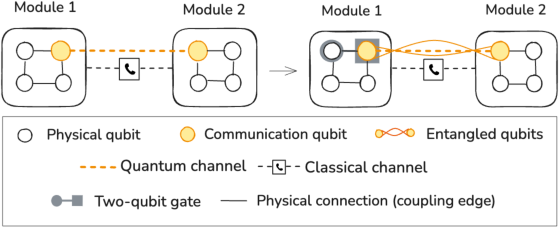
Figure 1: An entangled state is generated between two remote qubits used as communication qubits connected via a quantum channel and heralded by a classical message sent over a classical channel. Within each module, local two-qubit gates can be applied between all qubits according to the available connectivity (physical coupling edges).
Standard approaches for distributed circuit compilation rely primarily on static partitioning, graph partitioning heuristics, or network-aware flow and scheduling methods largely abstracting away underlying network and resource dynamics. Recent advances incorporate explicit modeling of entanglement generation and decoherence [main_distributed_2025], but retain circuit-by-circuit optimization costs and rely on heuristics.
Reinforcement learning (RL) framed in the Markov decision process (MDP) paradigm can amortize experience across circuits and, with sufficient generalization, offer fast inference for new circuits after a potentially expensive training phase. Early RL approaches for DQC leverage large groundstate action spaces and limited action masking, resulting in suboptimal training and inference efficiency [promponas_compiler_2024].
Novel Contributions and Methodology
This paper introduces a revised RL agent for circuit compilation in DQC featuring:
- Action-space restructuring: Instead of associating actions solely to physical operations (SWAP, tele-qubit, generation) at specific edges, actions are generalized to pairwise qubit routing operations, allowing an RL action to specify a chain of swaps or teleportations along a precomputed path between any qubit pair. This method leverages the underlying hardware coupling graph and uses Dijkstra's algorithm for shortest path computation.
- Enhanced action masking: The admissible action set at each timestep is restricted to only those actions that are immediately relevant for progress with respect to the current "frontier" layer of the circuit DAG or those that prepare for future remote interactions. Actions are masked unless they (1) decrease the spatial separation between qubits required for imminent two-qubit gates, (2) move unassigned qubits towards a channel endpoint to prepare resource states, or (3) synchronize EPR qubits with required frontier operations.
- Efficient Q-value representation: To mitigate the quadratic growth in Q-function outputs (for all qubit pairs), a structured Q-value approximation is used. Each action Q-value is parameterized in terms of source and target qubits' Q-values with a directionality-preserving convex combination. The Q-network thus scales linearly rather than quadratically with the number of physical qubits, yielding significant computational gains in large systems.
- Modified reward structure: Additional rewards penalize unnecessary system idling, and the reward for routing actions is zero unless they actually reduce the total frontier qubit distance in the hardware graph. This focuses credit assignment strictly on progress-relevant decisions.
Numerical Evaluation and Key Results
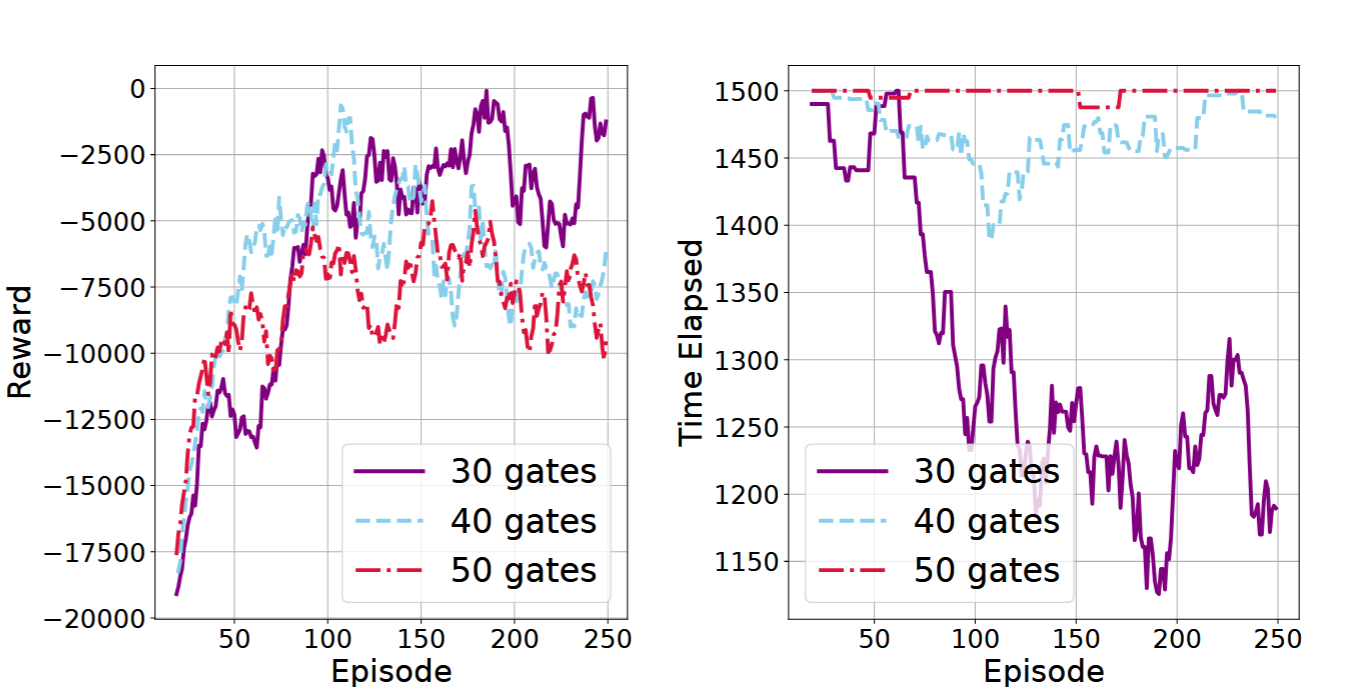
The introduced RL agent is evaluated against the baseline DDQN agent of [promponas_compiler_2024] on two architectural testbeds: a low-connectivity two-module IBM Guadalupe layout, and a high-connectivity pair of 4×4 grid QPUs. Circuits with varying numbers of CNOT gates (30–50) and 18 qubits are randomly generated for both training and test sets. The primary metric is modeled circuit execution time (in architecture-specific timesteps), together with wall-clock training time.
Strong numerical findings and claims include:
Implications and Future Directions
Practical Significance
These results show that RL agents with engineered action spaces and aggressive masking can realize substantial practical benefits in the context of DQC compilation. Faster inference after training amortizes computational costs across workloads and makes RL-based compilation competitive for batch and streaming quantum computing scenarios. Further, the techniques for dimensionality reduction in RL—structuring the Q-function and leveraging architectural regularities—are widely transferable to other large-action-space RL scheduling and resource allocation problems.
Theoretical Impact
The work highlights the criticality of action-space design and Q-value parameterization in RL for combinatorial scheduling over networked quantum devices. By directly coupling the action structure to physical system topology and the circuit computation graph, the agent is better aligned with the underlying hardware constraints and resource bottlenecks. The methodology suggests directions for theory: analyzing the expressivity–efficiency trade-off of structured parametric value functions and the convergence implications of heavy masking, especially regarding policy optimality when the admissible set is highly filtered.
Broader AI and Quantum Computing Outlook
From the broader AI perspective, this research exemplifies the maturation of RL for hybrid quantum-classical optimization domains—where both the state and action spaces are governed by physical constraints, and simulation costs are substantial. The approach is thus relevant to other emerging applications in quantum network scheduling, memory management, and error correction, especially as scalable quantum architectures move beyond experimental regimes.
For distributed quantum computing, scalable and efficient circuit compilation is a key bottleneck for practical, large-scale platforms. As fault-tolerance technologies mature and DQC architectures proliferate, the need for compiler approaches that sustain high throughput and minimal overhead, and adapt rapidly to hardware changes or workload shifts, will remain paramount.
Limitations and Open Challenges
Despite strong performance improvements, the fundamental scalability of the RL approach is still bound by the growth of the system state space with circuit size and qubit count. The current approach does not abstract away all combinatorial complexity. Furthermore, strict masking strategies—while beneficial for credit assignment and training—may impede discovery of globally optimal, non-myopic routes, particularly if circuit scheduling subtleties require temporary regressions for long-term gains.
Future work must address:
- Learning compact, transferable representations of quantum circuit state that support zero-shot or few-shot generalization across diverse workloads and hardware topologies.
- Balancing exploration and exploitation in heavily masked action sets; possibly leveraging policy distillation or offline RL to recover global optimality.
- Incorporating physical noise models, decoherence, and stochastic entanglement generation more faithfully to bridge the gap between simulated environments and actual hardware.
- Extending the approach to integrate compiling for quantum error correction and multi-level logical-physical mapping.
Conclusion
This work demonstrates that RL agents, when rigorously engineered with problem-specific action spaces, masking, and Q-function parametrizations, can dramatically improve both execution time and computational efficiency for circuit routing in distributed quantum systems. These advances support the future deployment of scalable, low-latency DQC platforms and establish critical design principles for RL in quantum resource management tasks.