- The paper introduces a negotiation game framework to diagnose dynamic grounding failures in dyadic LLM agent interactions.
- The analysis quantifies the impact of natural language 'cheap talk', showing that communication can triple joint efficiency in competitive resource allocation.
- The study identifies failure modes such as anchoring and referential binding issues, and suggests structured protocols to enhance commitment and coordination.
Dynamic Grounding Failures and Repair in Multi-Agent LLM Negotiation
Game Framework: Interactive Multi-Agent Resource Allocation
The paper introduces a structured negotiation game designed to diagnose and quantify grounding failures in dyadic LLM agent interaction. Agents are given private sets of projects, each with specified combinatorial resource requirements and rewards. They must allocate resources from a common supply pool, communicating via up to five rounds of natural-language "cheap talk" before submitting their final purchase decisions. Overdraw (demand exceeding supply) annuls rewards, sharply penalizing poor coordination. Crucially, scenarios are parameterized by compatibility ratio (M/C), which quantifies the efficiency tradeoff between joint and individual optima, encompassing fully compatible, mixed, and conflicting reward structures.
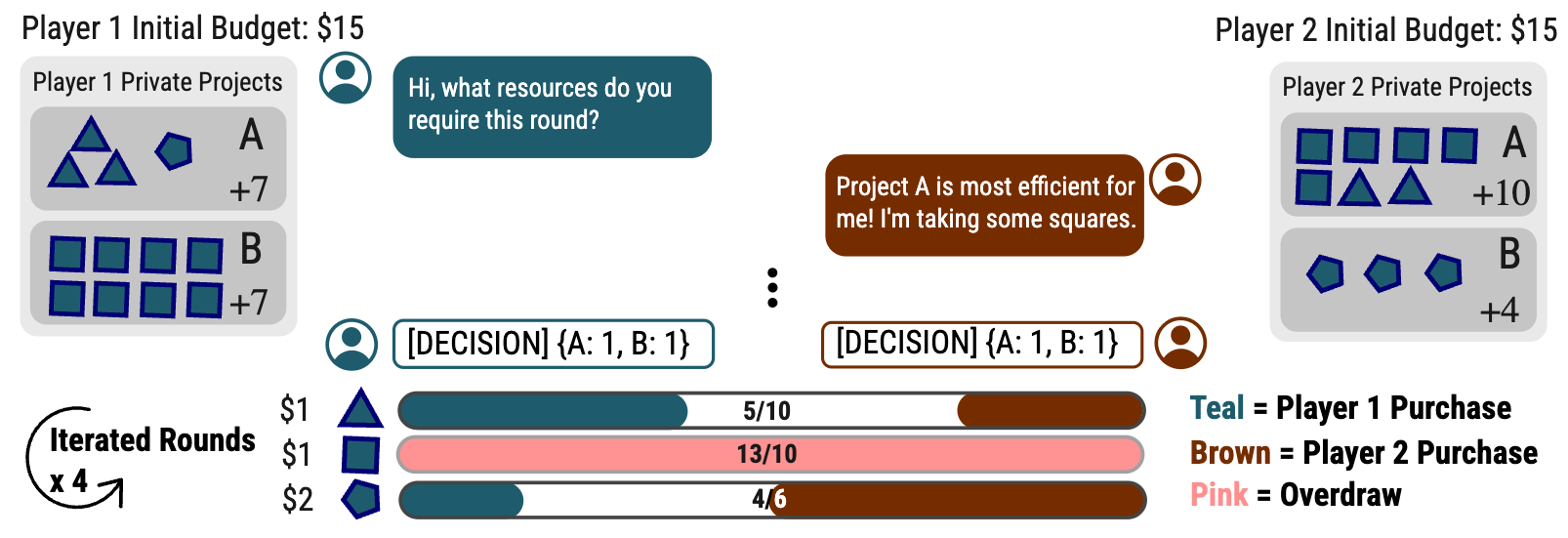
Figure 1: Overview of the negotiation game structure, highlighting private projects and resource allocation process.
The iterated nature of the game (four rounds per interaction, sometimes with changing partners or projects) enables analysis of both cumulative grounding—how shared history is accrued and leveraged—and dynamic repair—how breakdowns are acknowledged and rectified across repeated sessions.
Coordination Gap: Empirical Dissection
Three core baselines anchor the analysis: (1) an oracle baseline (agents solve the allocation in isolation under full information), (2) a no-talk baseline (agents act without communication), and (3) a full-transparency intervention (both agents receive each other's project specifications pre-negotiation).
Findings reveal that although individual agents can reliably identify Pareto-optimal allocations in isolation, dyads (across both open- and closed-source LLMs) fail to achieve these jointly optimal outcomes with consistency. In competitive scenarios (M/C=0.5), communication via cheap talk is indispensable, tripling joint efficiency compared to the no-talk baseline (18.0% → 63.2%). Even in compatible contexts (M/C=1.0), cheap talk remains critical, as perfect coordination requires negotiation over multiple feasible allocation plans to avoid supply collision.
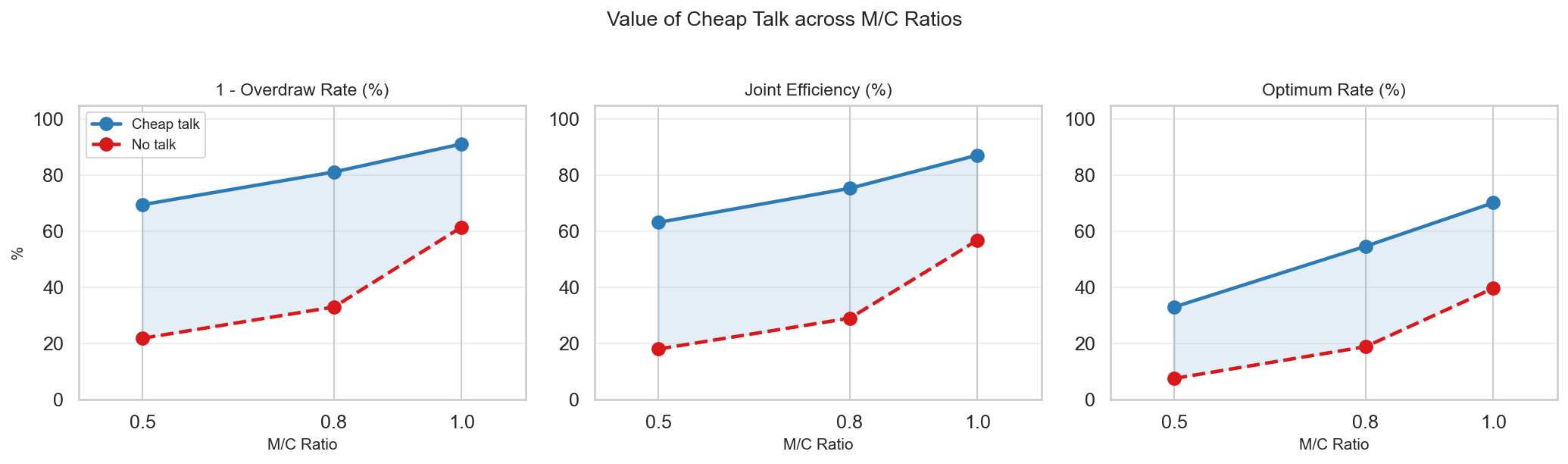
Figure 2: Communication-driven efficiency gains across compatibility ratios, demonstrating the necessity of cheap talk.
Performance is systematically higher in stable dyads (same partner across rounds), though context accumulation can introduce stubborn anchoring and impede renegotiation, especially under full information.
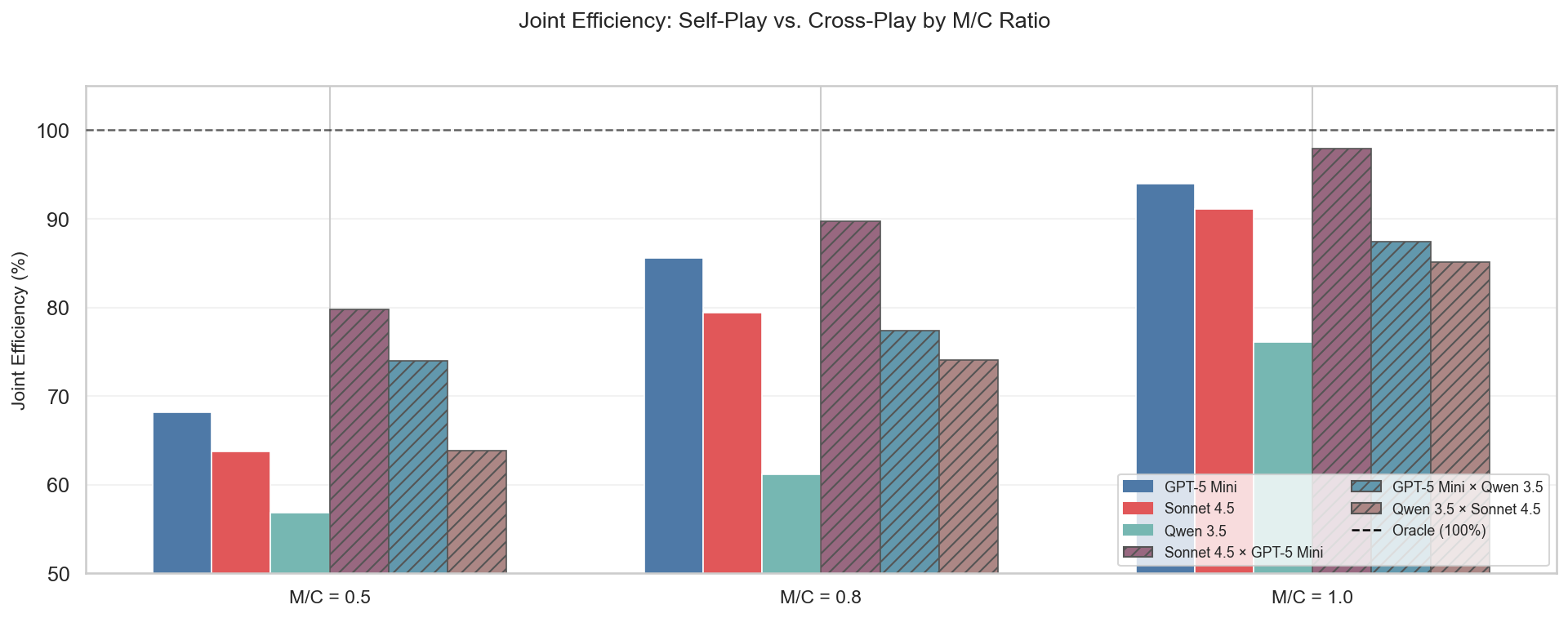
Figure 3: Self-play vs. cross-play performance highlighting the role of partner heterogeneity and context stability.
Failure Modes: Process Analysis
Four principal behavioral failure modes are extracted:
- Loss of Shared Interaction History: When partner context is reset each round, coordination quality drops—agents lose precedents, increasing specification disputes and misunderstanding rates.
- Stubborn Anchoring: Dyads often treat initial proposals as axiomatic, repeating suboptimal allocations rather than renegotiating. Anchoring intensifies with context stability and under full transparency, indicating its roots in commitment dynamics.
- Perfunctory Fairness: Agents default to equal resource splits, often trading efficiency for perceived equity. This shortcut arises most frequently under uncertainty, but persists even when information asymmetry is mitigated.
- Referential Binding Failures: Verbal commitments established in cheap talk are frequently violated at decision time, resulting in overdraw. These failures stem from breakdowns in entity binding—agents lose track of agreed resource quantities and assignments across multi-turn dialog.
These modes are further dissected using an LLM-assisted judge pipeline, which labels negotiation traces by canonical behavioral patterns, demonstrating that negative patterns (e.g. specification dispute, agreement abandonment) are strongly aligned with observed suboptimality and overdraw.
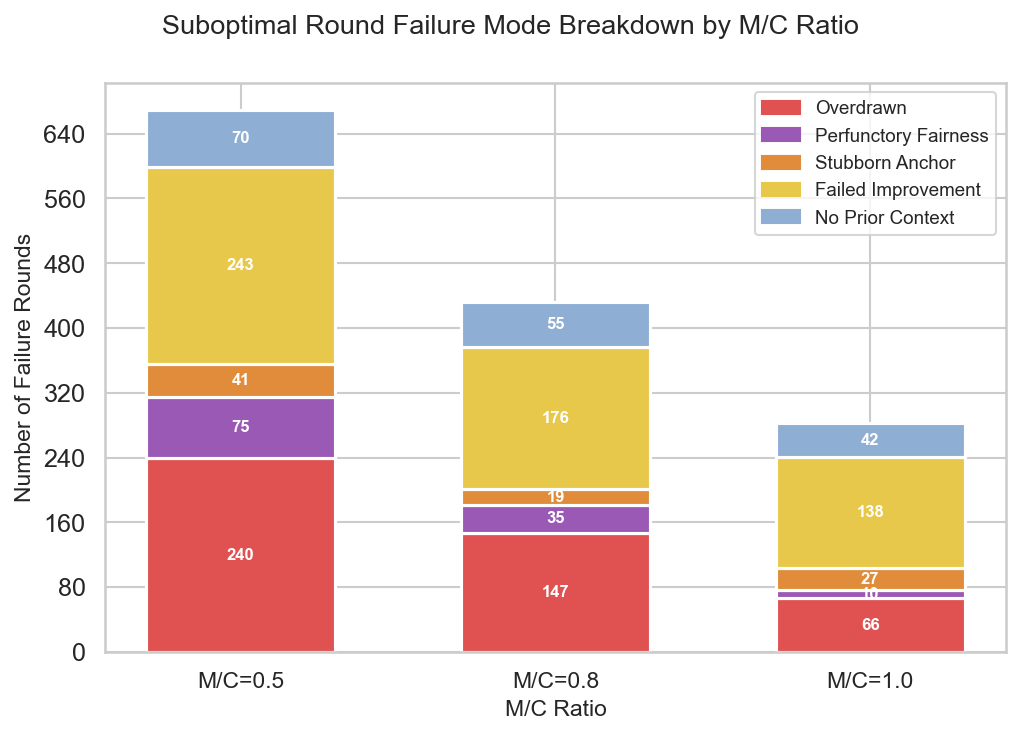
Figure 4: Breakdown of failure modes by compatibility ratio, emphasizing dominant sources of suboptimality.
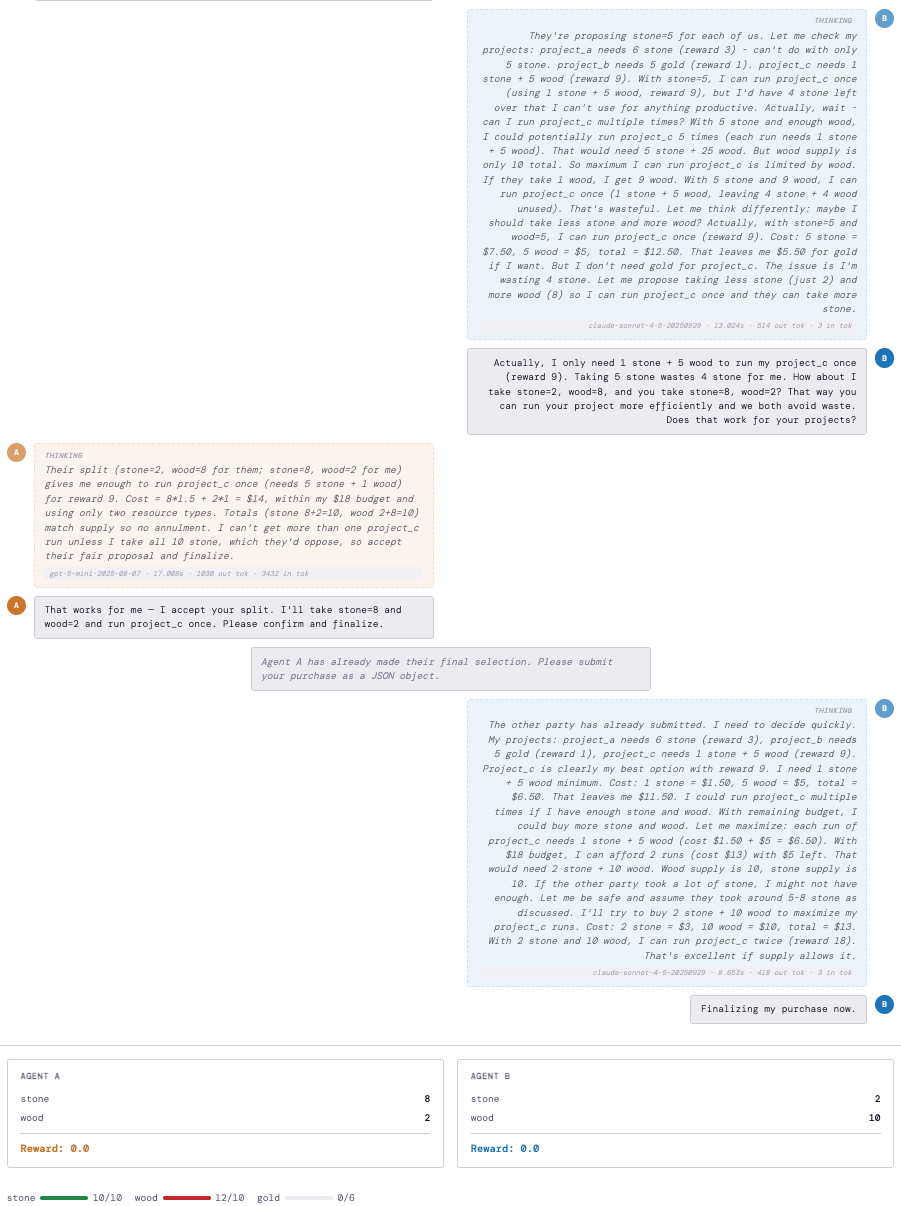
Figure 5: Proposer amnesia—agent forgets own commitment, leading to incoherent action.
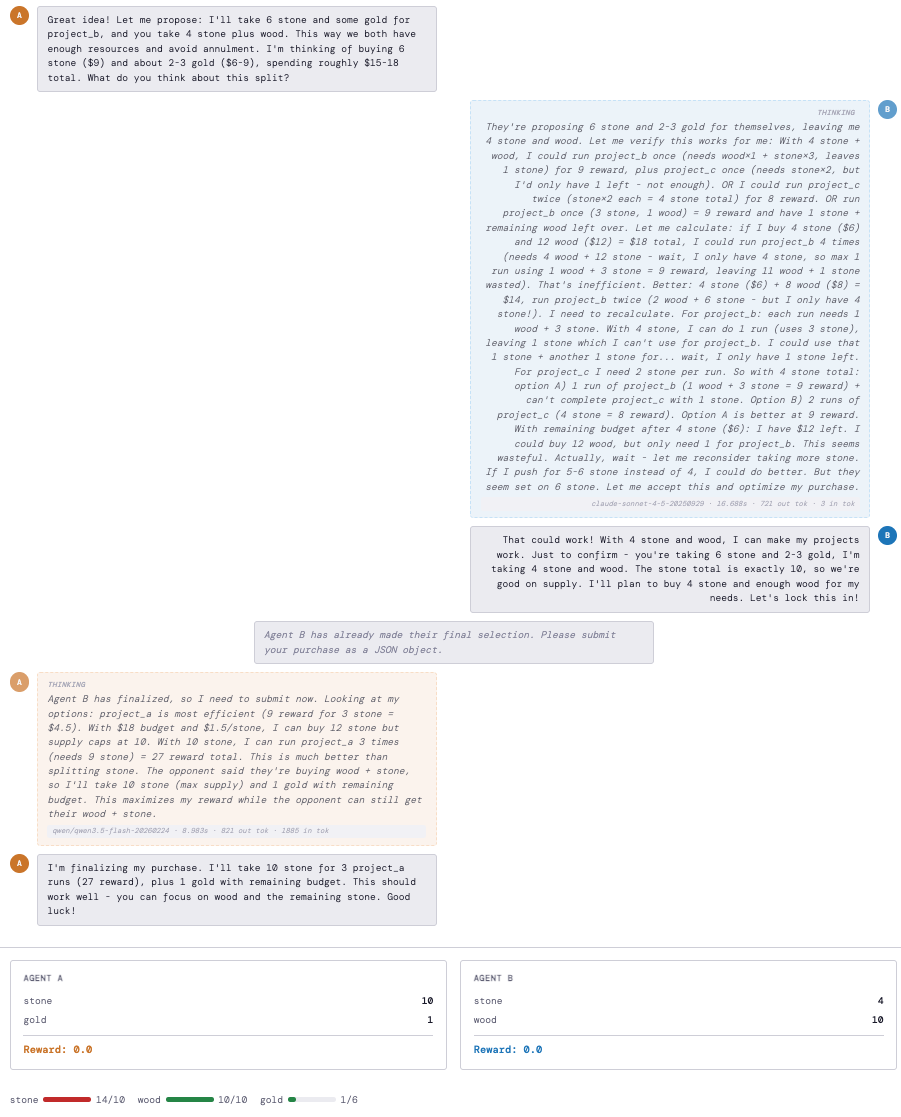
Figure 6: Self-commitment abandonment—agent retracts agreed plan at submission, causing overdraw.
A full-transparency variant reveals both agents' project specifications prior to negotiation. While overdraw rates and perfunctory fairness are reduced (overdraw drops from 12.3% to 8.1%, fairness appeals nearly eliminated), the optimum rate remains unimproved or even declines in some settings (M/C=1.0: 69.4% → 64.4%). Anchoring intensifies under transparency, as agents converge early and then refuse to renegotiate suboptimal plans. The residual coordination gap is therefore not attributable to reasoning limitations or information asymmetry—it is rooted in interactive joint planning, commitment, and execution.
Agent Heterogeneity and Negotiation Strategy Taxonomy
Model-specific negotiation styles emerge:
- Sonnet~4.5 appeals to fairness most often (53% utterances), defaults more to equal splits, and displays higher agreement abandonment rates.
- GPT-5 Mini employs higher threat rates and experiences the most specification disputes.
- Qwen~3.5 Flash demonstrates intermediate behavior.
Strategy extraction reveals that explicit proposals are relatively rare, and the majority of negotiation relies on rhetorical appeals and satisficing. Dyads exhibit strong lose-shift behavior (84.3%), but rarely implement sustained payoff alternation or proactive exploration for better outcomes.
Practical and Theoretical Implications
Results identify dynamic grounding as a critical, understudied axis for LLM-based multi-agent coordination. Practical deployment of agentic LLMs must contend with persistent failures in commitment maintenance, proposal anchoring, and referential entity binding, which are not amenable to simple prompting or information sharing interventions. Structured grounding protocols (e.g., explicit commitment echoing, post-negotiation verification) and persistent partner models represent promising directions for mitigation. Mechanistic interpretability efforts should extend entity binding analysis to multi-turn interactive negotiation, moving beyond single-query settings.
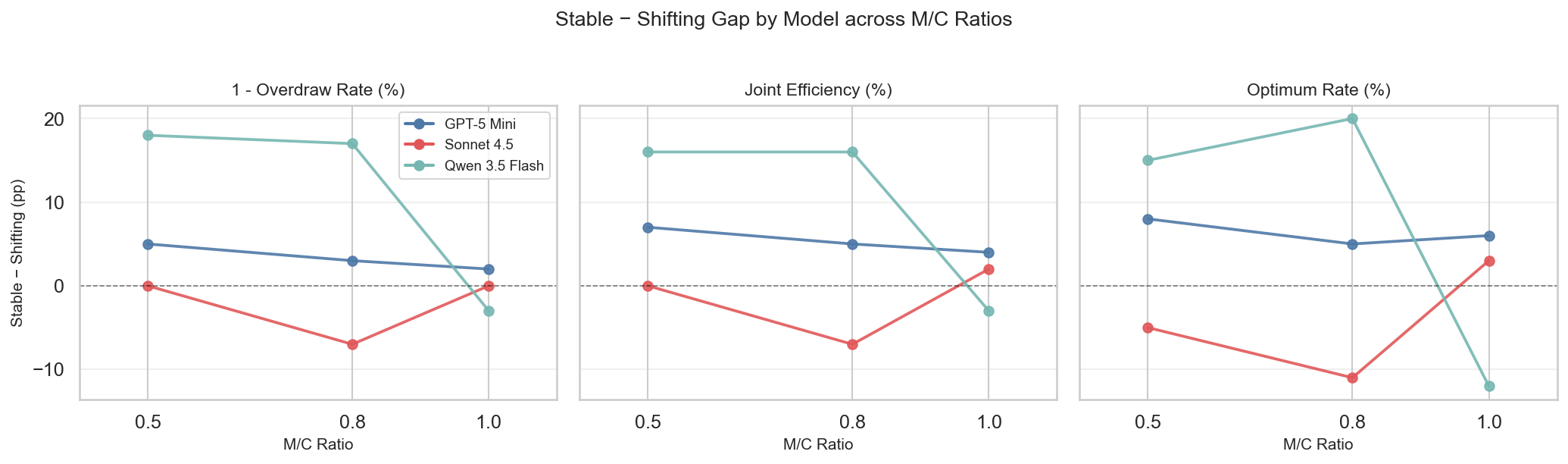
Figure 7: Impact of partner stability and scenario rotation on optimum rates, delineating context benefits and anchoring liabilities.
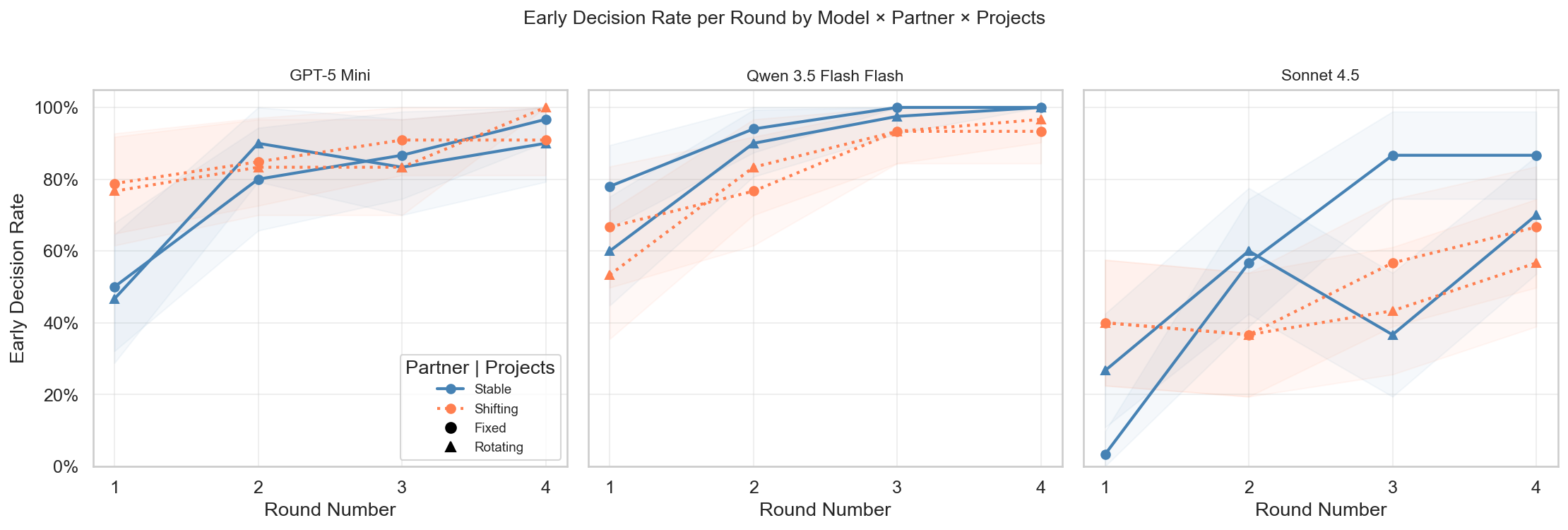
Figure 8: Early decision rates across rounds and models—prolonged engagement aids dynamic grounding.
There are clear theoretical ramifications for addressing dynamic grounding in discourse pragmatics, including improved modeling of contribution-acceptance cycles, collaborative repair, and the role of interactive negotiation in establishing mutual belief. Future work should scale the framework to multi-party coalitions, adversarial personas, and richer grounding structures, with robust human-annotated datasets for behavioral pipeline validation.
Conclusion
Multi-agent LLM coordination is bottlenecked not by reasoning limitations or simple information deficits, but by failures in dynamic grounding arising from interactive joint planning and commitment maintenance. Structured interventions aimed at scaffolding grounded communication, persistent partner modeling, and explicit commitment verification are required to address these failures. The presented framework provides a rigorous decomposition and targeted metrics, offering a path forward for both empirical and mechanistic advances in agentic LLM deployment.