- The paper demonstrates that decoupling slow CoM planning from fast thrust control through a bi-level RL approach significantly enhances tracking accuracy.
- It employs Soft Policy Gradient for CoM planning and Soft Actor-Critic for real-time thrust control, achieving up to 54% RMSE reduction compared to fixed baselines.
- Empirical and simulation results validate robust, energy-efficient navigation with reliable sim-to-real transfer across diverse target scenarios.
Bi-Level Reinforcement Learning Control for Underactuated Blimps via Center-of-Mass Reconfiguration
Introduction and Motivation
Traditional blimp designs employ multi-actuator architectures to achieve controllability and maneuverability, incurring significant penalties in mass, mechanical complexity, and power consumption, particularly restrictive for lighter-than-air (LTA) platforms. The paper addresses the underactuated blimp scenario, specifically using the RGBlimp prototype, which leverages two thrusters and an internal mobile mass (slider) for center-of-mass (CoM) reconfiguration (Figure 1). This compact hardware configuration enhances energy efficiency and payload capacity but also induces strong nonlinear coupling and underactuation, making conventional PID and feedback-linearization controllers suboptimal.

Figure 1: The RGBlimp prototype features a movable gondola for CoM reconfiguration, main wings, tail fin, and tailplanes, enabling minimal actuation but introducing complex internal dynamics.
The central insight is the temporal and functional decoupling between CoM configuration (slow, task-level) and thrust-based trajectory control (fast, continuous), which is exploited via a bi-level reinforcement learning (RL) framework. The proposed approach defines the outer loop for goal-conditioned CoM planning and the inner loop for real-time thrust control, enabling precise, robust path tracking across diverse target goals (Figure 2).
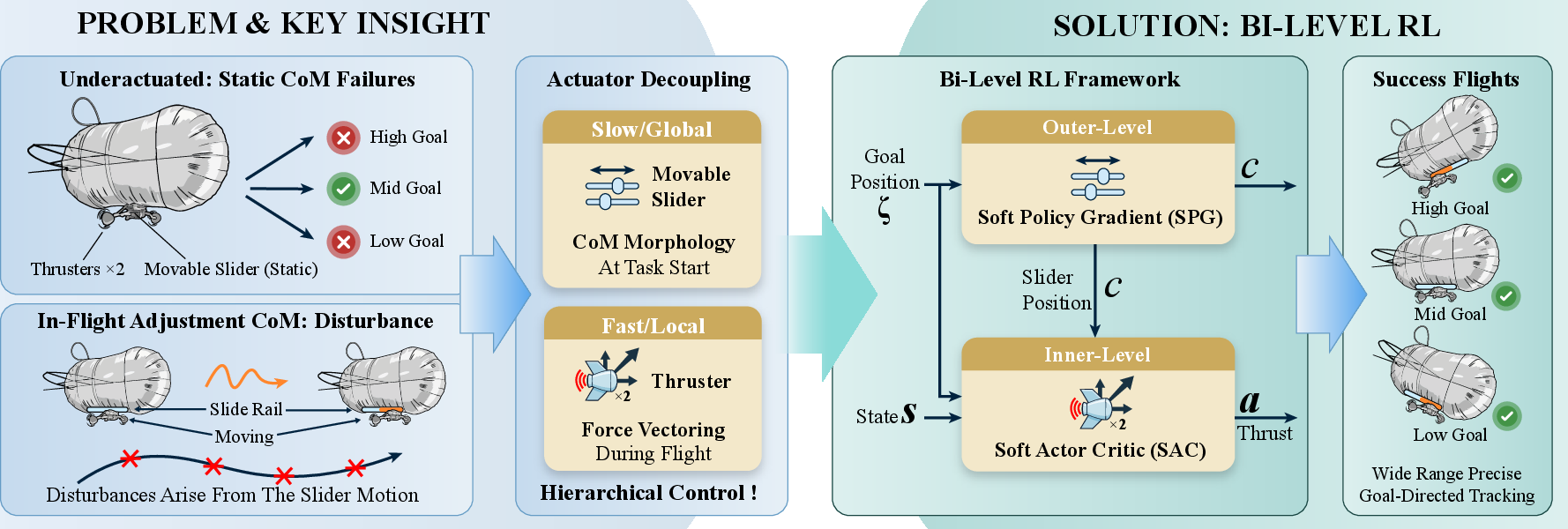
Figure 2: Key insight—decouple task-level CoM adjustment via a slider from fast thrust control, enabling bi-level RL with Soft Policy Gradient for the outer loop and Soft Actor-Critic for the inner loop.
The RGBlimp vehicle is modeled as a 6-DoF system with state vector comprising position, attitude, velocities, target goal, and slider position. The system dynamics explicitly account for the effect of the slider position c on inertial, Coriolis, gravity-buoyancy, aerodynamic, and control allocation matrices, based on parameter identification from empirical flight data. The control task is formulated as goal-directed tracking from a fixed origin to a target ζ, minimizing deviation from a straight-line reference trajectory.
The bi-level control architecture is formalized in terms of two parameterized policies:
- Outer policy (πϕc): Samples slider configuration c conditioned on target ζ (prior to flight).
- Inner policy (πϕa): Generates real-time thrust commands based on the full system state during flight.
Hierarchical RL decomposes this joint optimization problem, optimizing the episode-wise outer policy with Soft Policy Gradient (SPG) and the step-wise inner policy with Soft Actor-Critic (SAC). The reward function penalizes cross-track error, heading misalignment, and rewards goal achievement and forward progress.
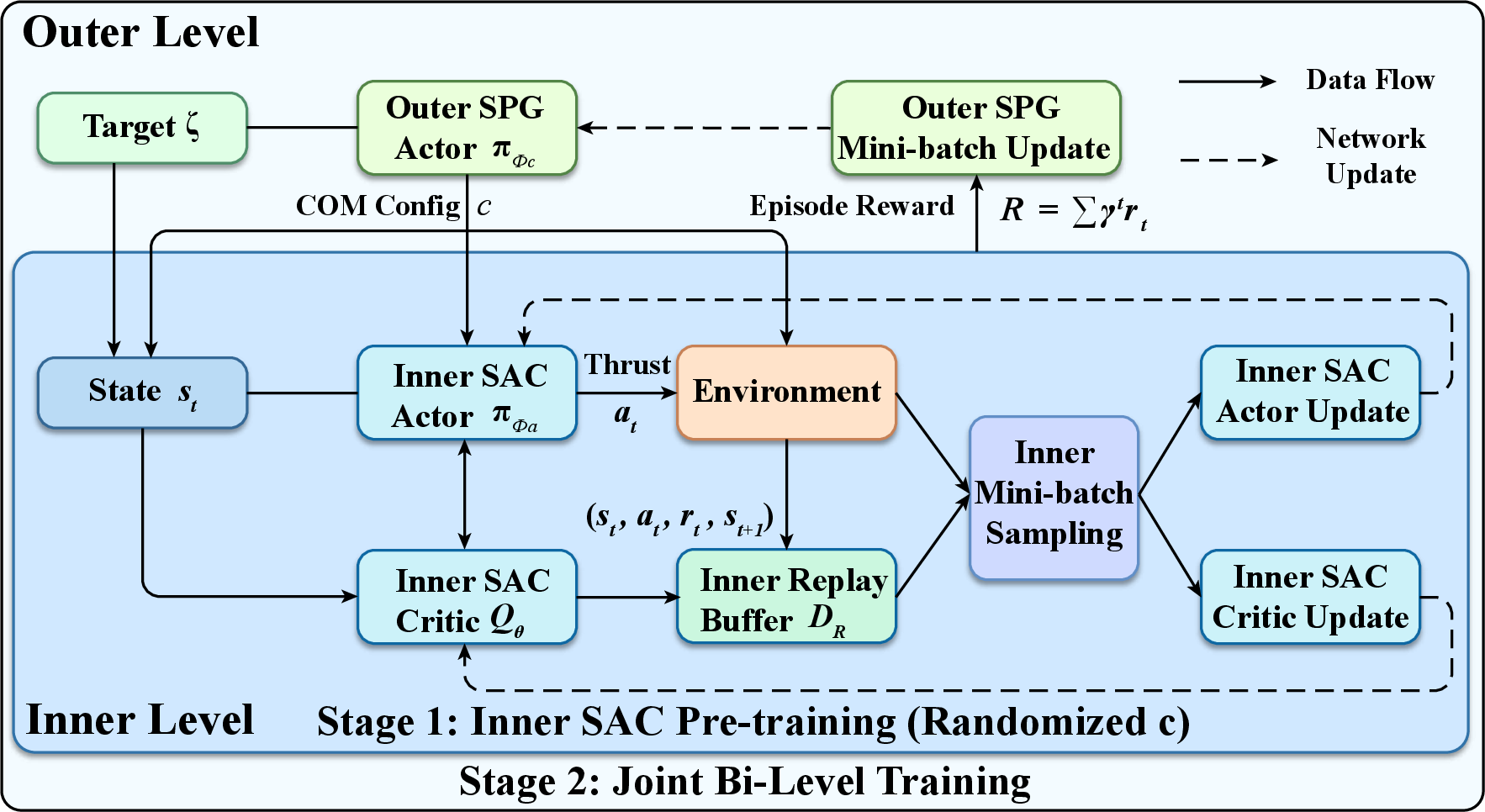
Figure 3: Bi-Level RL framework overview: outer loop for episode-wise slider position selection (SPG), inner loop for thrust command generation (SAC), trained in two sequential stages.
Training Methodology and Convergence Properties
The paper introduces a two-stage training protocol to stabilize bi-level optimization:
- Stage 1 – Inner Loop Pretraining: Slider positions randomized per episode; only SAC inner controller trained to ensure robust thrust control across the full range of configurations.
- Stage 2 – Joint Training: Outer policy adapts slider based on goal, while inner policy continues online updates; bi-level optimization coordinates CoM adaptation with trajectory control.
A theoretical convergence analysis is provided: convergence of the outer loop (SPG) is shown to be robust to errors in the inner critic, as long as those errors decay sublinearly and the Robbins-Monro conditions on step-size are satisfied. Empirical domain randomization (state, aerodynamic, and inertia perturbations) ensures robust sim-to-real transfer.
Numerical Results: Simulation and Real Flight Evaluation
The bi-level RL agent is evaluated across a grid of 27 targets, with cross-track RMSE as the primary metric. Comparison is made against three fixed-slider baselines using the same SAC inner controller and a conventional PID controller with learned slider policy (PID-SPG).
Summary of results:
- Task-dependent slider adaptation: The learned outer policy aligns with physical intuition, shifting the slider backward for climbing targets (nose-up pitch) and forward for descending targets (nose-down pitch), as visualized in the learned slider map.
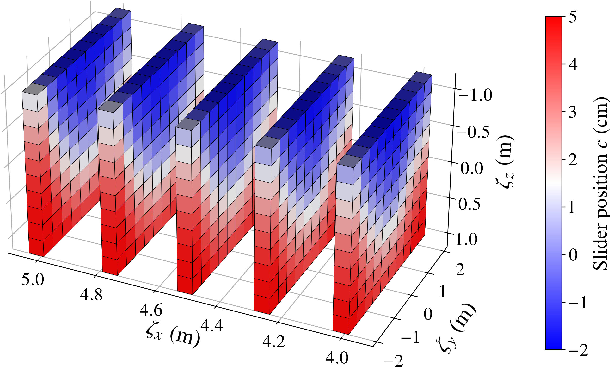
Figure 4: Visualization of the learned outer-level slider policy πϕc; slider adjustment is primarily correlated with target height.
- Tracking accuracy: Bi-Level RL achieves uniformly low RMSE across all targets, outperforming all fixed-slider baselines and PID-SPG by substantial margins. Fixed slider controllers exhibit strong height-dependent performance degradation, confirming the necessity of adaptive CoM configuration.
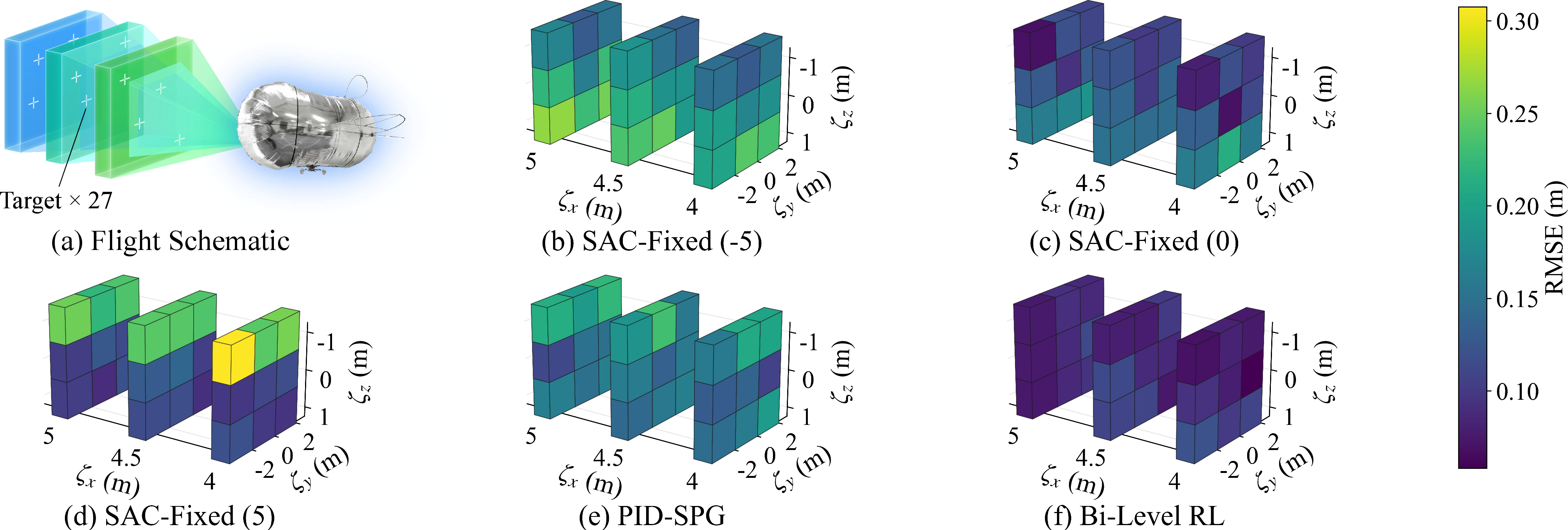
Figure 5: 3D RMSE distributions across the 3×3×3 goal grid; Bi-Level RL yields minimal and consistent errors across all task variants.
- Flight behavior: Real-world flight snapshots demonstrate robust path following for challenging climbing, level, and descending missions, with slider adaptation ensuring optimal pitch attitude control.



Figure 6: Flight snapshots for three representative targets; adaptive slider positions yield precise goal-directed tracking.
- Temporal error profiles: Cross-track errors remain consistently below 0.1m for Bi-Level RL, with fixed-slider baselines exceeding 0.3m in their non-preferred regimes.
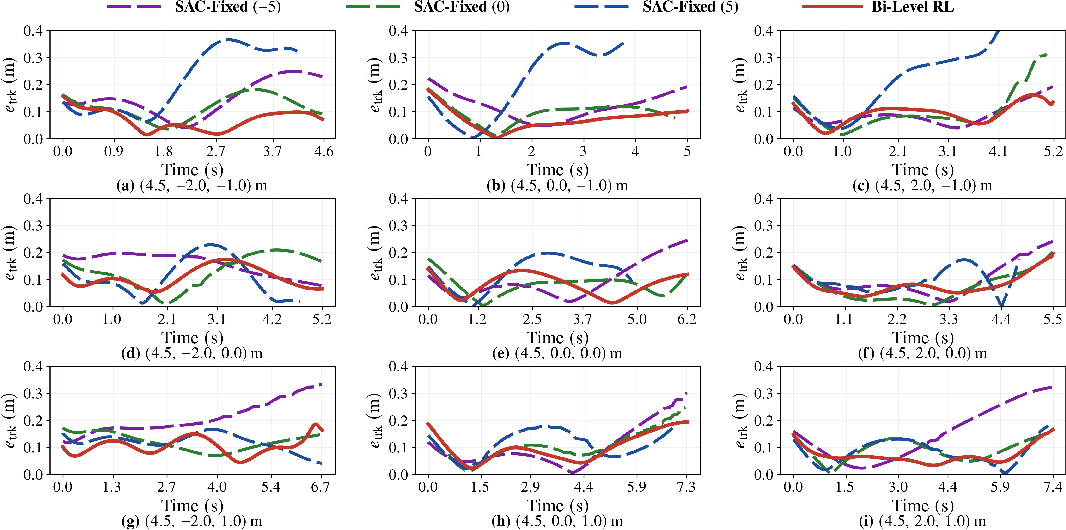
Figure 7: Time histories of cross-track error for nine targets; Bi-Level RL maintains minimal tracking errors throughout all phases of flight.
- RL vs PID: Trajectory comparisons (xy and xz planes) reveal significant deviations and oscillations for PID-SPG, particularly for lateral and altitude control. Bi-Level RL maintains tight adherence to reference paths.
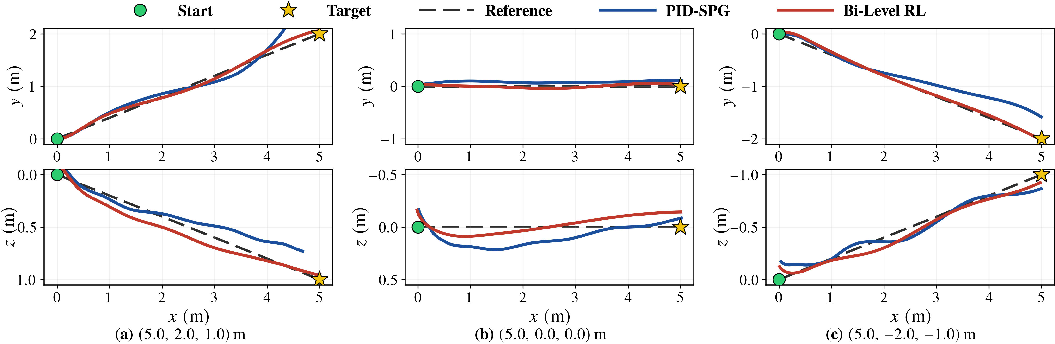
Figure 8: Trajectory comparisons: RL-based inner controller (Bi-Level RL) achieves superior path tracking over PID-SPG with learned slider policy.
The aggregate numerical results indicate RMSE reductions of 30–54% relative to fixed baselines and 46% improvement over PID-SPG, with lower standard deviation highlighting enhanced robustness and consistency.
Practical and Theoretical Implications
The research demonstrates that neither fixed slider placement nor classical PID inner loop suffices for robust goal-directed tracking control in severely underactuated blimps. The bi-level RL design is crucial: the outer loop provides adaptive CoM configuration, while the inner loop leverages deep RL to handle nonlinear, coupled dynamics without dependence on analytical models or manual tuning.
Practically, the approach enables energy-efficient, lightweight blimps to achieve precise autonomous navigation in constrained indoor environments—relevant for persistent sensing, inspection, and human-interactive aerial robotics. Theoretically, the convergence analysis supports broader application of bi-level RL formulations in underactuated, hybrid systems, and hierarchical task decomposition.
Future directions involve extending bi-level RL control to wind-disturbed, outdoor flights, more complex morphologies, and integrating disturbance-aware policies, potentially employing diffusion-augmented RL policies as recently explored in robust legged locomotion [TIE-RL-2026-leg], as well as broader hierarchical architectures for long-horizon tasks [TIE-bi-GTHSL-2025].
Conclusion
This paper establishes a bi-level RL paradigm for underactuated blimp control via center-of-mass reconfiguration. By decoupling slow, task-level CoM planning from fast, continuous thrust actuation, and employing staged RL training, the method addresses severe underactuation and nonlinear coupling, achieving consistent gains in tracking accuracy, robustness, and sim-to-real transfer. The empirical results and convergence guarantees motivate further exploration of hierarchical RL in aerial vehicles and other energy-constrained robotic systems.
(2605.01289)

