- The paper presents GameScope, a benchmark dataset covering 74 games, 3 codecs, and over 150K subjective ratings for gaming video quality assessment.
- It employs controlled bitrate ladders, multi-resolution encoding, and rigorous subjective protocols to ensure high-quality, consistent MOS predictions.
- Benchmark results reveal that vision-language models, especially Qwen3-VL-4B, outperform traditional VQA methods, enabling real-time end-to-end assessments.
GameScope: A Multi-Attribute, Multi-Codec Benchmark Dataset for Gaming Video Quality Assessment
Introduction
The proliferation of game streaming platforms such as YouTube and Twitch necessitates robust, codec-agnostic video quality assessment (VQA) solutions. Historically, VQA benchmarks have failed to capture the diversity present in gaming content across multiple codecs, genres, and resolutions. Furthermore, existing metrics frequently underperform on gaming content due to the distinctive spatiotemporal statistics, overlays, and artifact patterns prevalent in both user-generated content (UGC) and professionally-generated content (PGC). The "GameScope" dataset addresses these limitations by introducing an extensive, rigorously annotated benchmark tailored for gaming video quality assessment.
Dataset Construction and Diversity
GameScope comprises 4048 video samples originating from a pool of 424 source clips spanning 74 unique games, collected to represent both UGC and PGC. UGC sequences are sourced from YouTube under Creative Commons licenses, capturing real-world degradations and overlay complexities, while PGC samples are recorded directly from PS5 hardware to represent pristine gameplay output. The selection process targets maximal visual and genre diversity, encompassing action, simulation, role-playing, puzzle, sports, fantasy, sci-fi, and horror content.
A detailed quantitative analysis of the dataset's visual statistics—spanning brightness, contrast, colorfulness, sharpness, spatial information (SI), and temporal information (TI)—demonstrates broad distribution across critical axes, positioning GameScope as uniquely representative of practical gaming scenarios.


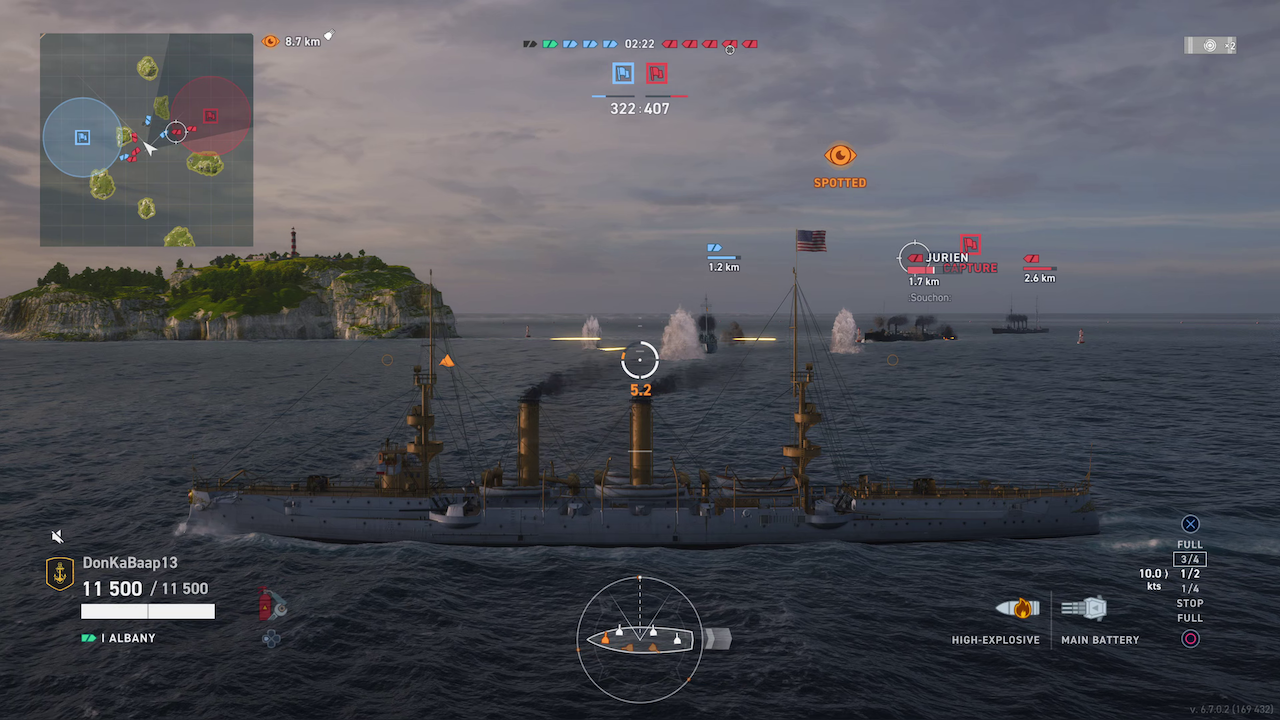
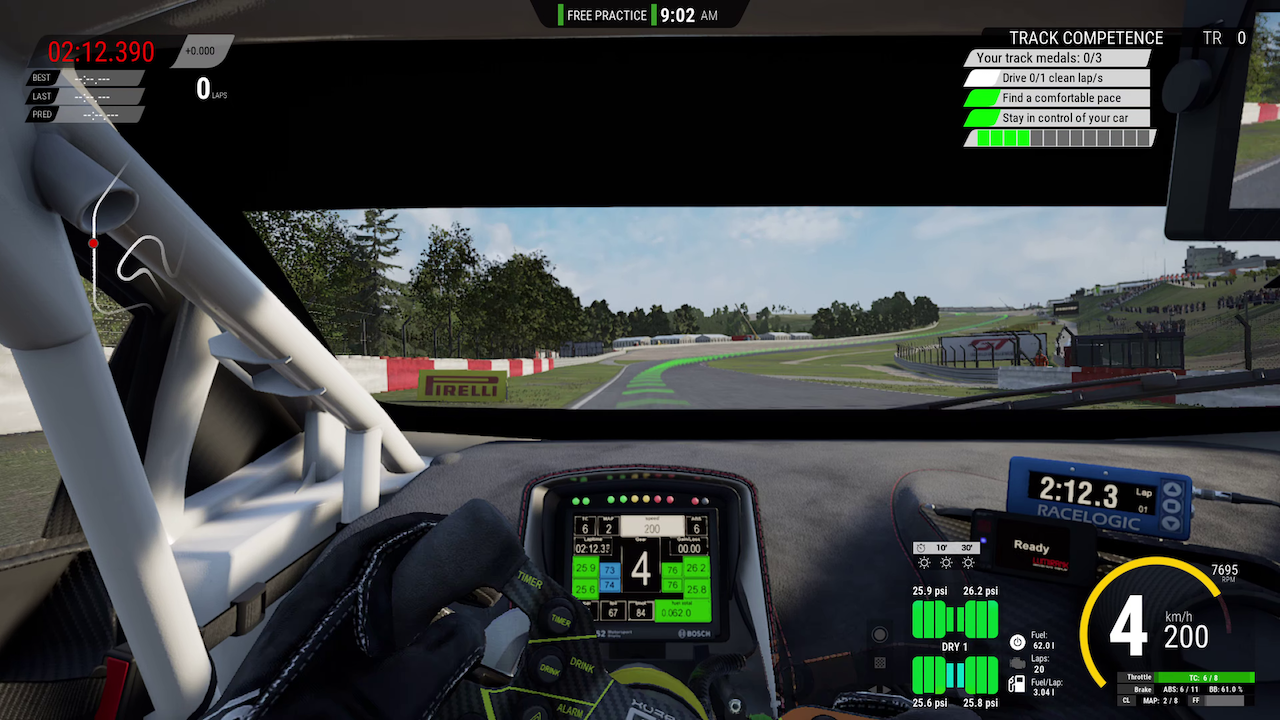







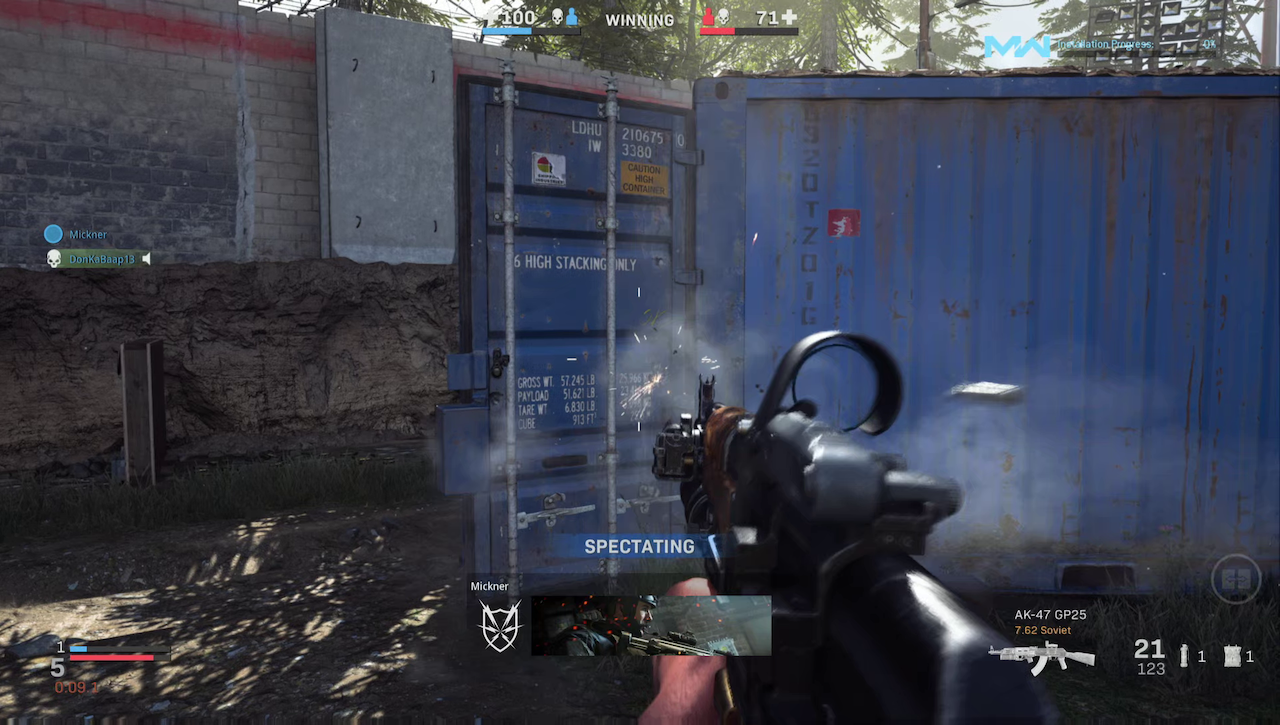
Figure 1: Representative sample frames from the PGC subset of the GameScope dataset, illustrating the diversity of game genres and visual content.
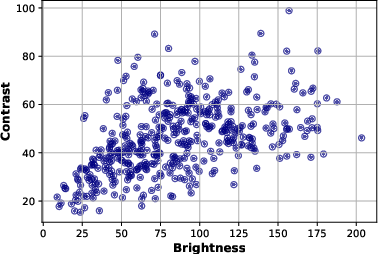
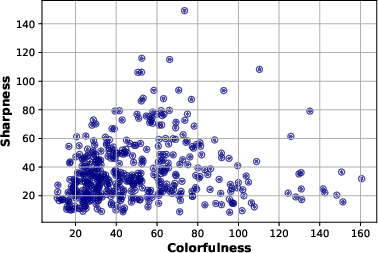
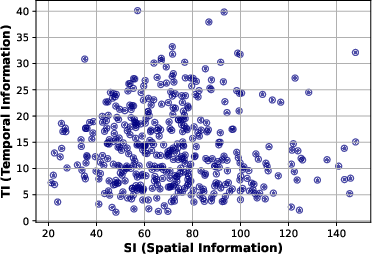
Figure 2: The statistics of source content clips (a) Brightness vs Contrast, (b) Colorfulness vs Sharpness, and (c) Spatial Information vs Temporal Information.
Content was encoded using three major codecs (H.264, H.265, AV1) at multiple controlled bitrates and resolutions (from 360p up to 2160p), calibrated to ensure perceptually distinct quality levels. For each encoder, the adopted bitrate ladder reflects both platform guidelines and empirical perceptual validation, yielding high fidelity in quality differentiation.
Subjective Quality Assessment Protocol
A large-scale subjective study was conducted via Amazon Mechanical Turk (AMT), with each video annotated by an average of 37 participants—a total of 150,874 ratings. The assessment protocol is designed for stringent control and reliability, incorporating progressive qualification phases to balance rating quality and throughput. Subjects rate both overall quality—on a continuous 0–100 scale—and three coarse-grained perceptual attributes: clarity (blur, motion artifacts, color saturation), pixelation/blockiness (encoding artifacts), and immersive experience (the degree of visual immersion, decoupled from gameplay content). Users are provided with quality-diverse exemplars during training, and instructions strongly emphasize technical over aesthetic judgments.
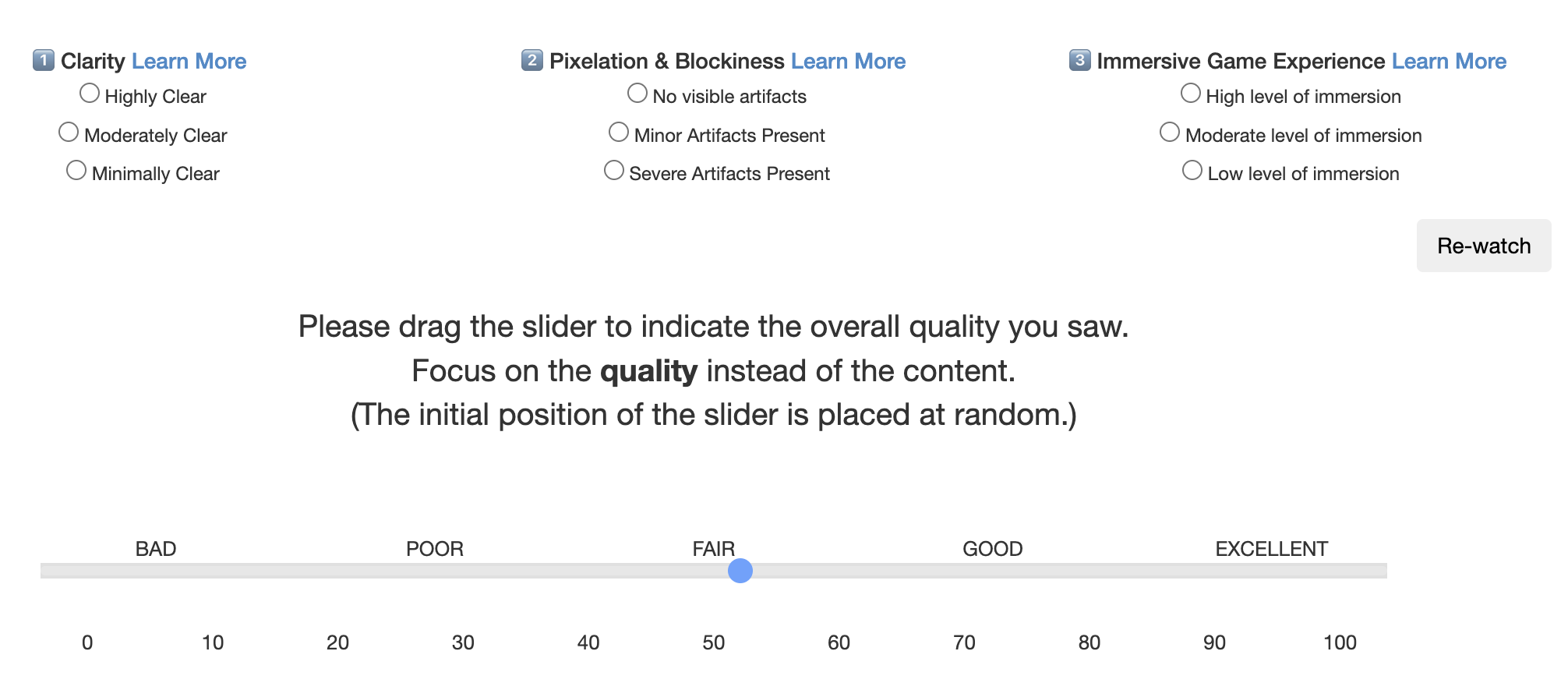
Figure 3: The study template of the subjective quality assessment for collecting quality attributes and overall MOS.
To enforce data integrity, submissions from mobile devices were disallowed, repeated video ratings were used for intra-rater consistency checks, and "golden video" references were embedded to calibrate participant accuracy. Further filtering rejected responses exhibiting low rating dispersion or insincere patterning.
Analysis of Quality Annotations
Post-acquisition, ratings were processed using the SUREAL model, which robustly models subject bias and inconsistency—providing a maximum likelihood estimate of the "true" quality score per video (MOS). The resulting MOS distribution exhibits extensive coverage across the quality spectrum, thereby supporting nuanced VQA benchmarking.
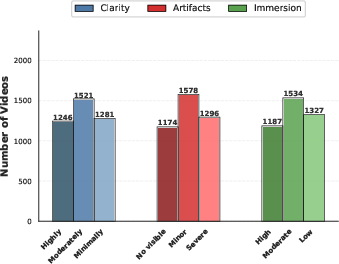
Figure 4: The distribution of quality attributes.
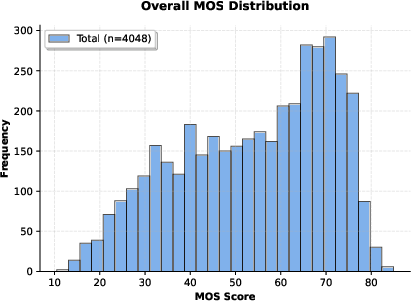
Figure 5: Distribution of collected MOS.
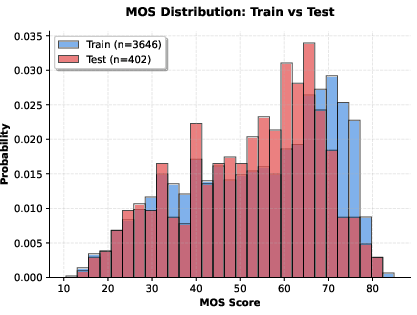
Figure 6: Distribution of the train and test sets against MOS.
Attribute selection by majority vote reveals robust variation across the three assessed perceptual axes, further validated by a split-half analysis yielding a median PLCC and SROCC of 0.92—indicative of high rating reliability and internal consistency.
Benchmarking and Model Evaluation
A protocol with strict UGC/PGC and content separation governs the recommended train-test splits, eliminating content bias and enabling reproducible evaluations. Multiple established VQA algorithms—ranging from classical SVR-based models leveraging hand-crafted features (e.g., TLVQM, RAPIQUE, VIDEVAL, GAME-VQP) to advanced deep architectures (VSFA, FAST-VQA, DOVER, Patch-VQ)—are benchmarked against GameScope. Additionally, large multimodal vision-LLMs (VLMs), notably LLaVA-OneVision-1.5-4B and Qwen3-VL-4B, are evaluated in both zero-shot and fine-tuned scenarios.
Strong numerical results are reported for Qwen3-VL-4B, which achieves PLCC 0.910, SROCC 0.906, KROCC 0.784, and RMSE 0.151 in MOS prediction, outperforming all other approaches—including highly tuned VQA architectures and specialized VLMs—in both MOS and text quality attribute prediction tasks. Notably, Qwen3-VL-4B and LLaVA-OneVision-4B are uniquely able to output both scalar MOS and textual attribute assessments in a single inference, highlighting a critical capability for future end-to-end VQA solutions.
Discussion and Implications
GameScope's design—encompassing vast content diversity, codec multiplicity, granular attribute annotation, and stringent rating protocols—empowers the research community with a resource for comprehensive evaluation of VQA algorithms under conditions reflecting actual streaming platform constraints. Its multi-attribute framework enables both global quality and fine-grained distortion analysis, facilitating the development of more explainable and robust assessment models. The empirical superiority of VLM-based models (especially Qwen3-VL-4B) over traditional pipelines signals a meaningful paradigm shift, attributable to their data scale, multimodal capability, and semantic grounding.
Practically, these results indicate that VLMs can be deployed for real-time, multi-faceted gaming VQA without bespoke feature engineering, provided compute resources allow. Theoretically, GameScope offers fertile ground for transfer learning, cross-domain adaptation, and multi-task VQA research, with implications for streaming optimization, perceptual metric design, and automated moderation.
Conclusion
GameScope establishes a new standard for gaming VQA datasets, combining unprecedented scale, codec and genre coverage, and nuanced subjective annotation. Benchmark results demonstrate the potential of large vision-LLMs to subsume and exceed conventional VQA pipelines. This dataset is positioned to serve as a foundational benchmark, enabling advancement in both the theoretical modeling and practical deployment of perceptual video quality solutions tailored to the gaming context.

