- The paper demonstrates that a tailored generative RIR augmentation framework significantly reduces speaker distance estimation error by optimizing FastRIR with source-receiver distance conditioning.
- The methodology fine-tunes state-of-the-art SDE models with rigorously filtered synthetic RIRs, lowering mean absolute error from 1.66 m to 0.6 m on the GWA dataset.
- The study underscores practical implications for robust spatial audio systems and offers a blueprint for domain-specific augmentation in far-field ASR and scene understanding.
Generative Augmentation for Robust Speaker Distance Estimation
Introduction
The paper "Towards Improving Speaker Distance Estimation through Generative Impulse Response Augmentation" (2605.00721) addresses the central challenge in acoustic ML applications of accurately estimating the distance between a speaker and a microphone in reverberant environments, given limited annotated room impulse response (RIR) data. By leveraging generative data augmentation, specifically tailored modifications of FastRIR conditioned on relative source-receiver positions, the authors explore how synthetic RIRs can be used to substantially enhance model performance in the ICASSP 2025 SDE (Speaker Distance Estimation) Challenge, which forms part of the broader goal of improving the reliability of acoustic modeling for both consumer and industrial audio systems.
Generative RIR Augmentation Framework
The methodology pivots on two interconnected stages: augmentation of RIR data and subsequent fine-tuning of state-of-the-art SDE models with the augmented corpus. FastRIR, a GAN-based neural RIR generator, is systematically modified to remove explicit room geometry conditioning, focusing exclusively on encoding source and receiver coordinates. Conditioning is restricted to distance, exploiting the insight that, under moderately homogeneous room acoustics, this is the dominant variable influencing RIR structure for SDE.
Pre-training leverages 100,000 real RIR samples from the GWA dataset, followed by dataset-specific fine-tuning for Treble and GWA to optimize for the particular statistical characteristics of each simulation environment. The tailoring of the generator ensures that synthetic RIRs reflect the empirical distribution of speaker positions in practical indoor settings.
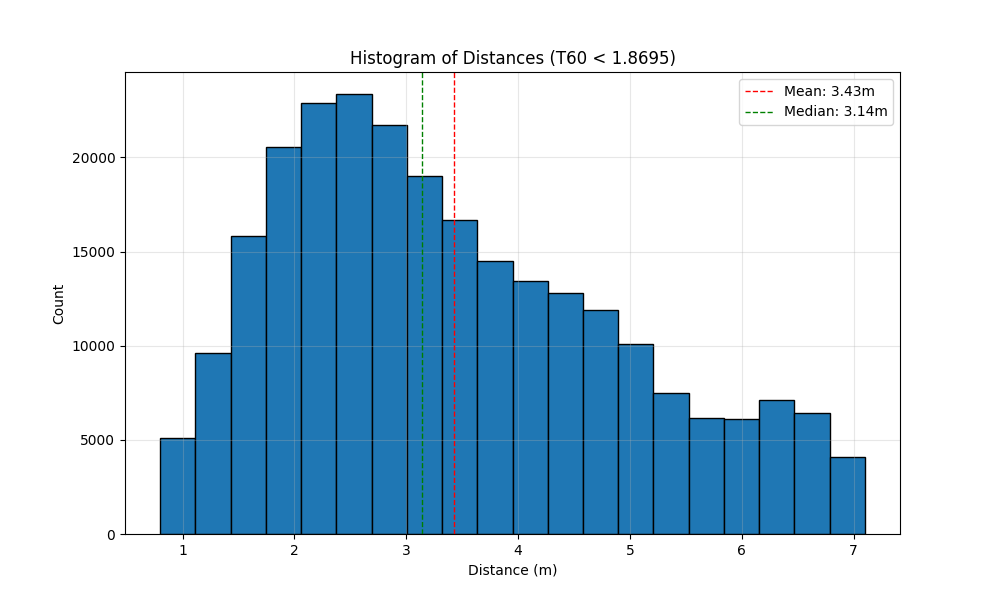
Figure 1: Distribution of the speaker distances used for SDE training, showing alignment with expected real-world distances.
Quality Control and Selection
A critical component is a rigorous filtering pipeline to maintain physical plausibility of synthetic RIRs, discarding those with anomalous reverberation times, extreme direct-to-reverberant ratios (DRR), or unphysical energy decay curves. Approximately 25% of generated examples pass this filter, ensuring that the augmented dataset maintains statistical and physical consistency with empirical RIRs from the challenge corpora. This filtering is not only vital for preserving model generalization but also for avoiding overfitting to synthetic pathologies.
The SDE model, built on the latest architectures [neri2024speaker], is fine-tuned using the high-quality augmented dataset. A hyperparameter search is implemented across learning rates (1e-5 to 1e-3) and training epochs (5–50) to minimize mean absolute error (MAE) on the Treble and GWA test partitions. This systematic tuning, combined with data-centric augmentation, markedly reduces estimation error, especially at intermediate and long-range distances.
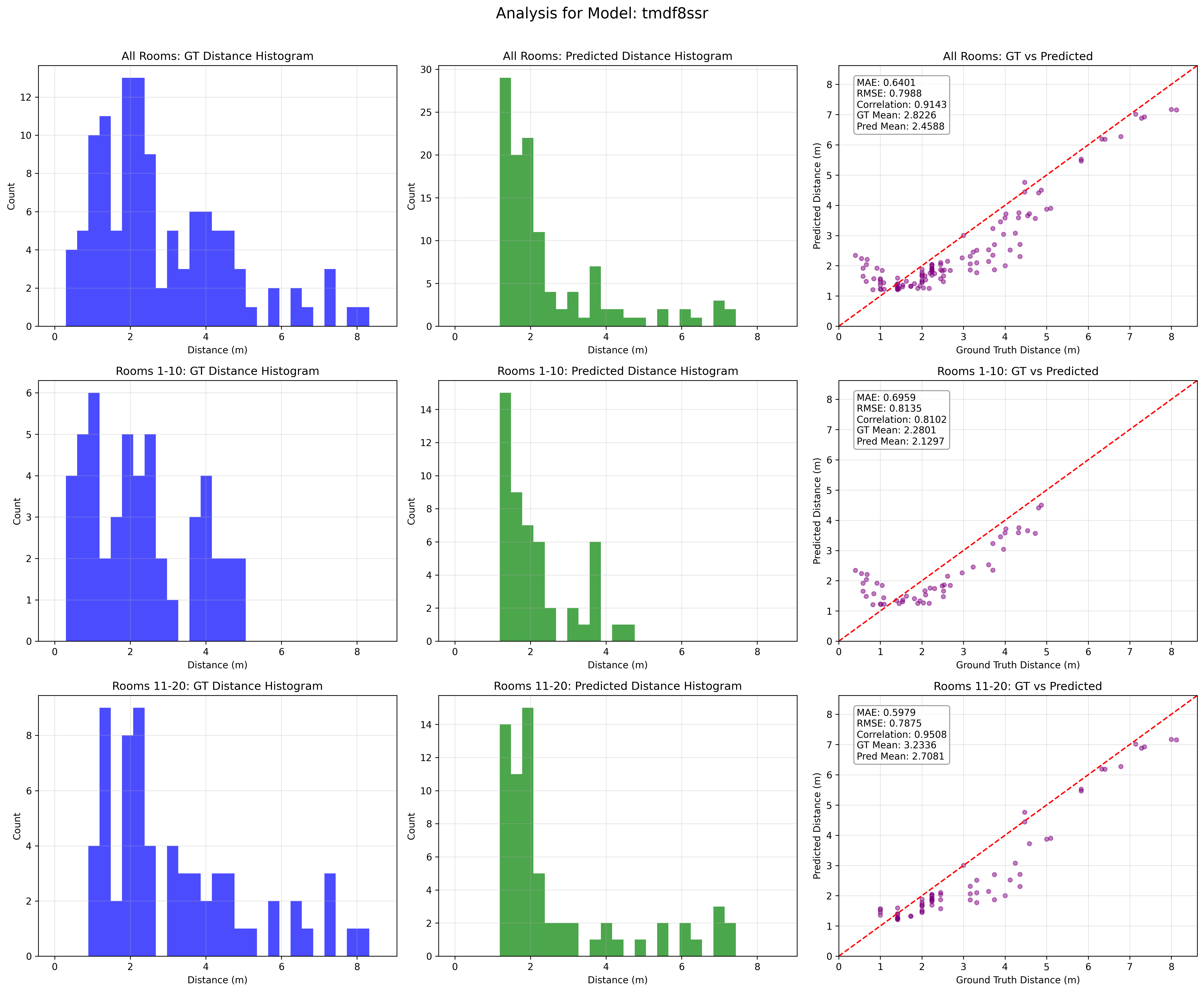
Figure 2: SDE model performance across datasets. MAE decreases markedly with augmentation, and predicted-to-true scatter plots show high correlation, especially in GWA rooms.
Comparative Analysis and Dataset-Specific Modeling
Empirical analyses demonstrate that the unified augmented approach reduces MAE from 1.66 m to 0.6 m (GWA) and from 2.18 m to 0.69 m (Treble), yielding improvements across the board, but especially for GWA rooms characterized by larger speaker-microphone distances. Further experiments with dataset-specific models (fine-tuned separately on Treble or GWA) yield additional reductions of 10% and 5% respective MAE, evidencing the utility of simulation-specific specialization.
Such results underscore both the practical and theoretical value of tightly controlled generative data augmentation: By better matching the acoustic statistics and reflection dynamics, especially as demonstrated through reflection pattern analysis, the SDE model learns robust mappings applicable to both close- and far-field scenarios.
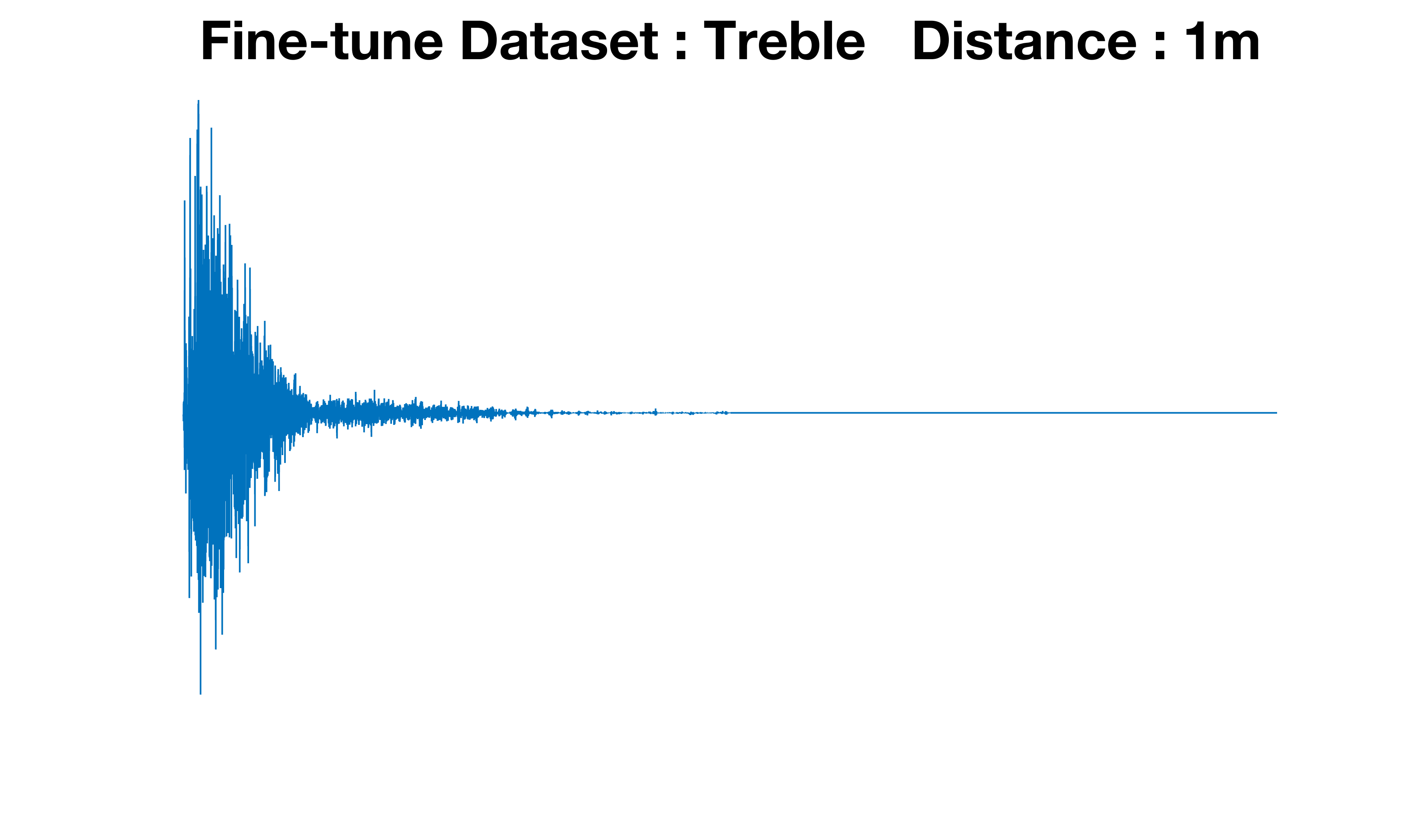
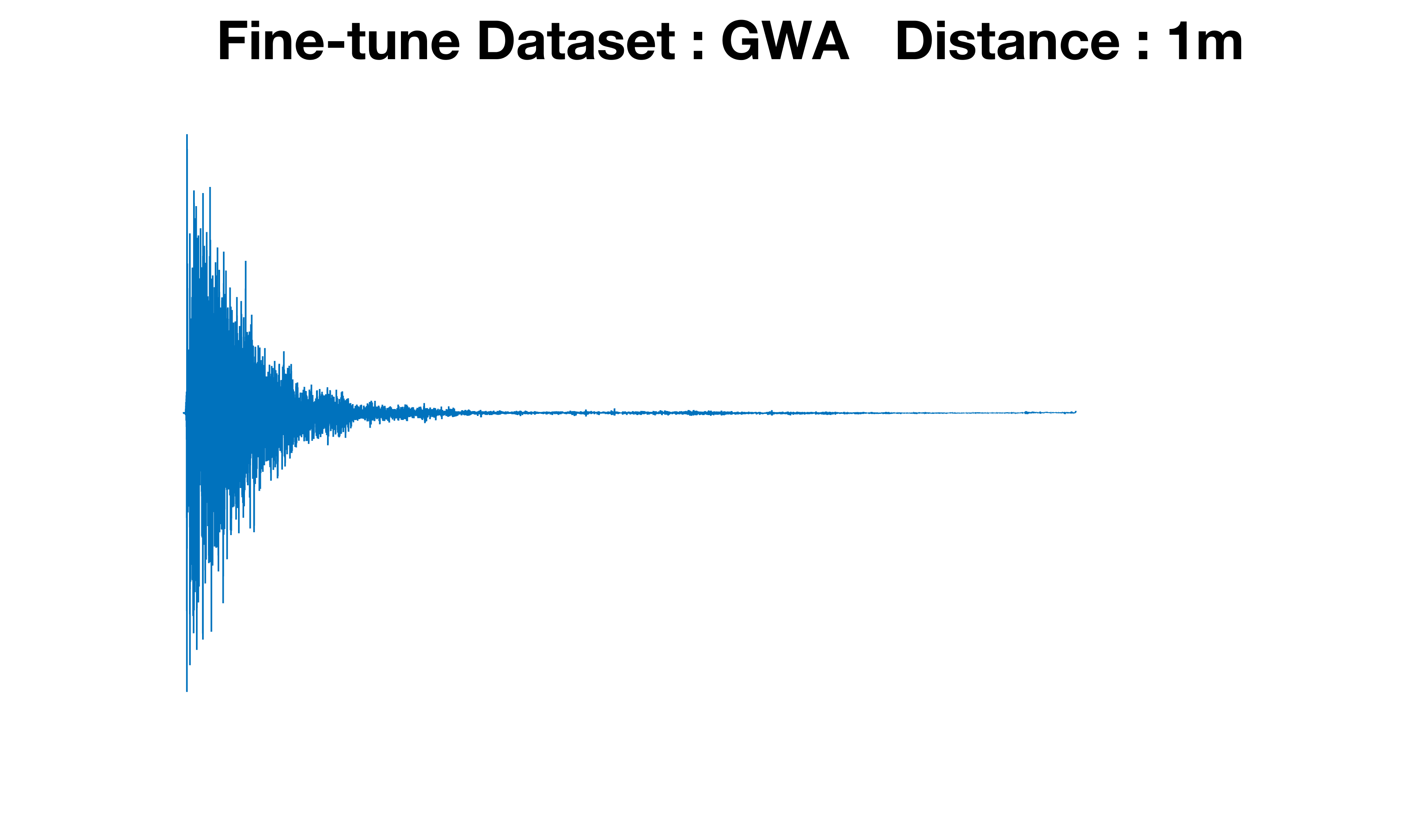
Figure 3: Comparison of RIRs generated with Treble vs. GWA fine-tuning. Reflection structure adapts to dataset characteristics, reinforcing the benefit of source-specific generative modeling.
Theoretical and Practical Implications
From a theoretical standpoint, this work validates the sufficiency of position-only conditioning for generating augmented datasets effective in SDE tasks in typical interior settings, provided quality control constraints are strictly enforced. The clear performance gains validate a data-centric ML paradigm for acoustic signal processing, where generalization is primarily a function of diversity- and realism-preserving augmentation.
Practically, these findings have profound implications for robust speech and spatial audio systems deployed in settings where collecting large, labeled RIR data is infeasible. The approach provides a blueprint for domain-specific augmentation pipelines applicable to a range of tasks beyond SDE, such as far-field ASR, diarization, and scene understanding.
Future Directions
Potential research extensions include combining multiple generative models to more accurately capture edge-case acoustics (e.g., rare materials, highly non-rectangular geometries), explicit modeling for <1 m scenarios where extremely near-field effects dominate, and applying this approach in-microphone array or dynamic (moving source/receiver) settings. There is scope for improved unsupervised or self-supervised filtering methods for higher-yield and domain adaptation, as well as the integration of more physically-informed generation pipelines.
Conclusion
The study systematically demonstrates that generative augmentation, especially under tight physical and statistical quality constraints, markedly advances SDE accuracy across realistic indoor scenarios. The methodological rigor of data selection, filtering, and simulation-specific fine-tuning establishes a strong foundation for future research in robust acoustic ML, with immediate applicability to deployed speech systems reliant on precise spatial awareness.