- The paper introduces a novel mini-batch risk estimator and a multipattern MDP framework for scalable risk-averse reinforcement learning.
- It generalizes Bellman equations using Markov risk measures to enable unbiased, sample-efficient Q-function approximation.
- The method demonstrates robust empirical performance with reduced variance and computational overhead in stochastic and bandit problems.
Risk-Averse Reinforcement Learning via Markov Risk Measures and Multipattern Risk Approximation
Introduction and Problem Setting
The paper "Reinforcement Learning with Markov Risk Measures and Multipattern Risk Approximation" (2605.00654) presents a rigorous treatment of reinforcement learning (RL) under coherent risk measures, introducing new algorithmic and analytical frameworks to extend risk-averse control to large-scale and function-approximated settings. The primary focus is on finite-horizon, generative model settings, where the objective is to optimize not expected cumulative cost, but a Markovian dynamic risk measure, which generalizes popular criteria such as mean, CVaR, and spectrally-mixed variants.
Classical approaches for risk-averse RL are limited in scalability due to their tabular nature and the high complexity of risk estimation, which is generally nonlinear and statistically intensive. To address this, the authors introduce two principal innovations: (1) mini-batch Markov risk measures, offering unbiased and tractable statistical estimators for transition risk; and (2) the formalization of multipattern MDPs, extending the standard linear MDP structure to broader classes that allow Q-function linearity in features even with complex, non-linear risk criteria.
Markov Risk Measures and Statistical Risk Estimation
The foundational element is the recursive, time-consistent Markov risk measure ρ1,H for cost sequences, inducing dynamic programming (DP) recurrences that generalize the Bellman optimality equations to the risk-averse case. The transition risk mapping σ(x,P,V) captures the risk-adjusted value of future states, and admits forms such as mean-semideviation, AVaR, and worst-case.
To make statistical estimation of σ tractable in generative settings, the key idea is to use mini-batch risk measures: for base coherent risk mapping σb, an unbiased sample-based estimator is formed by considering the expected risk evaluation over an empirical measure from N sampled transitions. This construction ensures coherence and provides a path to sample-efficient risk learning even in high dimensions, bypassing the need for large batch sizes or double-sampling.
Multipattern MDPs and Q-Function Approximation
Building on the risk estimator, the paper introduces the multipattern MDP—a generalization where, for any state-action pair, the cost and risk can be written as a (weighted) sum of d basic risk patterns, each corresponding to a coherent risk measure. This model subsumes the standard linear MDP setting but allows for arbitrary convex combinations and richer feature-based representations, giving rise to a linear structure in the Q-function even under non-linear risk mappings.
Given features φ(x,a), the optimal risk-adjusted ρ1,H0-function is parameterized as ρ1,H1, with ρ1,H2 to be learned. This enables scalable RL via regression-based function approximation, overcoming the intractability of tabular risk-aware learning in large state-action spaces.
Algorithmic Solutions and Theoretical Guarantees
A risk-averse ρ1,H3-learning algorithm with linear function approximation is derived, combining least-squares regression for weight updates with mini-batch based, unbiased risk estimators as targets. The method accommodates both full and lazy/backward-efficient policy evaluation (the latter updating minimizations infrequently to save computation).
The convergence of the algorithm is established via a high-probability regret bound of order ρ1,H4, where ρ1,H5 is the horizon, ρ1,H6 the mini-batch size, and ρ1,H7 the number of episodes. This result generalizes recent advances in linear MDPs to the risk-averse case and demonstrates strong sample efficiency and statistical reliability, even with non-trivial risk aggregation.
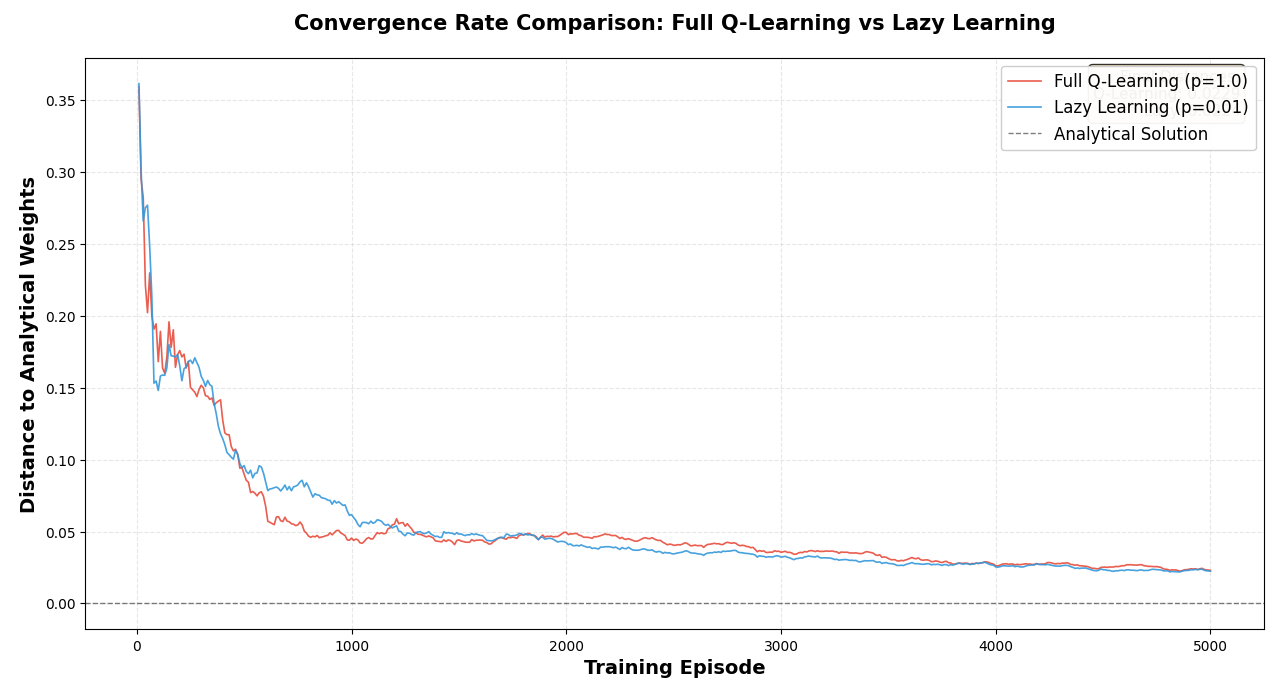
Figure 1: The learning error ρ1,H8 as a function of the number of episodes during full ρ1,H9-learning and "lazy" learning (batch size σ(x,P,V)0) on an 8-stage stochastic assignment problem with Bernoulli rewards.
Empirical Evaluation
The method is validated on two classic yet challenging settings: a stochastic assignment problem with known analytical optimal policy, and a short-horizon multi-armed bandit problem with Bayesian state updates.
For the stochastic assignment problem, the feature-based risk-averse σ(x,P,V)1-learning algorithm accurately converges to the optimal policy coefficients in both full and lazy evaluation modes, with the "lazy" variant achieving similar performance at about half the computational cost. When mini-batch risk of the form "expectation + minimal value (worst-case)" is used, the learned risk-averse policies produce empirical performance curves with lower variance and expected reward closely matching analytical optima.
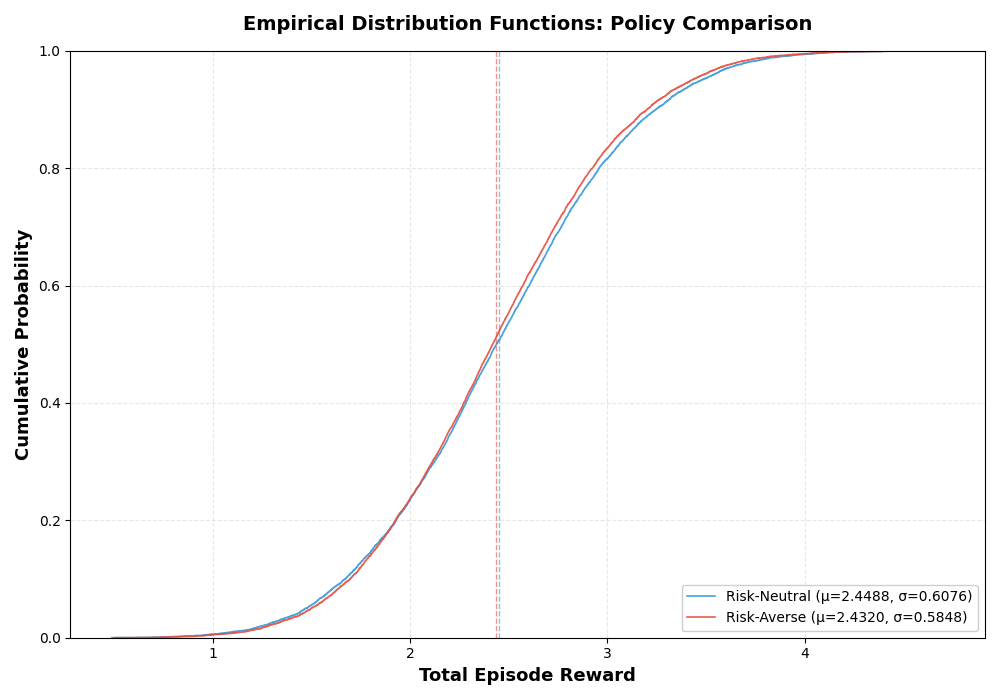
Figure 2: The distribution functions of optimal policy performance for an 8-stage stochastic assignment problem in risk-neutral and risk-averse cases.
Application to the Bayesian multi-armed bandit problem further demonstrates the framework’s robustness: risk-averse policies outperform risk-neutral baselines in both mean and variance in cases of high uncertainty or limited prior knowledge, with the advantage diminishing as the horizon increases and information accumulates.
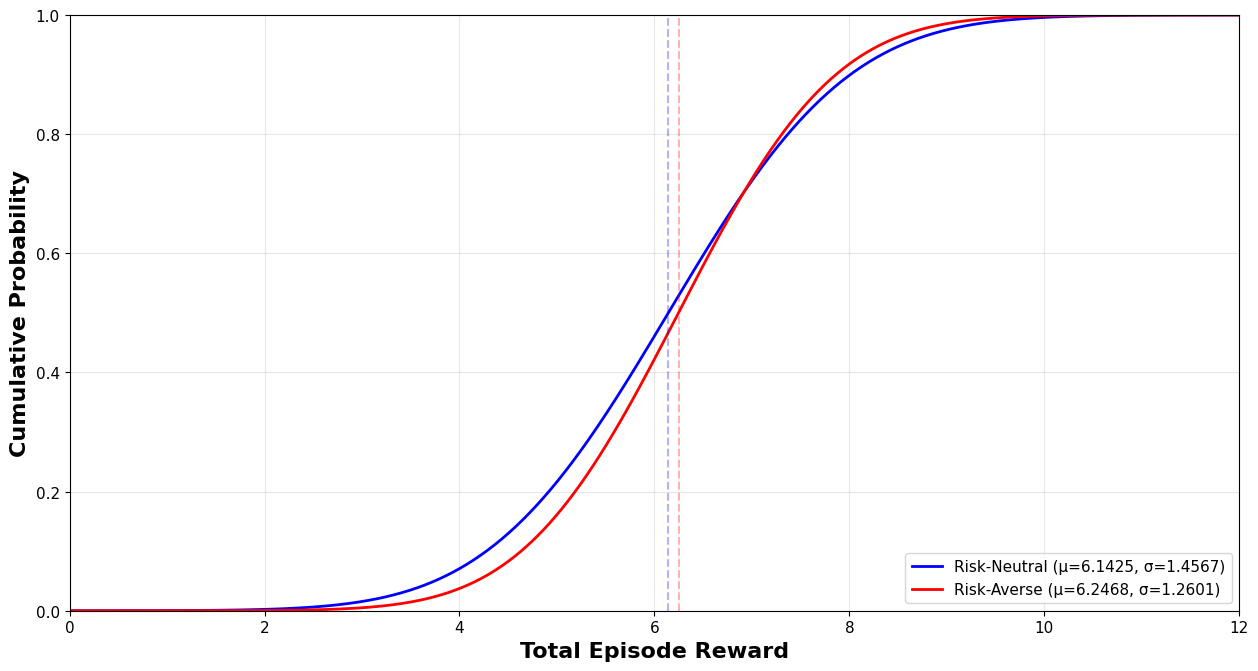
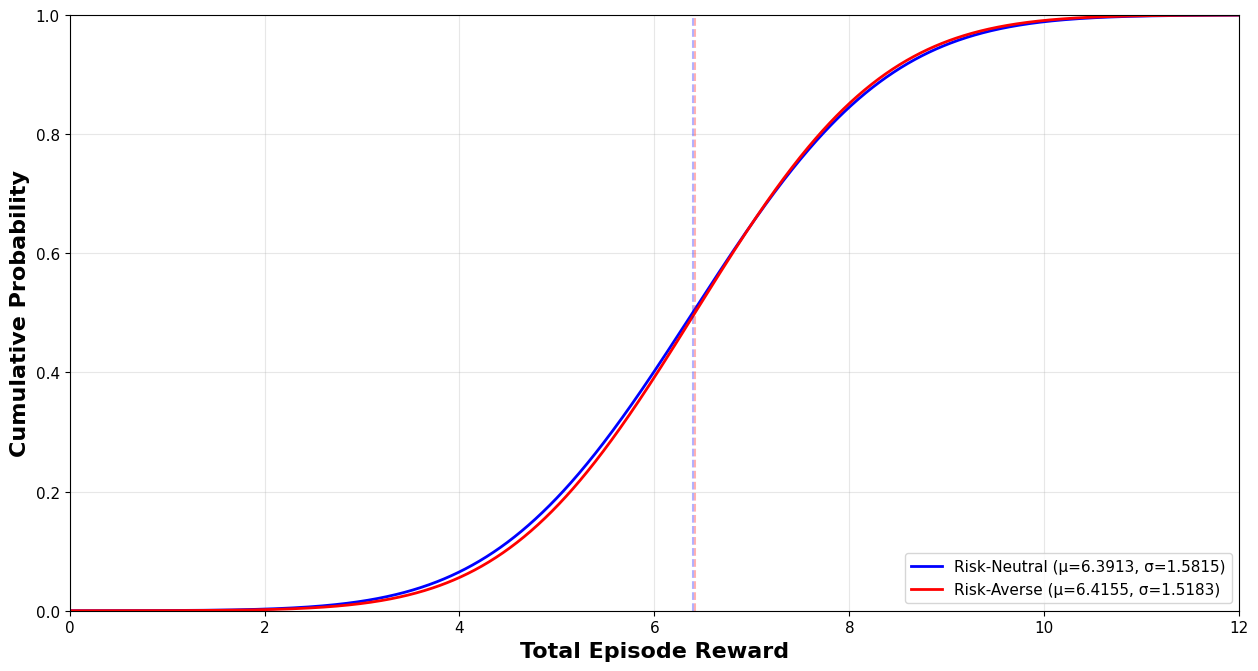
Figure 3: The distribution functions of optimal policy performance in a multi-armed bandit problem with a non-informative initial state, showing mean/variance trade-offs in risk-neutral versus risk-averse policies.
Theoretical and Practical Implications
This framework substantially widens the tractable class of RL problems under general, coherent risk objectives, breaking through the scalability and accuracy barriers of prior work. The introduction of mini-batch risk enables unbiased and computationally efficient estimation without the overhead of large samples or double sampling, a key limitation in previous literature.
The multipattern MDP formulation is particularly relevant—function approximation for risk measures is notoriously challenging, as the nonlinearity of risk means Bellman-like equations can lose their linear structure. By decomposing risk via features and convex combinations, the approach maintains analytical tractability and aligns with universal approximation frameworks, suggesting potential extensions to deep architectures.
Empirically, the finding that risk-averse learning may sometimes yield higher expected performance than risk-neutral learning in the presence of model or estimation mismatches is notable; this implies a form of regularization induced by risk objectives, which may be leveraged in robust or off-policy RL contexts.
Future Directions
The principled framework for risk-aware RL developed here lays the groundwork for several avenues. Extensions to infinite-horizon, discounted settings and continuous spaces appear feasible, and the mini-batch approach opens up unexplored pathways for combining risk-sensitivity with nonlinear (e.g., deep) function approximation. Extensions to online or partially observable RL and broader classes of risk functionals, as well as integration with distributional RL methods, are promising.
From an applications perspective, the approach enables risk-aware control and resource allocation in domains where variance or rare-event sensitivity is critical (e.g., finance, healthcare, safety-critical automation), without sacrificing scalability.
Conclusion
This work rigorously addresses risk-averse RL at scale, proposing unbiased and tractable mini-batch risk measures and demonstrating high-probability regret bounds in multipattern, feature-based MDPs. The methods yield robust empirical performance across varied domains and open compelling directions for both theoretical exploration and application—particularly regarding function approximation under complex risk objectives and robustness in policy learning.