- The paper introduces FedHAW, which leverages online hypergradient descent to dynamically update aggregation weights during each training round.
- It achieves state-of-the-art performance on non-IID datasets like MNIST and CIFAR-10, maintaining high accuracy even under severe communication failures.
- The algorithm operates with minimal computational overhead, making it ideal for resource-constrained and latency-critical federated learning deployments.
Federated Learning with Hypergradient-based Online Update of Aggregation Weights
Introduction and Motivation
This work presents FedHAW, a federated learning (FL) algorithm that introduces hypergradient-based, online adaptive weight updating in model aggregation. Conventional FL strategies must address both non-IID data heterogeneity and communication unreliability—ubiquitous in mobile and IoT scenarios. Traditional approaches like FedAvg and variants rely on fixed or heuristically adapted aggregation weights and either assume homogeneous client data or seek ad hoc strategies for dynamic environments.
FedLAW advances aggregation robustness by learning aggregation weights but incurs substantial overhead due to repeated auxiliary dataset requirements and high computational cost, limiting practicality in resource-volatile, bandwidth-constrained, or rapidly changing settings.
FedHAW circumvents these bottlenecks by updating the aggregation weight vector and its ℓ1-norm scale in an online fashion using hypergradient descent—computing the gradient of the outer objective with respect to aggregation weights at each round with negligible additional cost. This enables real-time adaptation to data distribution shifts and communication failures without dependency on proxy datasets or multi-stage optimization.
Algorithmic Framework: FedHAW
At each FL round, FedHAW proceeds as standard FL: clients perform multiple epochs of local updates on their data, and a server aggregates the received model updates. However, instead of fixed or externally learned aggregation weights, FedHAW includes λ(t) (relative weights for clients, input to softmax for normalization) and γ(t) (global scale factor). These parameters are updated in every round via hypergradient steps, computed as the outer loss’s gradient with respect to these aggregators.
The update rules for the aggregation weights operate with the following characteristics:
- Online Hypergradient Descent: For each round t, the server computes an approximate outer gradient on the global loss function f(w(t)) with respect to both λ(t) and γ(t). Due to the surrogate derivation, this can be achieved using only already-computed model differences and avoids explicit second-order derivative computations.
- Softmax and Exponential Reparametrization: The relative weights are normalized via a softmax transformation to ensure a valid simplex, while the scale factor is parameterized exponentially to guarantee positivity and smooth regularization.
- Communication Error Model: When client updates are corrupted or not received, the aggregation retains the previous or current global parameter as fallback, naturally handled by the weight vector arrangement and incorporated into the hypergradient computation.
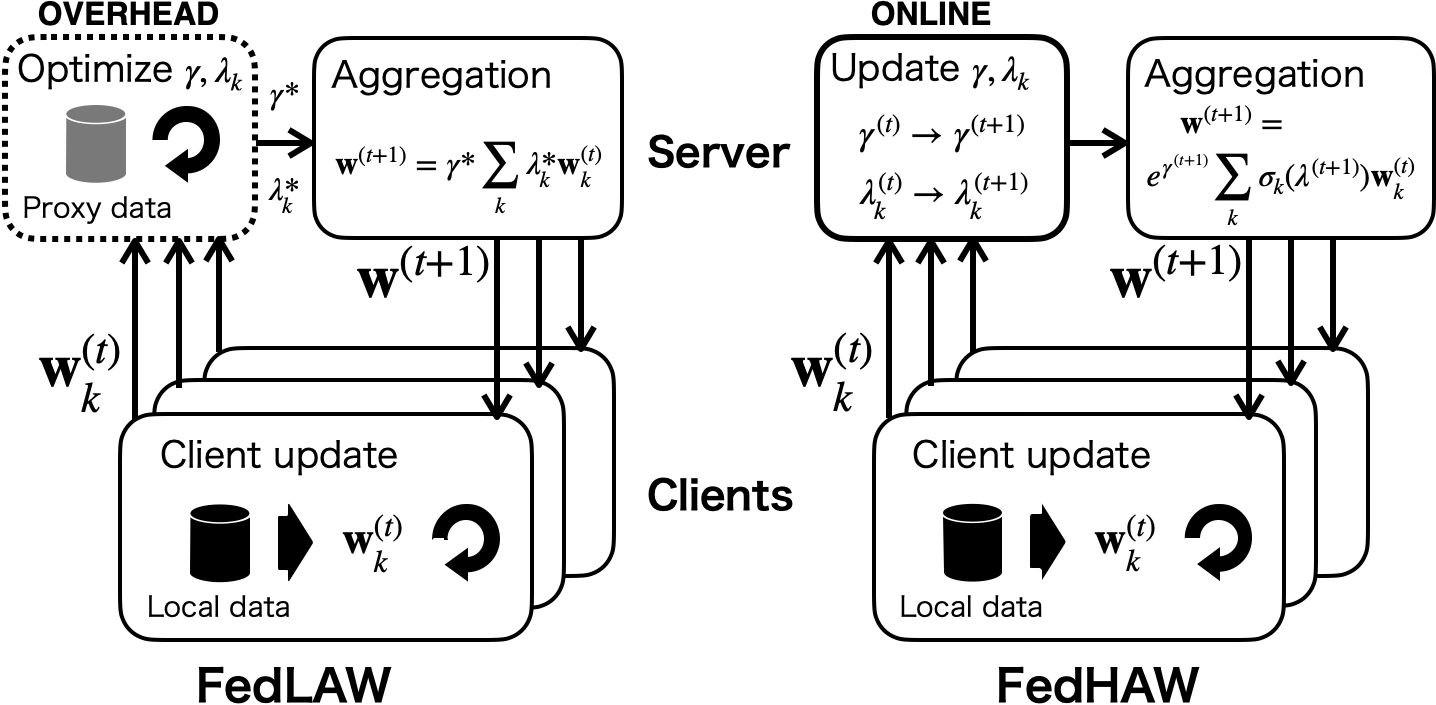
Figure 1: Schematic of algorithmic differences between FedLAW, requiring separate proxy dataset optimization, and the proposed FedHAW, which performs online aggregation weight updates during each training round.
Analytical Properties and Implementation
FedHAW’s design ensures that computation of the gradients required for aggregation weight updates is efficient and approximately unbiased. Since the updates utilize model differences between global and locally trained weights, and these are computed in the FL communication protocol, overhead is minimal.
The approach is agnostic to the specific client-side optimizer (e.g., SGD, Adam, FedProx), focusing only on the weight difference per client per round, and is thus compatible with a wide range of local update schemes.
In the presence of erroneous client communication, the fallback to the prior global aggregation ensures stability and prevents catastrophic drift.
Empirical Results
Heterogeneous Data Distributions: In experiments on MNIST, CIFAR-10, and Stanford Dogs under strongly non-IID splits, FedHAW consistently matches or surpasses online aggregation baselines (FedAvg, FedAdp, FedHyper, FedLWS) and approaches or even exceeds FedLAW—particularly when proxy datasets do not perfectly represent client data distributions. Notably, FedHAW establishes the highest test accuracy among online methods for several configurations, including highly skewed (Dirichlet parameter α=0.1) splits.
Practical Overhead: The runtime cost of FedHAW’s aggregation logic at the server is orders of magnitude lower than FedLAW (comparable to FedAvg, FedLWS, FedHyper), enabling deployment in latency-critical and resource-constrained environments.
Robustness to Communication Errors: FedHAW shows resilience to high communication error rates (pe=0.8): per-round analysis on CIFAR-10 reveals that it maintains superior accuracy even when a large fraction of clients fail to communicate fresh local models.
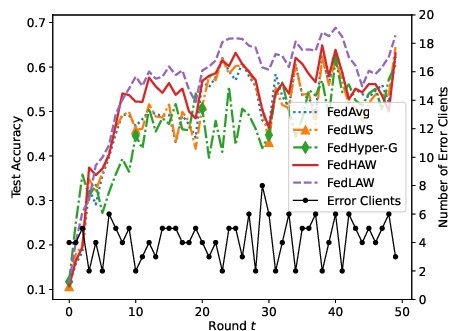
Figure 2: Per-round test accuracy and number of clients suffering from communication errors on CIFAR-10 with pe=0.8. FedHAW demonstrates higher stability in adverse communication scenarios.
Adaptability to Optimizers: The modular aggregation-weight updating can be seamlessly combined with sophisticated client optimizers such as FedProx, yielding consistent gains over aggregation baselines at all training stages.
Implications and Future Directions
FedHAW drives substantial improvements in practical FL deployment by closing the gap between robust, adaptive performance and computational/operational feasibility. Its online, hypergradient-based weight control is directly extensible to other aggregation-control schemes whenever the coefficients are differentiable, and the model difference signals are available.
Practical implications are pronounced for edge/IoT deployments with:
- Highly Non-IID Data: As the degree of data heterogeneity in client populations grows, real-time aggregation tuning without reliance on representative auxiliary data is essential.
- Unstable Bandwidth: The communication-aware adaptation in FedHAW ensures graceful performance degradation and higher accuracy retention even with sporadic client participation.
- Modular Design: Compatibility with varied client updates allows integration with recent personalization or regularization strategies.
Theoretically, this demonstrates the relevance and utility of meta-optimization across the communication-aggregation interface in distributed learning, motivating further research into higher-order optimization dynamics for system-level parameters (e.g., compression schemes, participation schedules).
Future work may explore: scaling to massive client populations, theoretical convergence and robustness analysis in more adversarial link scenarios, and task-specialized aggregation hyperparameterization in end-to-end FL workflows.
Conclusion
FedHAW introduces efficient, online hypergradient-based aggregation weight updates for FL, yielding high adaptability to non-IID data and communication errors, without dependence on auxiliary datasets or expensive optimization. The algorithm provides a practical approach for robust distributed learning and establishes a foundation for broader meta-optimization in FL architectures.
Reference: "Federated Learning with Hypergradient-based Online Update of Aggregation Weights" (2605.00458)