- The paper introduces MMAudioReverbs, repurposing a multimodal V2A model for both dereverberation and room impulse response estimation through targeted fine-tuning.
- It demonstrates superior performance over baselines using metrics like RTE, SRMR, and DNSMOS, highlighting the role of visual cues in early reflection modeling.
- The approach offers scalable solutions for multimedia applications and paves the way for integrating explicit geometric and material priors in future research.
MMAudioReverbs: Video-Guided Acoustic Modeling for Dereverberation and RIR Estimation
Overview and Motivation
The MMAudioReverbs framework leverages pretrained multimodal video-to-audio (V2A) foundation models to explicitly address two critical tasks in physical room acoustics: dereverberation and room impulse response (RIR) estimation. Recognizing that prior V2A systems primarily target content realism without modeling acoustics explicitly, MMAudioReverbs repurposes the MMAudio foundation model, hypothesizing that it encodes implicit scene-related priors relevant to acoustics due to joint vision-audio training. The approach forgoes architectural modifications and specializes the model for physical tasks through targeted fine-tuning.
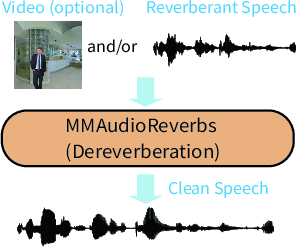
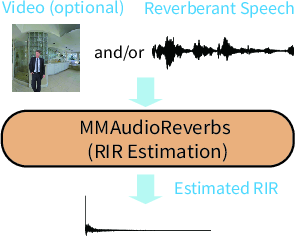
Figure 1: MMAudioReverbs addresses dereverberation and RIR estimation leveraging the V2A backbone with multimodal conditioning.
Unified Methodology and Architectural Insights
At its core, MMAudioReverbs adopts the MMAudio backbone, which operates in the latent space of a variational autoencoder (VAE) and employs a flow-matching objective for multimodal generative modeling. Conditioning signals—either audio alone or both audio and video—modulate latent trajectories to yield outputs consistent with the physical properties of a given scene. The task specification is realized by reinterpretation of the conditioning and output latent trajectories, without modifying network parameters or modules.
Notably, MMAudioReverbs realizes both dereverberation (mapping reverberant to clean speech) and RIR estimation (generating RIRs conditioned on reverberant audio and optional vision cues) without architectural change, instead swapping only task-specific heads. All model parameters remain shared, and training employs the same backbone, which enables direct evaluation of multimodal priors for physical scene analysis and acoustic processing.
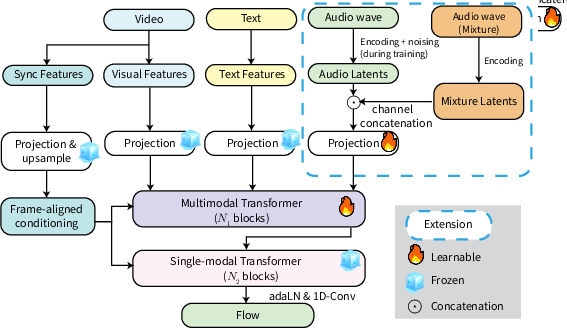
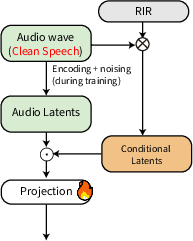
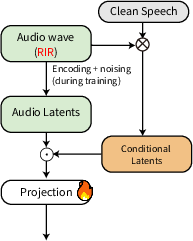
Figure 2: MMAudioReverbs is built upon the MMAudio multimodal backbone, adaptively addressing dereverberation and RIR estimation through task-specific reinterpretation under a unified architecture.
Experimental Analysis and Numerical Results
The empirical evaluation employs the SoundSpaces-Speech dataset and benchmarks against established audio-only and audio-visual methods. Two model initialization regimes are considered: (i) random initialization (trained from scratch) and (ii) fine-tuning from pretrained MMAudio weights. At inference, both audio-only and audio+vision conditioning are assessed.
Dereverberation
Quantitative results demonstrate that MMAudioReverbs (both from scratch and fine-tuned) consistently outperforms baselines like VIDA and WPE in terms of Reverberation Time Error (RTE), Speech-to-Reverberation Modulation Energy Ratio (SRMR), and DNSMOS. Notably, outputs from MMAudioReverbs trained via fine-tuning show further improvement, lowering RTE compared to training from scratch, substantiating the benefit of leveraging pretrained multimodal representations.
A key finding is that audio-alone conditioning suffices for dereverberation—adding vision to conditioning does not yield further measurable improvements in dereverberation metrics, indicating that late reverberation is principally governed by acoustic temporal evidence.
Room Impulse Response Estimation
For RIR estimation, audio-only conditioning yields lower error for late reverberation measures (e.g., ΔRT60), while audio+vision conditioning reduces errors associated with early energy (e.g., ΔDRR). Finetuning from the pretrained model yields lower overall errors across RT60, DRR, and EDT compared to training from scratch, suggesting that multimodal pretrained features form a superior initialization for physically grounded room acoustic modeling.
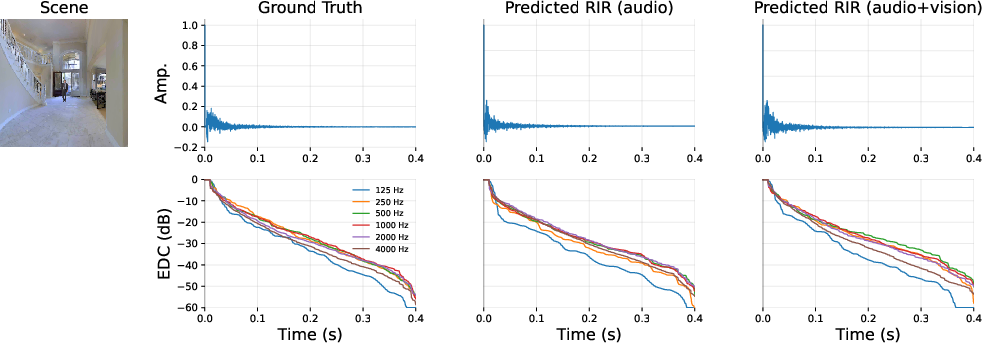
Figure 3: RIR waveform and energy decay curve examples illustrate the correspondence between input, estimated, and ground truth RIRs under varying conditioning regimes.
Interpretation and Theoretical Implications
Analytical results substantiate the hypothesis that visual conditioning acts as an effective structural prior for early reflections and direct-path characteristics, congruent with properties tied to room geometry, source-receiver spatial relationships, and visible materials. In contrast, modeling late reverberation is largely determined by observable acoustic evidence due to its intricate temporal dependencies, and is less affected by visual cues.
Another central claim that emerges is that pretrained multimodal V2A representations inherently encode correlations between visual scene features and room acoustics, enabling the transfer of physically salient priors between tasks and domains.
These findings clarify the limits and scope of multimodal learning in physical-acoustic tasks: vision augments acoustic modeling where geometric and material cues are critical, but does not substitute for temporal acoustic observation in aspects governed by room decay profiles.
Practical Impact and Future Prospects
The proposed framework's ability to repurpose foundation models for physical acoustic tasks with minimal additional training has direct implications for scalable deployment in downstream multimedia applications, including speech enhancement in video conferencing, immersive AR/VR environments, and computational audio analysis in robotics and scene understanding.
Limitations of the current formulation include the absence of explicit geometric, depth, or material attribute modeling—visual information is utilized solely through RGB images and backbone representations, not via structured scene annotations. Furthermore, the dataset's lack of explicit sound source-receiver spatial labels constrains the fidelity of physically grounded inference.
Future research directions include:
- Integration of explicit geometric/material priors via lightweight adapters or additional input channels.
- Construction or curation of datasets with richer source-receiver annotations for disentangling scene attributes.
- Expansion to more diverse physical environments, leveraging transformers or other foundation architectures for audio-visual spatial reasoning.
Conclusion
MMAudioReverbs exemplifies a unified approach to room-acoustic estimation by leveraging multimodal visual-audio foundation models. Experimental evidence highlights the complementary role of visual cues in modeling early energy components of the room response, and the preeminence of pretrained multimodal representations for initializing physically grounded audio tasks. While full disentanglement of spatial and acoustic priors remains an open challenge, this work establishes the efficacy and limitations of repurposing large V2A models for explicit physical scene analysis in audio domains.

