- The paper introduces a novel neuro-symbolic model that integrates VQ-VAE tokenization with structure-aware diffusion to enhance molecular graph generation.
- It replaces traditional one-hot encodings with discrete latent codes, enabling precise modeling of chemical contexts and reducing hash collisions inherent in fingerprint methods.
- Empirical results on QM9 and ZINC250k benchmarks demonstrate significantly improved validity, uniqueness, and structural fidelity, offering promising advances for drug discovery and materials science.
Vector Quantized Structure-Aware Diffusion for Molecule Generation: An Expert Overview
Motivation and Background
Diffusion models have become a cornerstone for molecular graph generation, but prevalent approaches often reduce atom and bond types to simple categorical encodings (e.g., one-hot), thus neglecting the rich symbolic chemistry present in real molecular graphs. This oversight impedes the accurate modeling of functional groups, local chemical contexts, and structural motifs, which hinders both the diversity and validity of generated molecules. Historically, Morgan fingerprints (ECFP), a popular paradigm for symbolic graph representation, suffer from irreducible hash collisions and lack invertibility, further limiting expressiveness.
VQ-SAD ("Vector Quantized Structure-Aware Diffusion") establishes a neuro-symbolic model architecture that directly models discrete latent codes for atoms and bonds via VQ-VAE, incorporating both symbolic and structural neural information into the forward and reverse diffusion trajectories. The approach systematically addresses data imbalance and state clashing by encoding structural context, thereby enhancing the denoising and generation fidelity, as quantified in key benchmarks.
Symbolic Structural Encoding and Neuro-Symbolic Paradigm
The core methodological innovation in VQ-SAD is the discrete tokenization of atom and bond types using VQ-VAE, where latent codes are learned for recurring substructures and chemical contexts. These codes effectively distinguish contextually different atoms (e.g., carbons linked to oxygen versus sulfur), a distinction not possible in one-hot or fingerprint-based encoding.
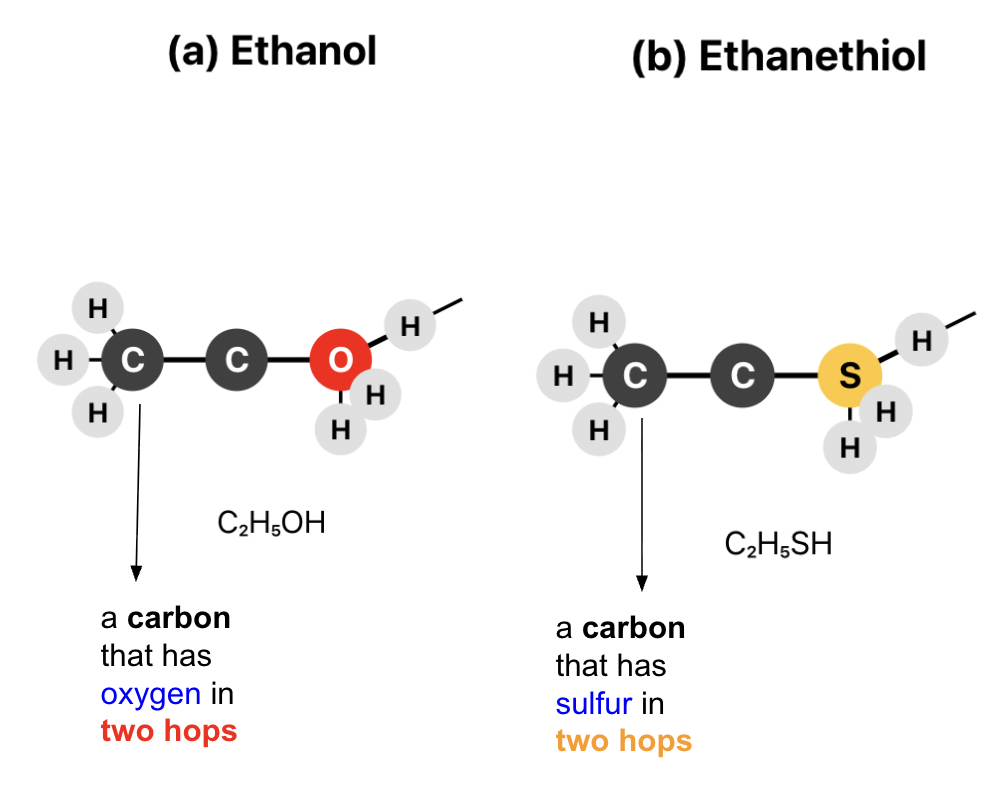
Figure 1: Symbolic encoding distinguishes carbons separated by different functional groups via multi-hop context.
This symbolic tokenization is performed in a pretraining step, resulting in frozen codebooks for both atoms and bonds. Subsequently, the diffusion process operates in the space of these learned discrete codes, allowing symbolic context to inform noise scheduling and denoising in a structure-aware manner.
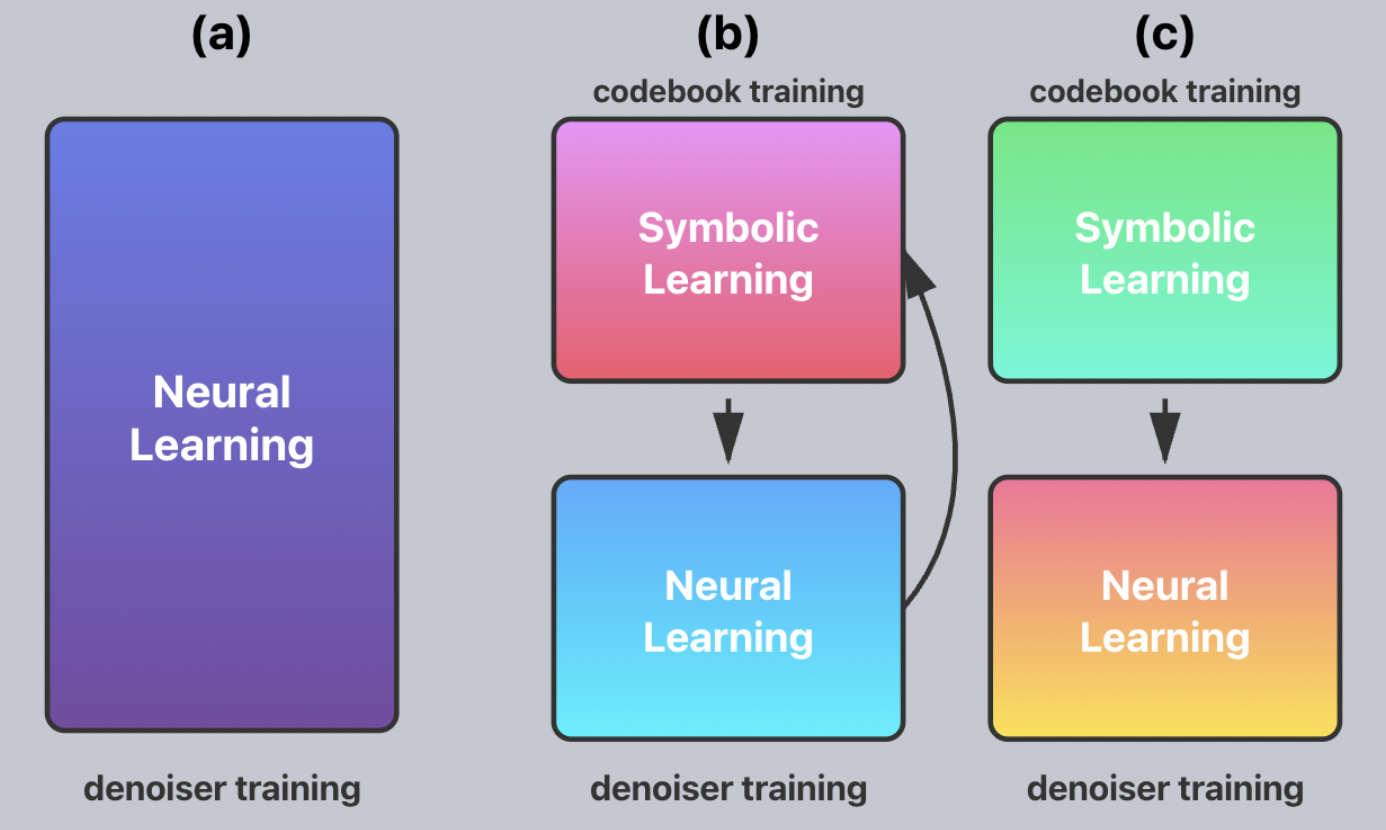
Figure 2: VQ-SAD utilizes a frozen tokenizer to inject symbolic codes, which contrasts unstable joint training and conventional denoising without symbolic information.
Framework Design and Methodological Details
VQ-SAD builds upon a structure-aware diffusion (SAD) baseline that integrates structural embedding with adaptive noise scheduling. The SAD baseline uses relative random walk probabilities (RRWP) to parameterize node and edge embeddings, offering richer structural context compared to simple graph features like degree. The noise schedule for both nodes and edges is dynamically computed using RRWP-based embeddings, preventing state collapse and clashing in diffusion trajectories.
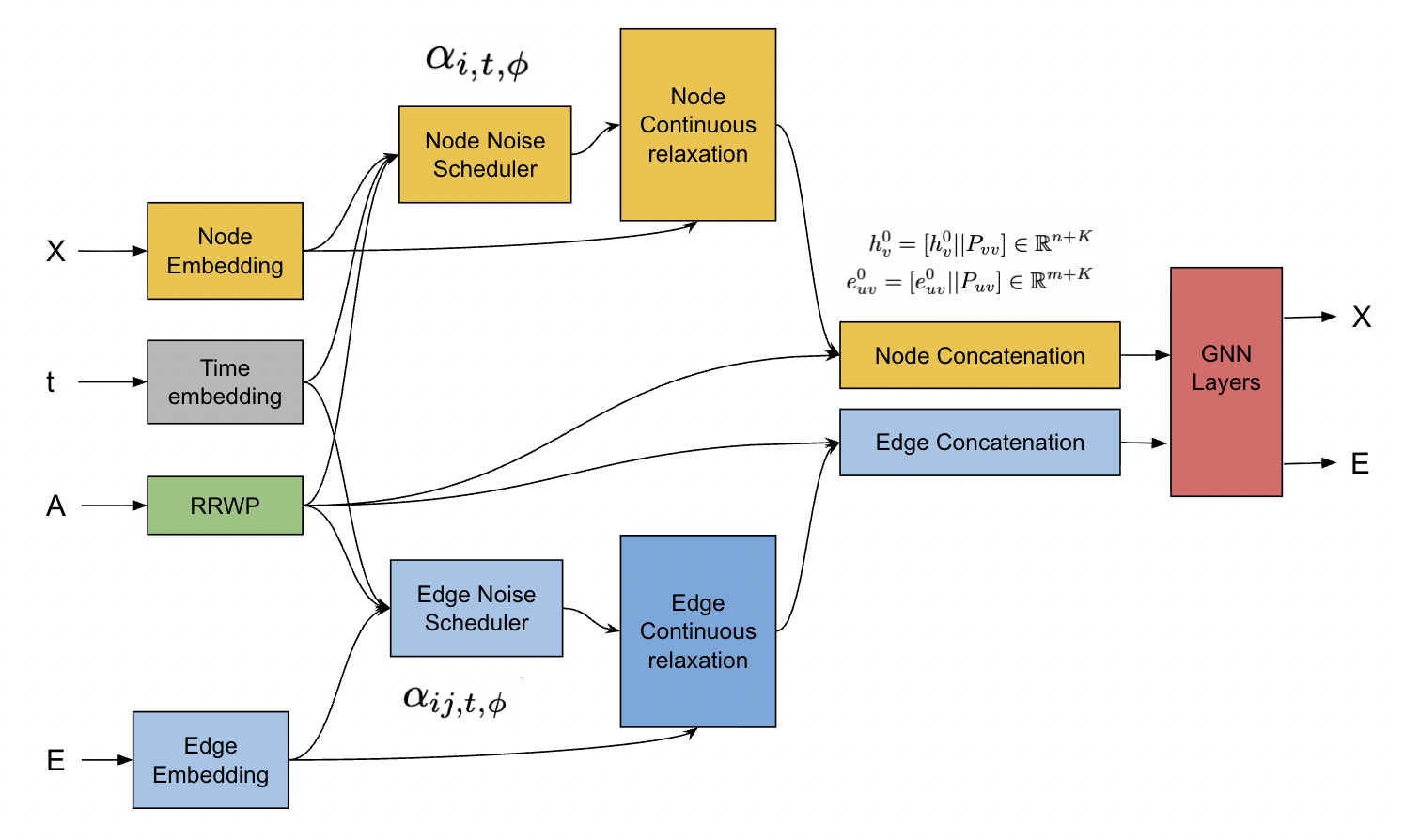
Figure 3: SAD framework: structural features guide adaptive noise scheduling in the diffusion process.
VQ-SAD extends SAD by replacing one-hot atom/bond features with discrete codes from the VQ-VAE tokenizer, and by introducing a mask-and-replace transition matrix with learnable replacement probability γ, further correcting for noisy unmasking. The generation pipeline consists of pretraining the VQ-VAE tokenizer, converting molecules into discrete code-space, and conducting diffusion in the latent code space before decoding to original atom/bond types.
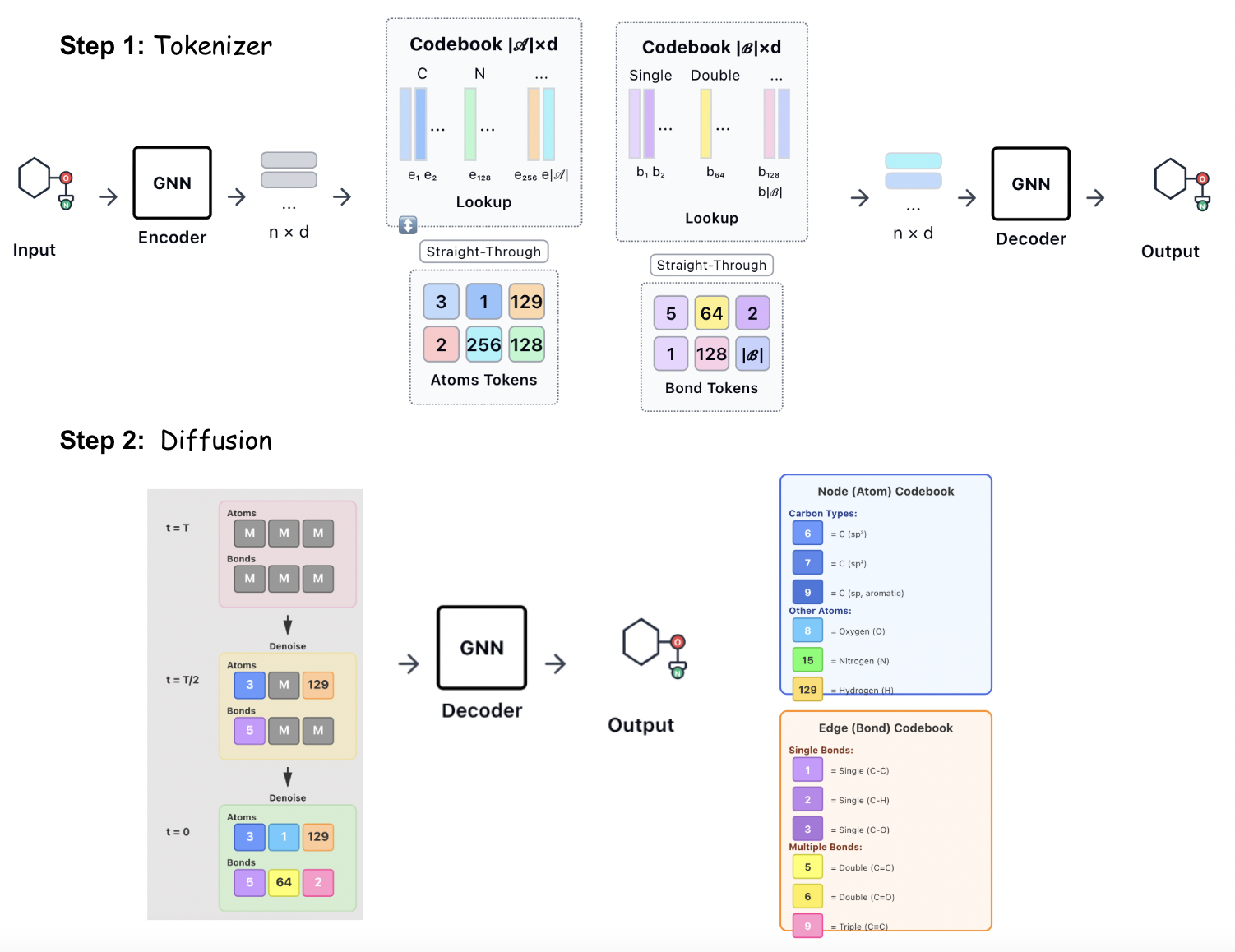
Figure 4: VQ-SAD training pipeline: VQ-VAE tokenization followed by diffusion-based graph generation and decoding.
VQ-SAD demonstrates strong empirical performance across both small-molecule (QM9) and drug-like (ZINC250k) benchmarks. The model consistently achieves higher validity (97.31% QM9, 93.84% ZINC250k) and uniqueness (98.51% QM9, 94.73% ZINC250k) in unconditional generation, outperforming strong baselines such as DiGress and MELD. Fréchet ChemNet Distance (FCD) and NSPDK kernel metrics further indicate improved distributional similarity and structural fidelity.
Notably, VQ-SAD substantially lowers the collision rate in latent representation, addressing a documented limitation in fingerprint-based and standard categorical diffusion models, and yielding a more balanced atom/bond distribution in generated molecules.
Generated molecules with and without structural information illustrate the qualitative improvement:
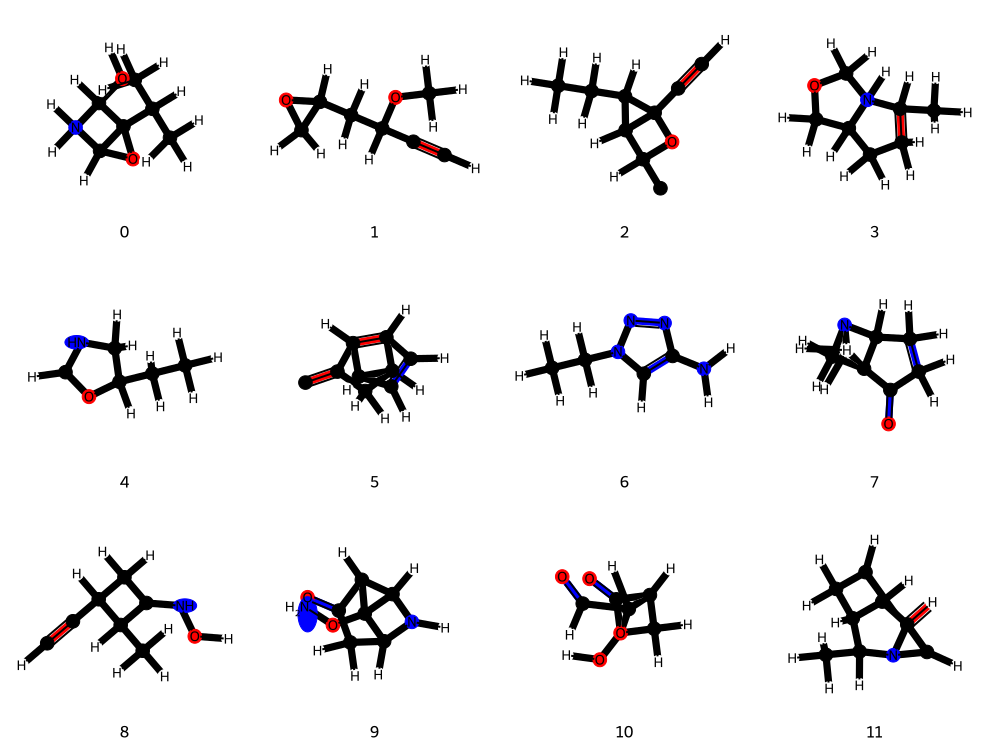
Figure 5: QM9 molecules generated without leveraging structural information.
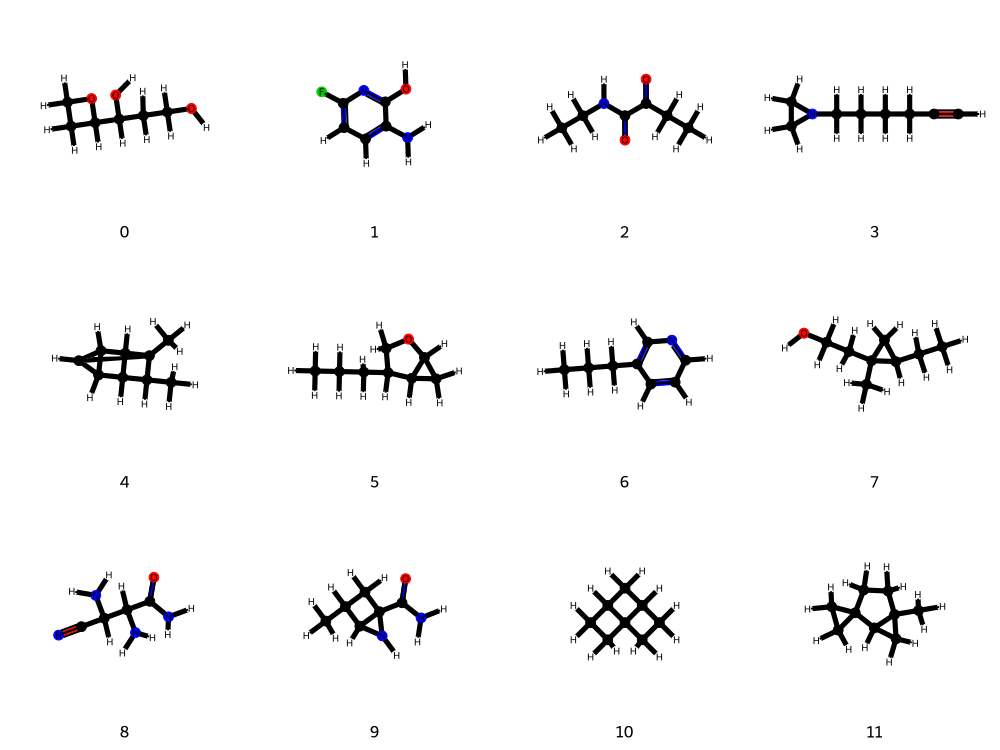
Figure 6: QM9 molecules generated using explicit structural information, resulting in higher validity and diversity.
Similar improvements are observed in large, chemically diverse drug-like molecules from ZINC250k.
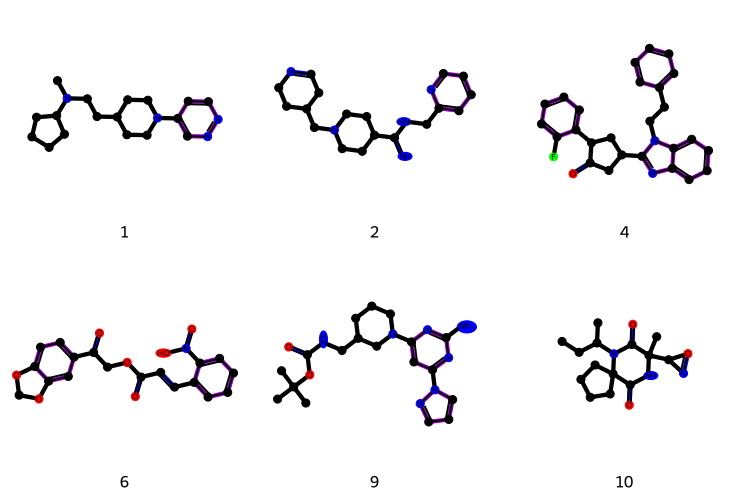
Figure 7: ZINC250k molecules generated without structural information—showing lower validity.
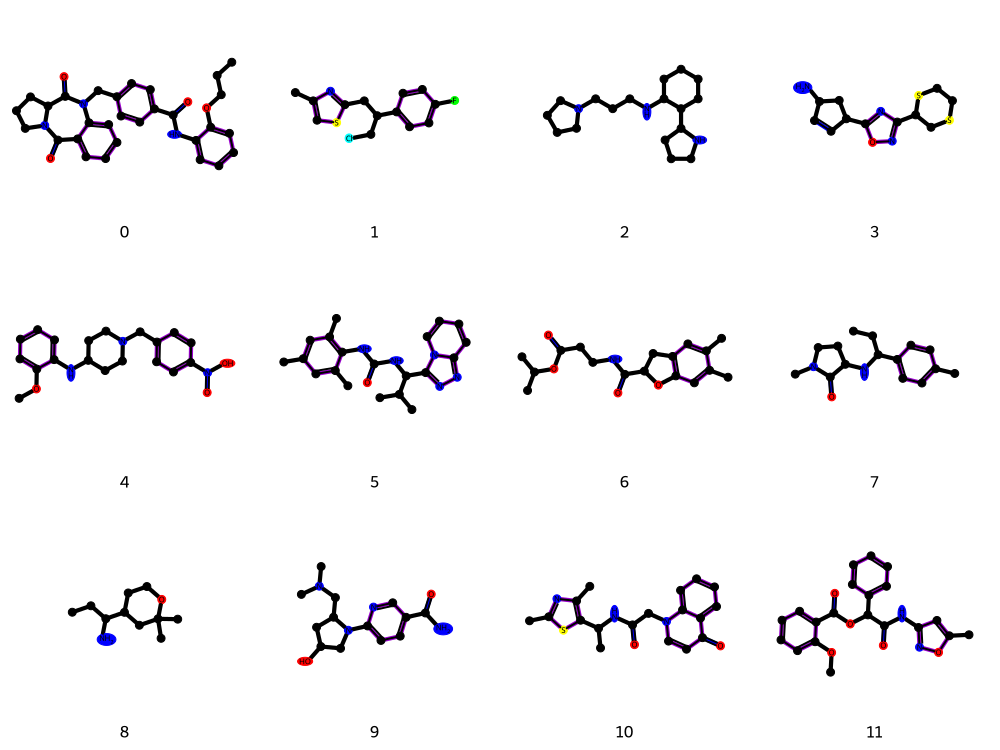
Figure 8: ZINC250k molecules generated using structural information—higher structural fidelity and diversity observed.
The model also performs well in conditional generation for properties such as heat capacity and dipole moment, though a trade-off is observed between property alignment and diversity, manifesting as mode collapse for narrowly conditioned targets.
Theoretical and Practical Implications
VQ-SAD bridges categorical graph modeling and symbolic chemistry, advancing neuro-symbolic representation learning for discrete molecular data. By introducing learned tokenizers and structurally adaptive diffusion schedules, the method achieves both higher quality in chemical validity and greater diversity, overcoming state-clashing and imbalanced class problems prevalent in molecular datasets.
Practically, this approach enables robust molecular scaffolding for drug discovery, protein engineering, and materials science, where structural context and symbolic chemistry are essential for functional generation. Furthermore, the methodology can be generalized to other domains of discrete graph generation—such as protein folding, crystal structure design, and synthetic pathway prediction—where symbolic substructure and neural context must be harmoniously integrated.
Theoretically, VQ-SAD’s mixture of symbolic and neural latent spaces with adaptive Markov kernels may inform new lines of research in permutation-invariant diffusion, robust discrete graph modeling, and neuro-symbolic generative models.
Future Directions
Potential advancements include end-to-end joint learning for tokenizer and denoiser with stabilized gradients, exploring hierarchical tokenization for multi-level graph motifs, and applying the framework to larger-scale molecular datasets or other atomistic simulation domains. Introduction of additional structural priors (e.g., geometric constraints, quantum embeddings) could further refine both property alignment and diversity. Moreover, integrating classifier-free guidance for conditional generation may alleviate mode collapse and sharpen property-targeted outputs.
Conclusion
VQ-SAD introduces a neuro-symbolic generative model that leverages discrete VQ-VAE tokenization and structure-aware diffusion for molecular graph generation. The approach addresses key limitations in prior techniques by integrating symbolic chemical context and adaptive noise scheduling, yielding strong empirical improvements in both unconditional and conditional generation tasks. The framework sets a precedent for future research in neuro-symbolic graph generation, with broad implications for AI-driven molecular discovery and combinatorial optimization (2605.00354).