- The paper introduces a unified BEV-based framework that fuses semantic reasoning and geometric prediction, outperforming specialist models in autonomous driving benchmarks.
- It leverages LLM-enhanced world queries and joint geometric optimization to ensure spatial consistency and semantic interpretability in future scene predictions.
- Empirical results show a 41.6% Chamfer Distance reduction and improvements in CIDEr, METEOR, and ROUGE-L scores, validating its effectiveness.
Unified Driving World Modeling with HERMES++
Motivation and Problem Analysis
Current driving world models for autonomous systems exhibit a research dichotomy: generative models excel at forecasting scene evolution but lack semantic interpretability, while large vision-LLMs (VLMs/LLMs) provide semantic reasoning but lack predictive geometric fidelity. This structural gap impedes the deployment of holistic, interpretable autonomous driving agents, particularly for safety-critical applications that demand both deep understanding and future anticipation of complex, dynamic scenes.
The HERMES++ framework addresses this by unifying 3D scene understanding and future geometry prediction into a single model. The approach leverages the Bird’s-Eye View (BEV) representation to consolidate high-dimensional multi-view perceptual information into a spatial format amenable to LLM processing, introducing components for semantic-geometric fusion and robust geometric consistency enforcement.
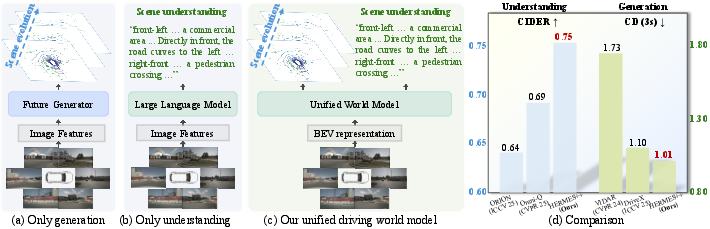
Figure 1: Problem landscape and comparative results. HERMES++ achieves superior unification of scene generation and understanding via BEV, outperforming both prior generative and specialist architectures.
Architectural Overview
HERMES++ consists of several tightly integrated modules:
- Visual Tokenizer: Utilizes a convolutional backbone (OpenCLIP ConvNeXt-L) to encode multi-view images, projecting features into a compact BEV grid. Downsampling and flattening produce token sequences suitable for LLM interfacing without loss of critical spatial semantics or excessive token count.
- LLM-Enhanced World Queries: These are contextually anchored queries, initialized from BEV tokens and temporally modulated via ego-motion embeddings. The design enables cross-attention with language instructions, facilitating the injection of semantic priors into geometric evolution.
- Current-to-Future Link: A stack of transformer blocks conditions future BEV features on both LLM-processed instructions and world queries. Textual Injection and Ego Modulation mechanisms allow the future scene prediction to be steered by both language and planned agent trajectory.
- Differentiable BEV-to-Point Render: Generates future point cloud reconstructions from BEV features using volumetric upsampling and neural SDF modeling, allowing end-to-end differentiability for geometric supervision.
- Joint Geometric Optimization: Combines explicit rendering Loss with implicit alignment (cosine and Gram matrix) to a frozen, geometry-aware latent feature prior from a pre-trained 3D encoder, enforcing both local and global structural integrity of predicted scenes.
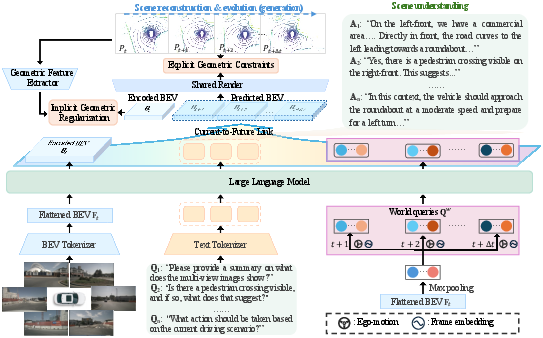
Figure 2: HERMES++ pipeline. Multi-view BEV tokenization, language fusion, temporally-bridged geometric evolution, and joint geometric supervision are integrated for unified understanding and generation.
Numerical Results
HERMES++ demonstrates consistently strong quantitative results across both prediction and understanding benchmarks:
- 3-Second Point Cloud Prediction: Achieves a Chamfer Distance (CD) reduction of 41.6% over ViDAR and outperforms DriveX with only single-frame inputs.
- 3D Scene Understanding: Shows a CIDEr gain of 9.2% over the specialist Omni-Q on OmniDrive-nuScenes, despite requiring no auxiliary detection/lane supervision, and maintains competitive METEOR and ROUGE-L scores.
- Unified Performance: Model scaling from 1.8B to 3.8B parameters yields further improvements, and the architecture generalizes robustly across LLM backbones (InternVL2, Llama-3.2, Qwen3), confirming its architectural universality.
Additional ablations validate design choices, showing:
- BEV tokenization drastically outperforms naïve multi-view flattening for future scene generation due to preserved geometric structure.
- The proposed Joint Geometric Optimization regime reduces CD by over 12% relative to explicit constraints alone and produces features that are geometrically faithful and artifact-free.

Figure 3: Qualitative results. HERMES++ delivers fine-grained semantic recognition (e.g., signage text, object identification) while rigorously tracking physical scene geometry in future predictions.
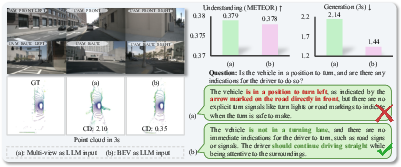
Figure 4: Comparison of BEV-based and multi-view-based input. Only BEV input maintains structural coherence in predicted geometry; flattened multi-view inputs lead to collapse artifacts.
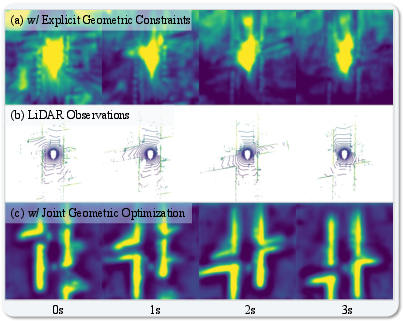
Figure 5: Internal representations. Joint geometric optimization yields compact, geometry-conformant features (c) compared to explicit-only supervision (a, showing camera projection biases).
Theoretical Implications and Practical Significance
HERMES++ addresses fundamental limitations of isolated world modeling and scene understanding by establishing explicit semantically-conditioned spatiotemporal bridges within a shared BEV substrate, enabling bidirectional cross-task supervision. Importantly:
- The world query mechanism provides a high-throughput channel for semantic information transfer into geometric prediction, which is essential for interpretable forecasting and safe planning.
- Joint geometric optimization ensures that learned representations are not only semantically meaningful but also physically plausible and spatially consistent, closing the gap between simulation and real-world reliability.
- Advancement to multi-modal, multi-task unified modeling establishes a scalable research direction for foundational world models capable of supporting flexible downstream agent behaviors, planning, and interaction.
Future Directions
Several open research avenues remain:
- Further leveraging multi-modal large model priors (e.g., video-language pretraining) for BEV-based input remains unresolved.
- Extension of the unified modeling framework to broader modalities (LiDAR, radar, event cameras) and action spaces (planning/control) is plausible.
- Near-term work may involve efficient adaptation of HERMES++ for real-time interactive inference and active exploration settings.
Conclusion
HERMES++ substantiates the feasibility and advantages of a unified architecture for 3D scene understanding and future geometry prediction in autonomous driving scenarios. By combining compressed geometric representations, deep language-model reasoning, explicit semantic-to-geometric linkage, and robust geometric regularization, the framework sets a new benchmark for interpretable, predictive, and generalizable driving world models.
Key claims supported by the empirical results and ablation studies:
- Unified BEV-Language modeling achieves stronger joint performance than specialist baselines across both semantic and geometric tasks, even without detection/map supervision.
- Joint geometric optimization is critical for correct structural prediction; explicit-only approaches yield artifacts and inferior accuracy.
- Cross-task interaction (world queries, textual injection) is essential for bridging understanding and prediction in temporal progression.
The architectural design and results of HERMES++ are likely to inform a new generation of interpretable, predictive foundational models for autonomous vehicles and embodied agents—systems that must not only “see” and “describe,” but also accurately simulate and anticipate complex real-world scene evolutions.