- The paper introduces a doubly robust LP-DiD methodology to correct aggregation and selection biases in dynamic treatment effect estimation.
- It develops and compares regression adjustment, inverse probability weighting, and doubly robust estimators, demonstrating improved performance under various misspecification scenarios.
- The empirical application on no-fault divorce reforms and Monte Carlo simulations validates the method’s robustness and practical utility in policy evaluation.
Doubly Robust Local Projections Difference-in-Differences: Theory, Estimation, and Empirical Implications
Overview and Motivation
The paper "Doubly robust local projections difference-in-differences" (2604.27035) introduces a formal semiparametric framework for dynamic treatment effects estimation with staggered adoption using Local Projections Difference-in-Differences (LP-DiD). The theoretical and empirical components are integrated to address two major challenges: aggregation bias caused by irregular weighting across cohorts and horizons, and bias/inefficiency due to covariate-dependent selection and outcome dynamics. The paper develops and analyzes regression-adjustment (RA), inverse-probability weighting (IPW), and doubly robust (DR) estimators tailored for LP-DiD environments, providing identification, inference, and robustness diagnostics for event-study estimands.
The LP-DiD methodology is built upon absorbing binary treatment and explicit cohort structure. Treated units are indexed by their adoption cohort, and clean control stacks are constructed to ensure untreated comparison across each time window. The base-period operator formalizes the pre-treatment comparison for each entry date, allowing for flexible normalizations.
The horizon-specific local target is formulated as:
$\theta_h^{(b)} =
E\left[\Delta_{it}^{(b)}(h;1)-\Delta_{it}^{(b)}(h;0)\mid D_{it}=1,\ (i,t)\inS_h^{(b)}\right],$
where Δit(b)(h;d) compare outcomes under treatment d∈{0,1}. Under a no-anticipation assumption and appropriate weighting, this mapping recovers standard cohort-time ATT estimands.
A major contribution is the explicit analysis of aggregation rules. The benchmark LP-DiD variance-weighted regression does not generally recover the treated-entry-weighted ATT target. The re-weighting scheme of Dube et al. (2025) eliminates the bias by directly weighting by cohort size, achieving:
θh=∑g:Gg<∞Ng∑g:Gg<∞NgATT(g,g+h).
Semiparametric Identification and Estimation
Identification is defined horizon-by-horizon, relaxing homogeneous parallel trends to allow covariate-dependent selection and dynamic outcome evolution. Clean controls are constructed via local stacks, and nuisance adjustment is specified via predetermined covariates Xit.
Regression Adjustment (RA)
RA representation leverages untreated-outcome regression, yielding:
θh=E[Dit]E[Dit{Δit(h)−m0h(Xit,t)}],
where m0h(Xit,t) captures counterfactual untreated dynamics.
Inverse Probability Weighting (IPW) and IPT
IPW utilizes odds weights derived from the propensity score, with IPT implemented for nuisance estimation:
θh=E[Dit]E[DitΔit(h)]−E[(1−Dit)ωh(Xit,t)]E[(1−Dit)ωh(Xit,t)Δit(h)].
IPT adapts the estimator for first-order robustness to misspecification.
Doubly Robust (DR) Estimation
The DR estimator achieves identification if either the untreated-outcome regression or the propensity score is correctly specified. The DR representation is:
θhDR=E[Dit]E[Dit{Δit(h)−m0h(Xit,t)}]−E[(1−Dit)ωh(Xit,t)]E[(1−Dit)ωh(Xit,t){Δit(h)−m0h(Xit,t)}].
This formulation mirrors the structure of doubly robust DiD estimators in Sant’Anna and Zhao (2020), but localizes it to LP-DiD with horizon-specific clean-control stacks.
Influence-Function Inference
The asymptotic linear representation, using cluster-level moments and influence functions, enables analytic and bootstrap-based inference robust to within-cluster correlation. Simultaneous confidence bands over event-study paths are constructed via multiplier bootstrap, facilitating rigorous inference across dynamic horizons.
Numerical Evaluation: Monte Carlo Evidence
Monte Carlo simulations are implemented using staggered-adoption panel designs with heterogeneous treatment effects and covariate-driven dynamics. Four scenarios are considered: both nuisances aligned, untreated outcome regression misspecified, propensity score misspecified, and both misspecified. Strong numerical results are observed:
- Unadjusted LP-DiD RW estimators exhibit substantial bias and undercoverage.
- Covariate-adjusted estimators (RW + X, RA) and DR estimators achieve robust unbiasedness and coverage under alignment.
- DRLPDID maintains near-nominal coverage with minimal bias under correct specification, outperforming baseline LP-DiD estimators even under moderate misspecification.
- IPT-only DR estimators (DRLPDID-IPT) are more sensitive to misspecification, with empirical bias patterns reflecting estimand gaps rather than variance deficiencies.
- Sensitivity exercises perturbing local parallel trends reveal that when the parallel-trends assumption is violated, the bias and coverage deteriorate across all semiparametric estimators, underscoring the necessity of assumption diagnostics.
Empirical Application: No-Fault-Divorce Event Study
A canonical application is presented using U.S. state-level panel data studying the effects of no-fault-divorce reforms on female suicide mortality rates. Empirical results span the main and richer covariate specifications.
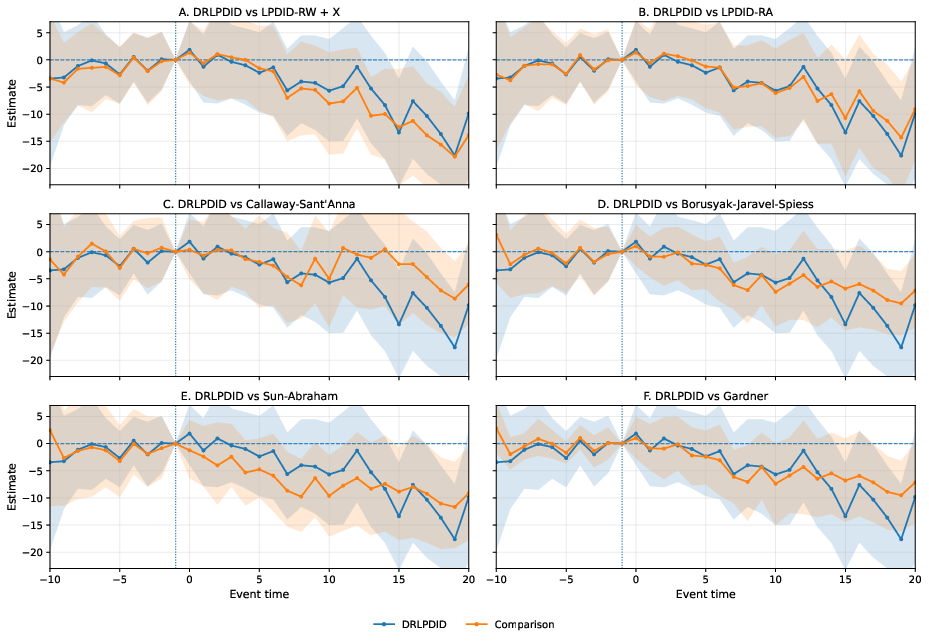
Figure 1: Event-study comparison in the no-fault-divorce application: richer specification.
Across multiple estimator families (DRLPDID, LPDID-RW + X, LPDID-RA, Callaway--Sant'Anna, Borusyak--Jaravel--Spiess, Sun--Abraham, Gardner), DRLPDID and BJS/Gardner yield ATT values close to −5.62 and Δit(b)(h;d)0, respectively, with Sun--Abraham and LPDID-RW + X more negative (Δit(b)(h;d)1, Δit(b)(h;d)2). The richer covariate specification confirms robustness of DRLPDID and regression-adjusted estimators, while IPT-only variants remain more negative, reinforcing Monte Carlo insights regarding sensitivity.
Implications and Future Directions
The doubly robust LP-DiD framework formalizes identification and estimation for dynamic staggered-adoption panels, enhancing robustness to covariate-dependent selection, heterogeneous dynamics, and misaggregation. The explicit mapping between aggregation rules and ATT targets allows researchers to diagnose and correct bias, while cluster-robust inference protects against correlated shocks.
Practically, these methods expand the toolkit for event-study analyses, especially in policy evaluation, labor markets, and epidemiology, where covariate adjustment and dynamic treatment response are critical. Theoretically, the doubly robust design offers a template for semiparametric estimation in panel settings with complex treatment assignment and post-treatment heterogeneity.
Future research may extend LP-DiD and DR approaches to continuous treatments, more general forms of selection, or utilize higher-order robustness in inference. The integration with flexible ML nuisance estimation (e.g., via neural nets or ensemble methods) and application to high-frequency panels (with network or spatial links) represents promising directions for the empirical implementation of causal inference.
Conclusion
"Doubly robust local projections difference-in-differences" (2604.27035) establishes rigorous identification, estimation, and inference under staggered adoption with dynamic effects. The proposed semiparametric estimators—especially DRLPDID—demonstrate strong numerical performance and robustness in both simulations and empirical settings. The methodological advances are immediately relevant for applied researchers, offering analytically precise, bias-corrected, and inference-valid techniques for event-study analysis and causal estimation in panels.

