- The paper presents a framework that replaces traditional PAC bounds with per-distribution universal rates for posted-price revenue maximization.
- It demonstrates that when the optimal revenue is attained, learning rates reach a near-optimal Ω(1/√n) barrier, while bounded or discrete supports enable faster convergence.
- The study shows that standard ERM may fail for unbounded discrete supports, prompting bias-corrected approaches that achieve nearly exponential convergence.
Detailed Analysis of "On the Learning Curves of Revenue Maximization" (2604.26922)
Introduction and Motivation
Traditional PAC-style analysis of statistical learning theory provides uniform, distribution-free sample complexity guarantees, particularly influential in auction and mechanism design—especially since the work of Cole and Roughgarden. However, these bounds characterize the worst-case or upper envelope of learning curves, potentially missing the finer structure for individual distributions. This paper presents a systematic investigation of revenue maximization learning curves for individual distributions, with a focus on single-item, single-buyer posted-price mechanisms. The framework replaces classical PAC-style minimax analysis with universal rates, quantifying convergence rates for each fixed distribution and highlighting strong distinctions between distributional regimes.
Learning Curve Framework: Universal vs. PAC Rates
Let $\epsilon_n(t_n, \mathcal{D}) = \opt_{\mathcal{D}} - \mathbb{E}[\rev_\mathcal{D}(t_n)]$ denote the expected revenue gap after n samples, where tn is the algorithm's pricing rule and $\opt_{\mathcal{D}}$ the optimal posted-price revenue. While PAC bounds study supDϵn(tn,D) (uniform upper envelope), the introduced framework studies the behavior of ϵn(tn,D) for each fixed D, revealing richer structural rates and possibilities for much faster generalization.
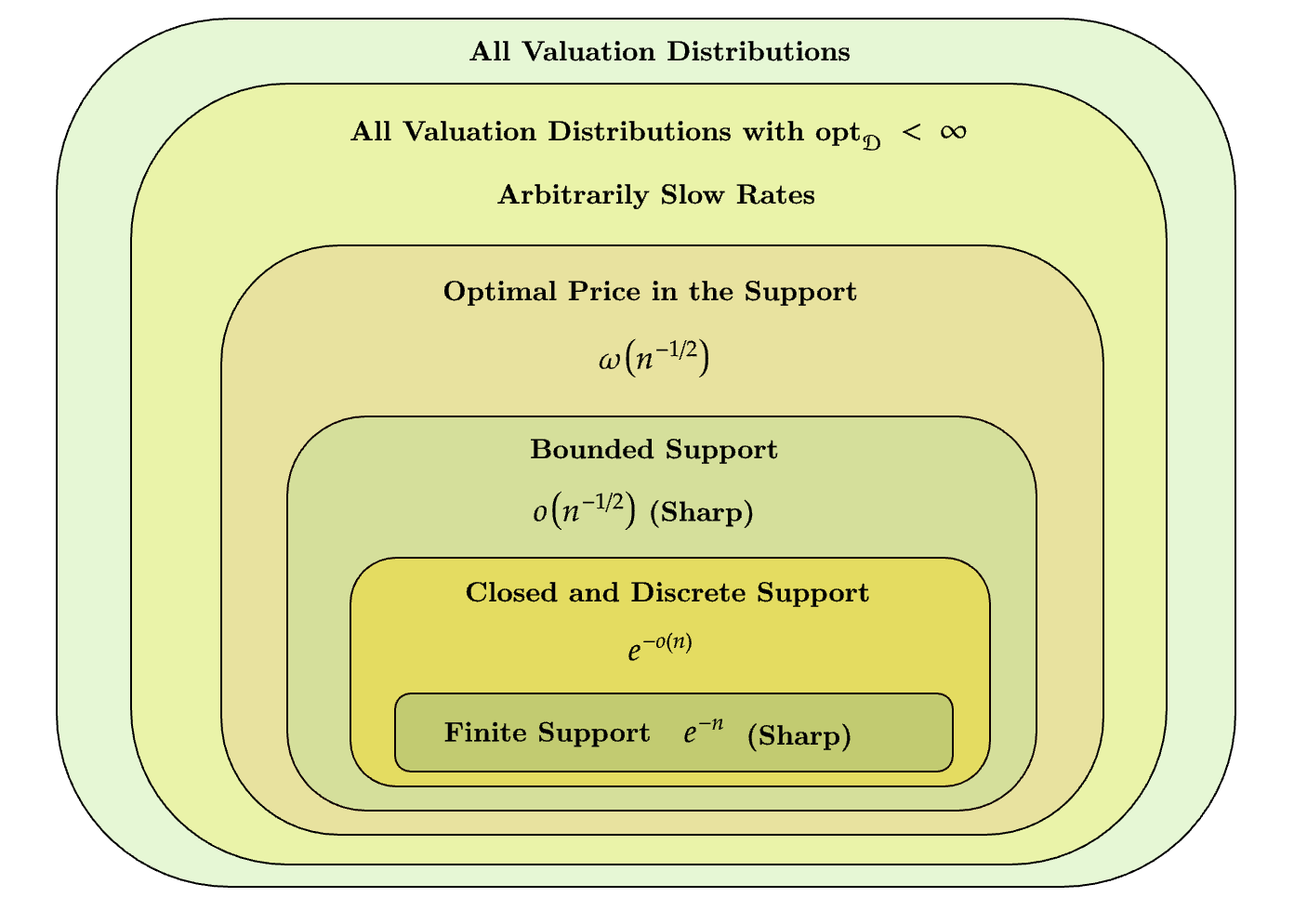
Figure 2: Universal (red) and PAC (blue) learning curves, contrasting individual distribution decay versus worst-case envelope.
The key technical distinction is that, for universal lower bounds, the construction must find a single hard distribution yielding a slow rate across all sample sizes, as opposed to the PAC case, where a sequence of hard distributions indexed by n suffices.
Main Theoretical Contributions
The paper fully characterizes universal learning curve rates for posted-price revenue maximization in the single-buyer single-item regime.
Existence of Bayes-Consistent Algorithms
There always exists a Bayes-consistent learner: for any valuation distribution (including those with infinite optimal revenue), the learning curve can be forced to converge (possibly arbitrarily slowly) to zero. The construction is a variant of truncated ERM, maximizing empirical revenue over a growing finite grid as n→∞, guaranteeing asymptotic convergence [Theorem 1].
Arbitrarily Slow Rates for Infinite-Supremum Distributions
For the broad class where the optimal revenue $\opt_\mathcal{D}$ is finite—but not necessarily attained by any price—the paper proves impossibility of nontrivial learning rates: for any proposed rate function n0, there exists n1 and algorithm n2 such that the error n3 is at least n4 for infinitely many n5 [Theorem 2]. The hard instance involves a carefully crafted discrete distribution with mass "escaping" to infinity, evading tight approximation at any rate.
Near-Optimal n6 for Attainable Optima
If n7 is attained at a finite price, then the minimax lower bound of arbitrarily slow rates disappears, and the optimal universal rate improves to n8. Specifically: for any n9 (i.e., diverging faster), there is a learner achieving it, but for tn0, this is impossible—formalizing a nearly-tight tn1 barrier [Theorem 3]. The corresponding learner uses capped ERM over a growing grid.
Faster Rates for Bounded and Discrete Supports
Dramatically different behavior emerges under more constrained valuation supports:
- For bounded support, the universal rate is tn2, strictly improving over the tn3 threshold.
- For closed and discrete supports, the algorithm achieves "almost exponential" convergence rates tn4; for truly finite supports, exponential tail rates tn5 (for distribution-dependent tn6) are attainable [Theorem 4].
Sharp lower bounds for each regime demonstrate tightness of these separation lines (modulo technical slack for "almost exponential" rates).
Figure 1: Summary of universal learning rates for revenue maximization in the single-item single-buyer setting.
ERM Can Fail Consistency for Discrete/Unbounded Supports
For closed and discrete but unbounded supports, standard empirical revenue maximization (ERM) need not even be Bayes-consistent: there are distributions where ERM's revenue never converges to the optimum; in contrast, a bias-corrected structural-ERM variant attains nearly exponential rates. This construction distinguishes universal learning from PAC and other classical frameworks.
Technical Overview
Lower Bound Arguments
The lower bounds employ a combination of algorithm-dependent, adversarial constructions and infinite, tree-indexed ensembles of hard distributions. Notably, the proof for the tn7 barrier in the bounded support setting hinges on an iteratively defined binary tree of support points, with the learning curve bottleneck anchored to the inherent difficulty of distinguishing coin biases in a shrinking interval—a nontrivial extension of minimax lower bounding to the universal setting (no adversarial adaption per tn8 possible).
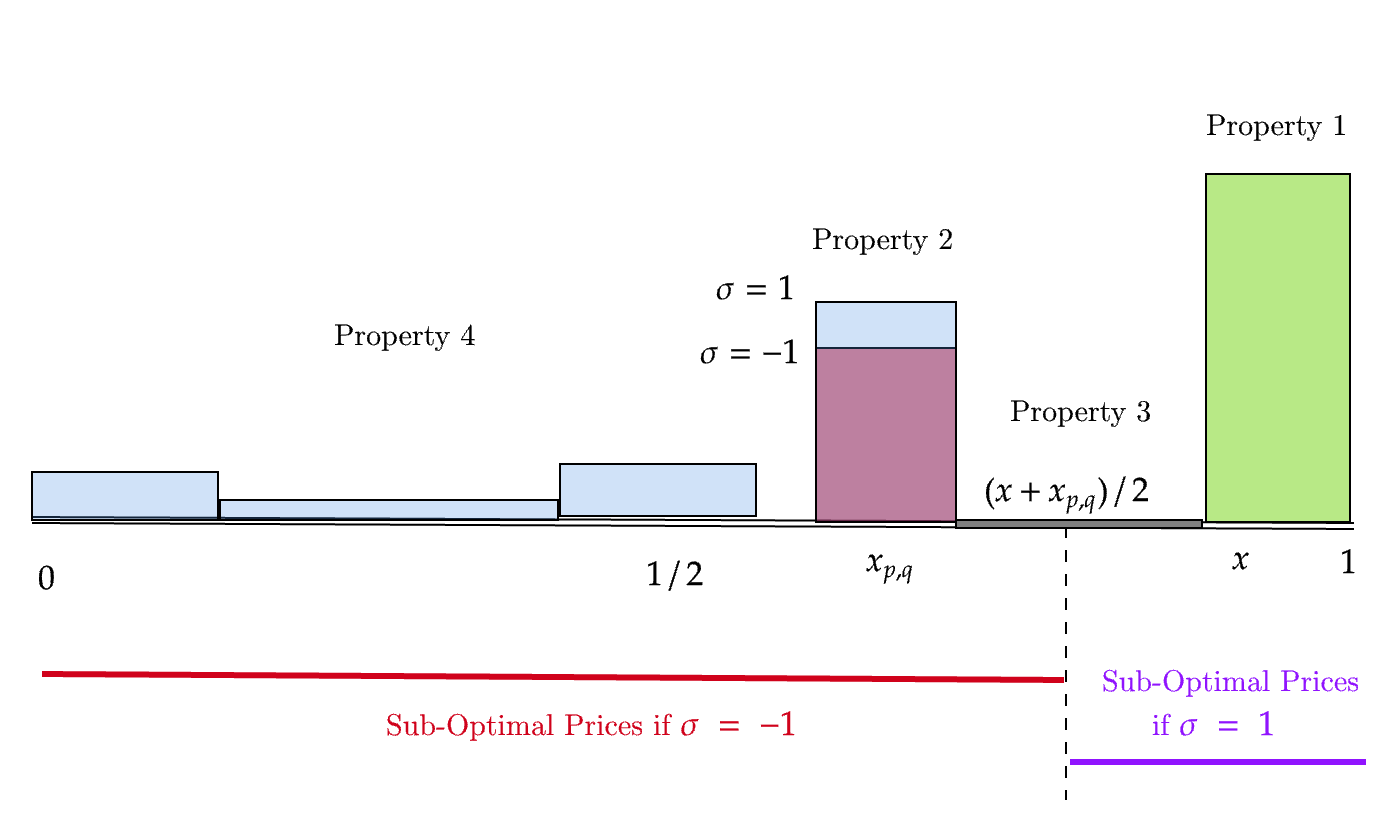
Figure 3: Illustration of a distribution tn9 constructed with mass distribution constraints to realize uniform minimax lower bounds.
Upper Bound Constructions
- The capped ERM algorithm, with thresholded support exploration, adapts rates to the growth of the explored interval, matching the $\opt_{\mathcal{D}}$0 barrier.
- For distributions with bounded or discrete support, lower mass on the tails and finite support allow for sharper concentration (Bernstein- and DKW-type) inequalities, supporting $\opt_{\mathcal{D}}$1 and exponential rate upper bounds even for vanilla ERM.
- For discrete but infinite supports, the algorithm requires structural risk minimization/biasing toward smaller prices to avoid suboptimality from rare, large, overfit prices.
Implications and Future Directions
Theoretical Significance
Universal rates analysis reveals that PAC-style lower bounds must conflate the difficulty from switching between hard distributions, rather than true adverse behavior for each fixed instance. Thus, for many real-world prior distribution settings, statistical learning algorithms can achieve much faster convergence than worst-case sample complexity bounds would suggest.
Moreover, the key structural property governing possible learning rates is whether $\opt_{\mathcal{D}}$2 is actually achieved at a support point ("attainability"), not merely the tail or regularity shape.
Practical Considerations
For practitioners, the results suggest: in digital auction systems with bounded or discrete pricing (e.g., cent increments), revenue-maximizing algorithms can be aggressively optimized for much faster sample efficiency than PAC bounds predict, especially if one has assurances about the likeliness of pricing optima being attained and the underlying tail behavior.
Limits and Open Problems
- Extension of these tight universal characterizations to multi-buyer or multi-item auction settings is immediate and nontrivial.
- For regular, monotone hazard rate, or other parametric classes, the gap between universal and PAC rates suggests revisiting all previous mechanism design learning theory in the universal rates framework.
- A full taxonomy of ERM's consistency and convergence guarantees, especially for composite distributions or in high-dimensional mechanism environments, remains open.
Conclusion
This work rigorously delineates the achievable rates for individual learning curves in revenue maximization, bringing new clarity to the interplay between distributional structure (boundedness, discreteness, attainability of optimum), algorithmic bias, and statistical difficulty. It establishes that the limiting factor for learning in revenue maximization is not the presence of hard instances in a worst-case sense, but rather the geometric and support properties of each specific distribution. These insights indicate promising directions for both the theory of universal learning and its applications in robust economic algorithm design.

