- The paper presents a novel method, Orthogonal Subspace Decomposition (OSD), to decouple task-specific and document-specific knowledge in parametric RAG frameworks.
- It introduces soft and hard orthogonalization techniques for training lightweight LoRA adapters, reducing parameter interference in multi-document assembly.
- Empirical evaluations across QA, fact-checking, and dialogue tasks show improved compositional robustness and stable performance under varying retrieval depths.
Decoupling Knowledge and Task Subspaces in Parametric Retrieval-Augmented Generation
Motivation and Context
The proliferation of Retrieval-Augmented Generation (RAG) frameworks has advanced the grounding of LLMs via external knowledge retrieval. Parametric RAG variants (PRAG) further escalate this paradigm by encoding retrieved documents into lightweight LoRA-adapter modules, which are dynamically loaded and composed at inference time. This allows knowledge to be injected directly into model weights, transcending context-window limitations inherent to in-context RAG methods.
However, conventional PRAG implementations typically train document adapters with task-supervised objectives, resulting in an entanglement between document-specific factual knowledge and generic task-solving behaviors. This confluence obstructs compositional robustness: merging multiple such adapters accumulates redundant task patterns, induces parameter interference, and impairs the reliability and scalability of multi-document parametric memory systems.
Orthogonal Subspace Decomposition: Methodological Framework
To address the composability bottleneck, this work introduces Orthogonal Subspace Decomposition (OSD). The central technical hypothesis is that explicit separation of task-general and document-specific subspaces during adapter training will both enhance downstream robustness and facilitate multi-adapter merging. The framework decomposes parameterized memory modules into:
- Task LoRA (Δθ_T): Encapsulates reusable task-specific reasoning, format, and inductive biases via corpus-level, task-oriented supervision.
- Knowledge LoRA (Δθ_K,i): Encodes document-level factual information, trained atop a frozen task component with additional orthogonalization constraints.
At inference, a query and task type trigger the retrieval and composition of relevant document-specific Knowledge LoRAs merged via a controlled aggregation (∑iαiΔWK,i), with a single Task LoRA applied, eliminating redundant task generalization in composed adapters.
Two instantiations are explored:
- Soft Orthogonalization: Adds Frobenius-norm regularization to penalize overlap between task and document LoRA down-projection directions, encouraging statistical separation without restricting parameter space.
- Hard Orthogonalization: Reparametrizes document LoRAs in the null-space of the task LoRA’s row-space via SVD-decomposition, enforcing structural orthogonality at the cost of reduced expressivity.
Empirical Evaluation and Numerical Results
The framework is evaluated across a spectrum of knowledge-intensive tasks: open-domain QA (2WikiMultihopQA, HotpotQA, ComplexWebQuestions, PopQA), fact-checking (FEVER), slot-filling (Zero Shot RE), knowledge-grounded dialogue (Wizard of Wikipedia), and biomedical verification (PubMedQA), using Llama-3.2-1B, 3B, and 8B-Instruct models. Document retrieval utilizes BM25, with retrieval depth K systematically varied between $1$ and $10$.
Performance metrics are task-adaptive (F1 for QA, slot-filling, dialogue; Accuracy for verification) and reported on 300-instance test sets per dataset.
Key findings:
- PRAG exhibits marked sensitivity and performance decay as K increases, evidencing parameter interference during multi-adapter composition.
- Both D-PRAG (soft) and D-PRAG-hard (hard) produce flatter performance curves, reflecting compositional stability and reduced degradation under increased document merging.
- The decoupled variants are not uniformly superior in all settings, but routinely demonstrate lower retrieval-depth sensitivity than standard PRAG baselines.
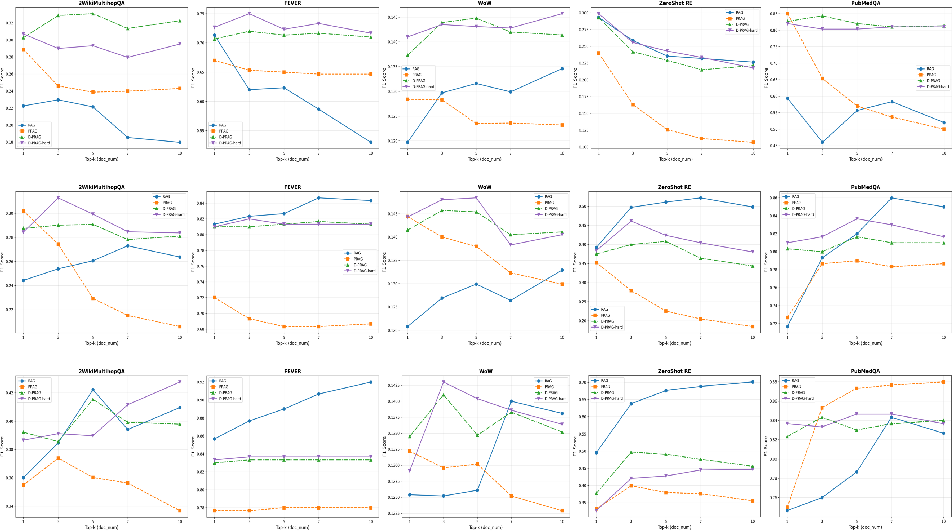
Figure 1: Performance comparison across different retrieval depths (K∈{1,3,5,7,10}), with D-PRAG variants exhibiting greater robustness than PRAG as adapter composition increases.
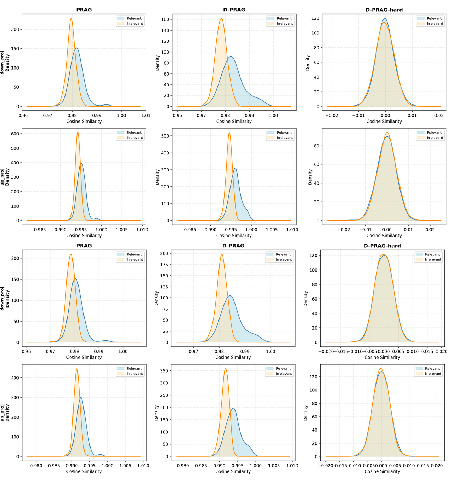
Representation Analysis
Cosine similarity analyses of flattened LoRA update parameters reveal crucial geometric distinctions:
Theoretical and Practical Implications
This work empirically substantiates the hypothesis that task-document disentanglement via orthogonalization facilitates scalable, robust parametric memory composition. Practically, this approach enables:
- Stable Aggregation: Systematic reduction of parameter interference, allowing external factual memory to scale with retrieval depth.
- Improved Document Discriminability: Enhanced representation separation in soft variants, potentially improving context-sensitive retrieval and factual grounding.
- Modular Adaptation: Clearer semantic boundaries for reusable task logic and factual content, which is critical for continual learning, knowledge updates, and fine-grained editing.
Theoretically, this architectural decoupling resonates with continual learning literature, orthogonality-regularized adaptation and null-space knowledge editing, promising future directions for external memory systems and modular adaptation in LLMs.
Limitations and Future Directions
The scope of validation is limited to initial empirical settings, modest retrieval depths, and a fixed LoRA parameterization. Potential avenues for further research include:
- Investigation across more model architectures, larger retrieval corpora, and complex multi-hop reasoning tasks.
- Optimization of orthogonality regularization strength and null-space adaptation tradeoffs.
- Integration with dynamic retrieval, test-time parameter activation, and memory editing methodologies.
Conclusion
Orthogonal Subspace Decomposition provides a principled framework for disentangling task-general and document-specific knowledge in parametric RAG, enabling more robust multi-document adapter composition and mitigating parameter interference. Empirical evidence supports the compositional benefits of decoupled LoRA modules, marking a significant advance toward scalable and modular external memory for LLMs (2604.26768).