- The paper's main contribution is the introduction of a multi-tier framework integrating evidence, supervision, and staged autonomy to operationalize measurable trust in clinical AI.
- It employs a layered architecture with rule-based cores, AI assistants, and human oversight to strategically manage clinical risk and error escalation.
- The framework establishes trust metrics that quantify system performance, ensuring transparent, evidence-driven evaluations and responsible AI deployment.
Engineering Measurable Trust in Clinical AI: A Multi-Layer Framework Integrating Evidence, Supervision, and Staged Autonomy
Introduction
Modern clinical AI, especially LLM-based systems, increasingly permeate healthcare workflows, including documentation, triage, communication, and structured data extraction. However, the transition from promising model outputs to genuine clinical trustworthiness remains unresolved. The paper "From Black-Box Confidence to Measurable Trust in Clinical AI: A Framework for Evidence, Supervision, and Staged Autonomy" (2604.26671) addresses this gap by shifting the paradigm from black-box model confidence—rooted in plausibility and accuracy—towards a system-level trust architecture underpinned by evidence, multi-layer supervision, graduated authority, and measurable trust metrics. This essay critically examines its proposed architecture, underlying principles, and the implications for clinical AI deployment.
Limitations of Current Clinical AI Deployment
Empirical literature affirms the utility of LLMs for augmentative tasks such as summarization, information extraction, and draft generation; however, these models fail to reliably support autonomous, high-stakes clinical decision-making due to non-trivial error modes, lack of traceability, and the risk of over-calibrated user trust (2604.26671). Overtrust in convincingly articulated, but inaccurate outputs is documented as a recurrent clinical risk, often exacerbating the human review burden rather than alleviating it. Critically, contemporary deployments often lack escalation mechanisms, bounded context management, and evidence trails necessary for addressing asymmetrical risk and legal accountability.
Architectural Grounding of Measurable Trust
The authors advocate that trust in clinical AI should be engineered rather than assumed—a systemic property emergent from a deliberate architecture rather than from model scale. Trust must be operationalized through three foundational principles: (1) evidence integration, (2) layered supervision, and (3) staged autonomy with explicit action boundaries. They propose a multi-layer system architecture, where each layer reinforces distinct aspects of trust.
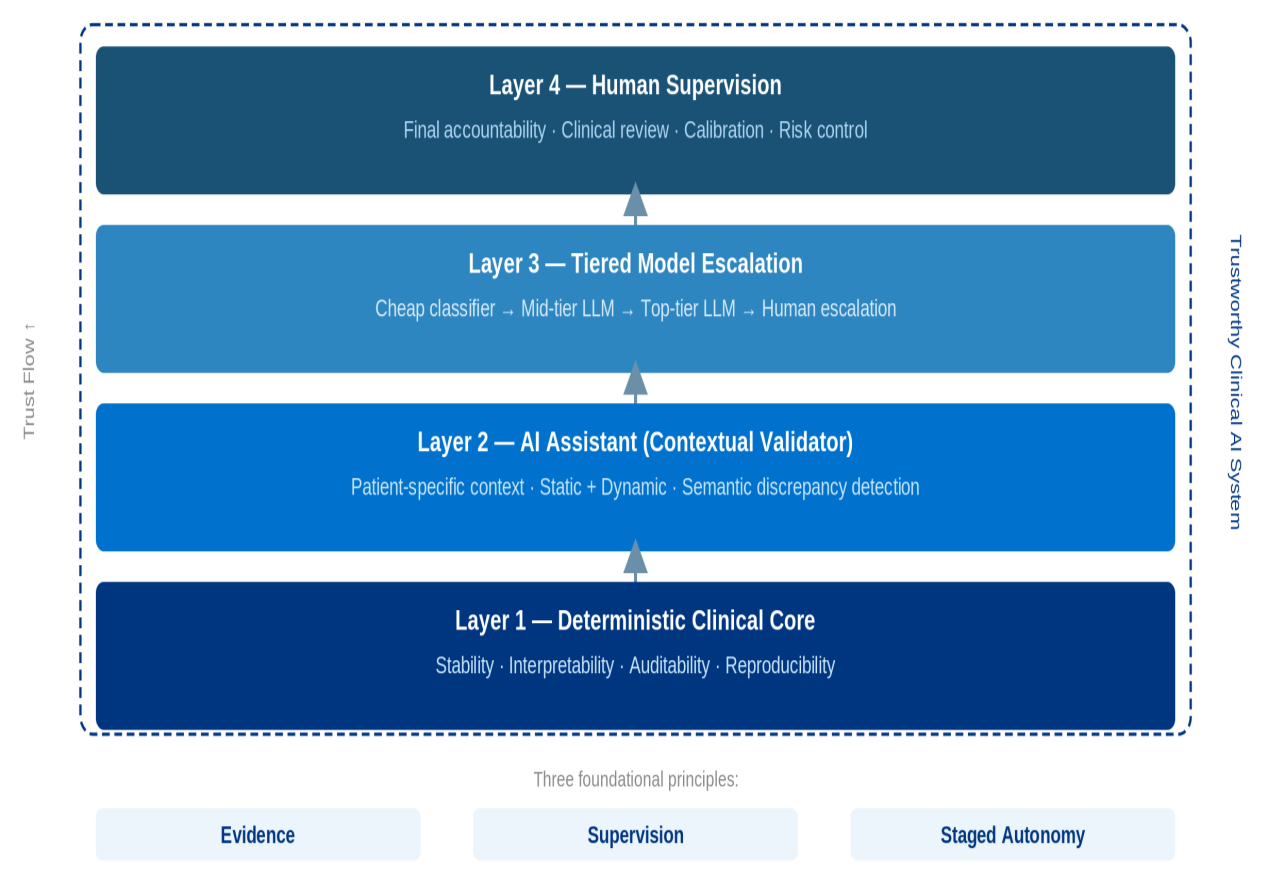
Figure 1: Layered architecture of trustworthy clinical AI, illustrating the interplay among deterministic core, AI assistant, model escalation, and human supervision.
At the base is a deterministic clinical core—typically rule-based or hybrid—ensuring interpretability, stability, and verifiability. An AI assistant functions as a contextual validator, synthesizing both static and dynamic clinical context, offering semantically rich yet bounded recommendations or corrections. Tiered model escalation introduces a hierarchy of LLMs with distinct roles, optimized for cost and noise reduction, whereby only select cases are escalated to higher-capacity models or ultimately human review. Human supervision remains integral, imparting final accountability and risk calibration.
Tiered Model Hierarchies and Staged Autonomy
A central architectural innovation is the tiered model hierarchy, wherein classifiers, mid-tier LLMs, and top-tier LLMs are specialized for routing, semantic screening, and expert-level adjudication, respectively.
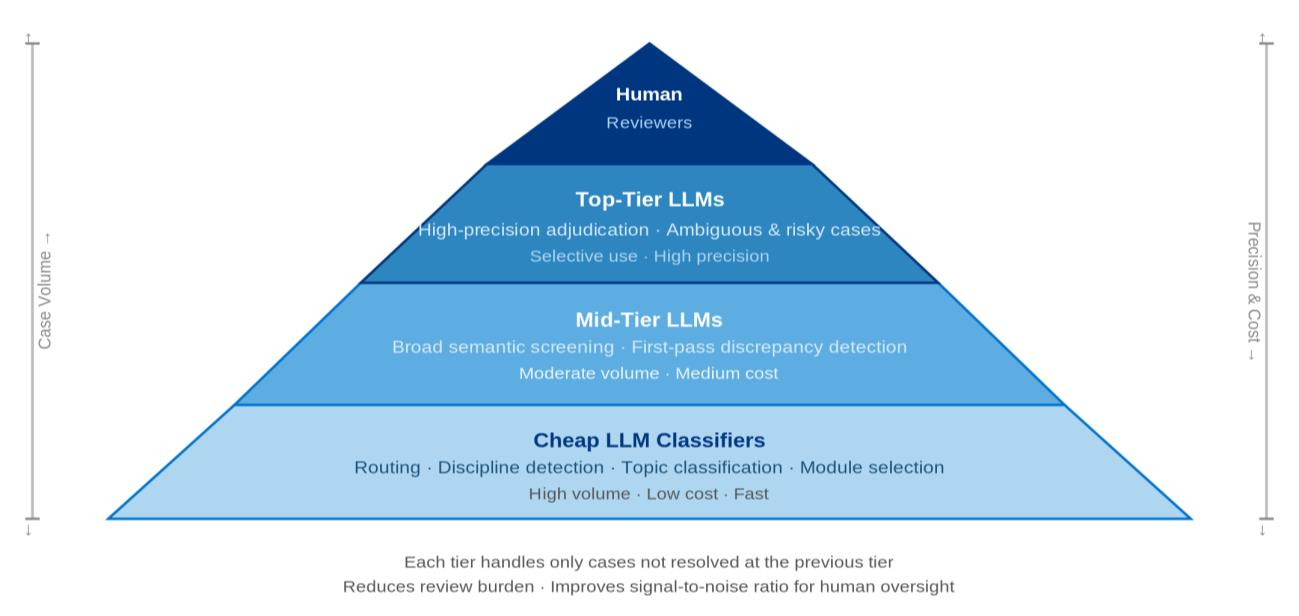
Figure 2: Role-specialized model hierarchy enables scalable, cost-efficient, and selective trust escalation within clinical AI systems.
This design ensures that high-stakes cases are funneled appropriately, minimizing both computational resource expenditure and reviewer overload. The model-tier-in-the-loop, alongside the human-in-the-loop, orchestrates a policy-driven, evidence-based escalation path that addresses the magnitude and clinical significance of errors—a substantial advancement over monolithic deployments.
The architecture further imposes graduated authority, where autonomy is not statically granted but must be explicitly earned via demonstrated reliability, supervised outcomes, and continuous calibration.
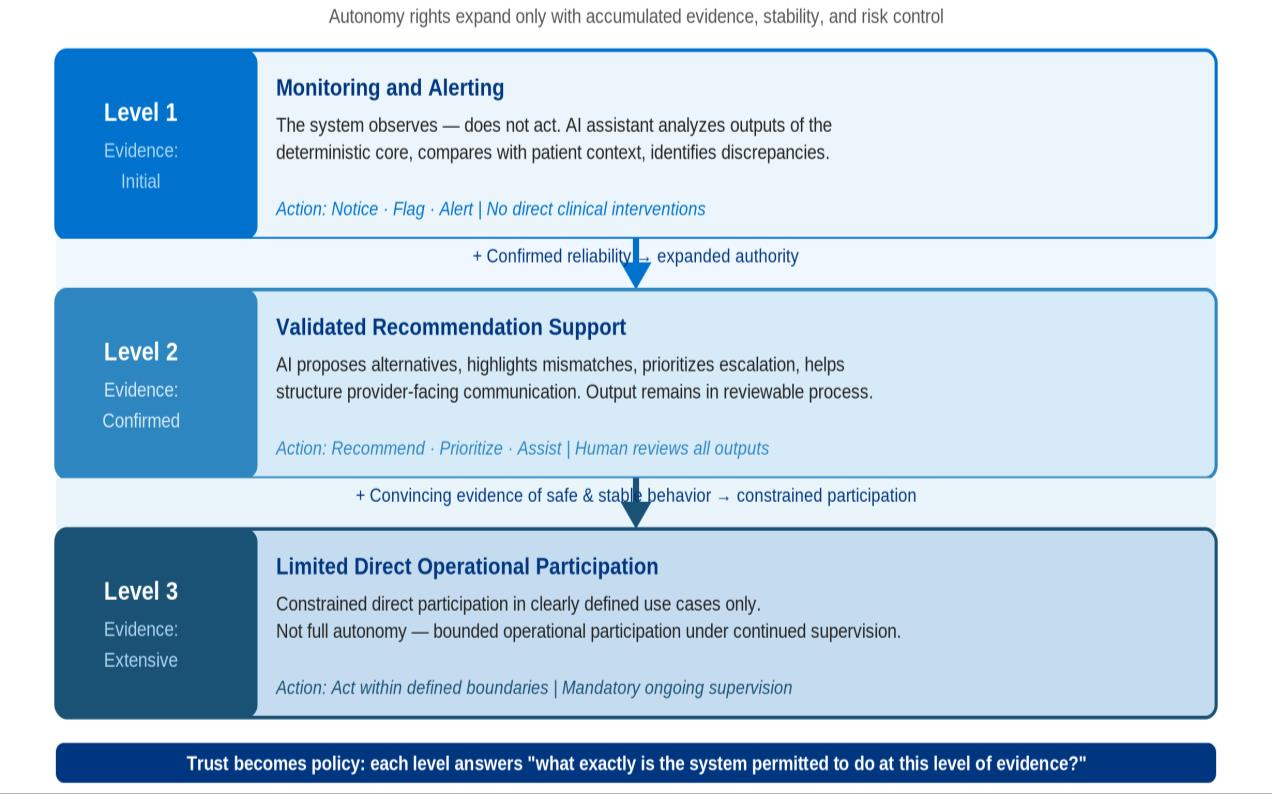
Figure 3: Graduated authority schema operationalizes autonomy as a staged, evidence-driven expansion of system action rights.
This prevents premature escalation of LLM-based agents into high-risk decision domains, underpinning trust as a function of system behavior, not model confidence.
Selective Verification and Bounded Clinical Context
A defining aspect of the framework is the paradigm of selective verification: not all errors or cases warrant equal scrutiny. Verification intensity is commensurate with clinical risk, supporting risk-adaptive deployment while managing reviewer cognitive load.
Bounded clinical context is explicitly formalized—prediction and recommendation are constrained by a svelte, relevance-weighted patient background, incorporating both pruning and deduplication strategies. This approach mitigates context sprawl, prevents prompt drift, and aligns with principles of focused clinical abstraction.
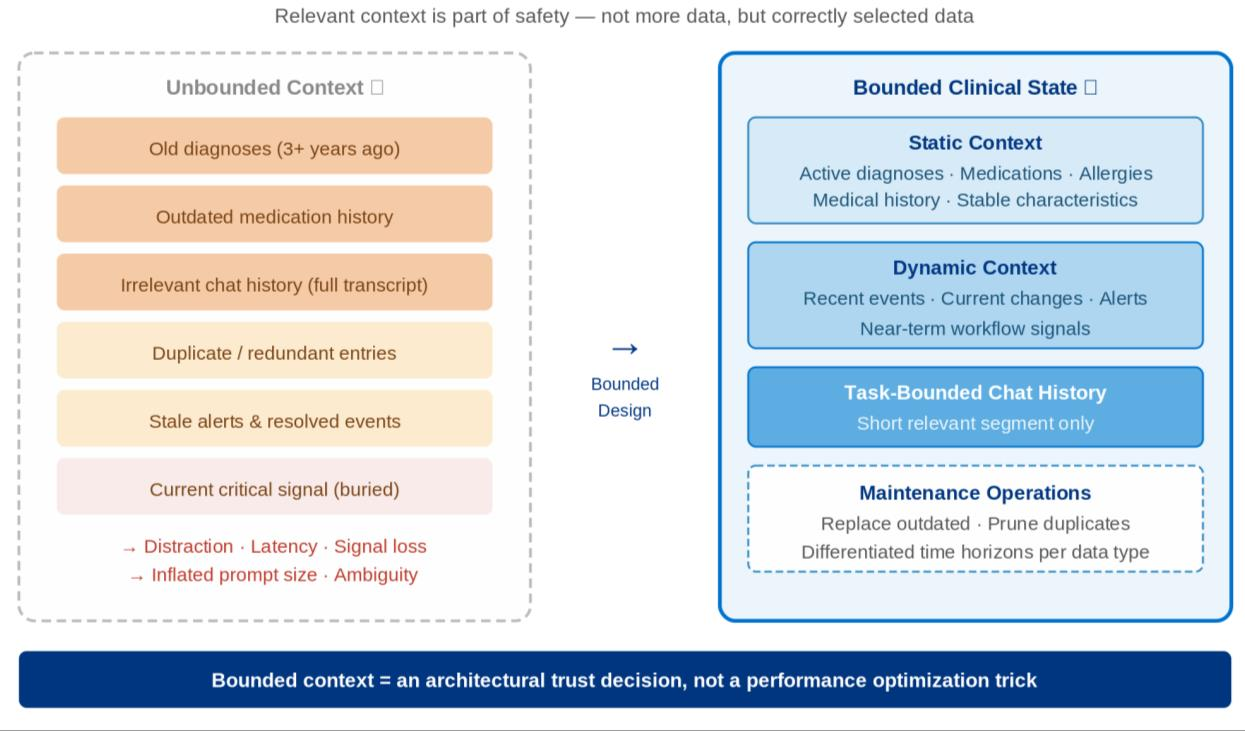
Figure 4: Bounded clinical background design enforces disciplined selection of relevant static and dynamic patient context for robust downstream AI reasoning.
Such boundedness extends to chat and interaction history, ensuring that safety-critical decisions are not obscured by stale or irrelevant context.
Prompt Engineering as System Architecture
Prompt design in this framework is elevated beyond superficial templates, constituting a foundational system architecture component. Modular decomposition—driven by classifiers and dynamic context-aware assembly—supplants monolithic prompt blocks. This enables horizontal scaling of clinical depth without destabilizing model alignment or cognitive balance. Structured outputs reinforce interpretability and downstream auditability.
Trust Metrics: A Metrological Perspective
The operationalization of trust is anchored in a rigorous, metrological framework, mapping each architectural layer to explicit, quantifiable trust metrics, inspired by the Guide to the Expression of Uncertainty in Measurement (GUM) and international metrology standards.
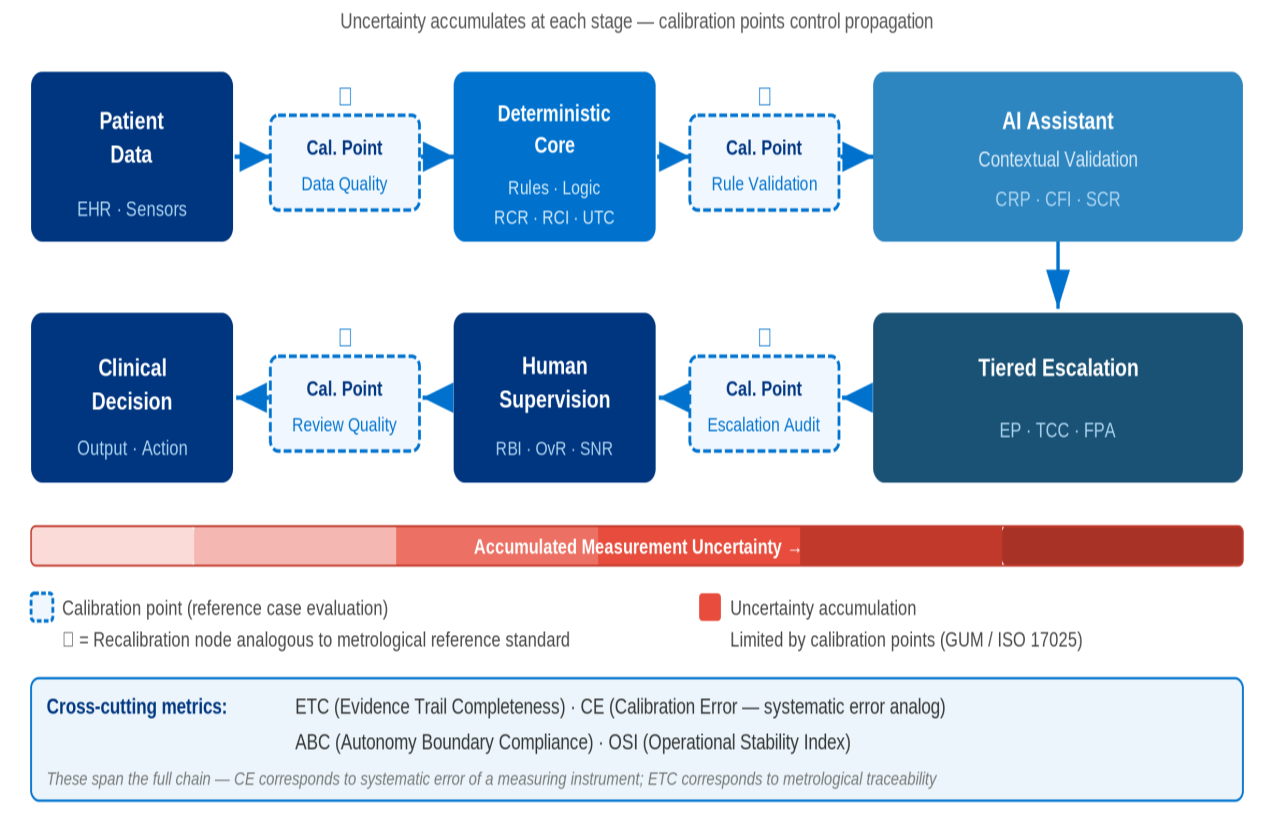
Figure 5: Metrological measurement chain analogizes clinical AI from data acquisition through multi-layer processing to clinical decision, pinpointing calibration and error sources.
For the deterministic core, Rule Coverage Rate, Rule Consistency Index, and Update Traceability Coefficient quantify domain coverage, behavioral stability, and rationale traceability. The AI assistant is assessed by Context Relevance Precision, Freshness Index, and Semantic Consistency Rate. Escalation tiers are evaluated using Escalation Precision, Cost Coefficiency, and False Positive Attenuation. Human supervision metrics include Review Burden, Override Rates, and Signal-to-Noise Ratio.
Cross-layer metrics such as Evidence Trail Completeness, Calibration Error, Autonomy Boundary Compliance, and Operational Stability Index synthesize holistic system trustworthiness.
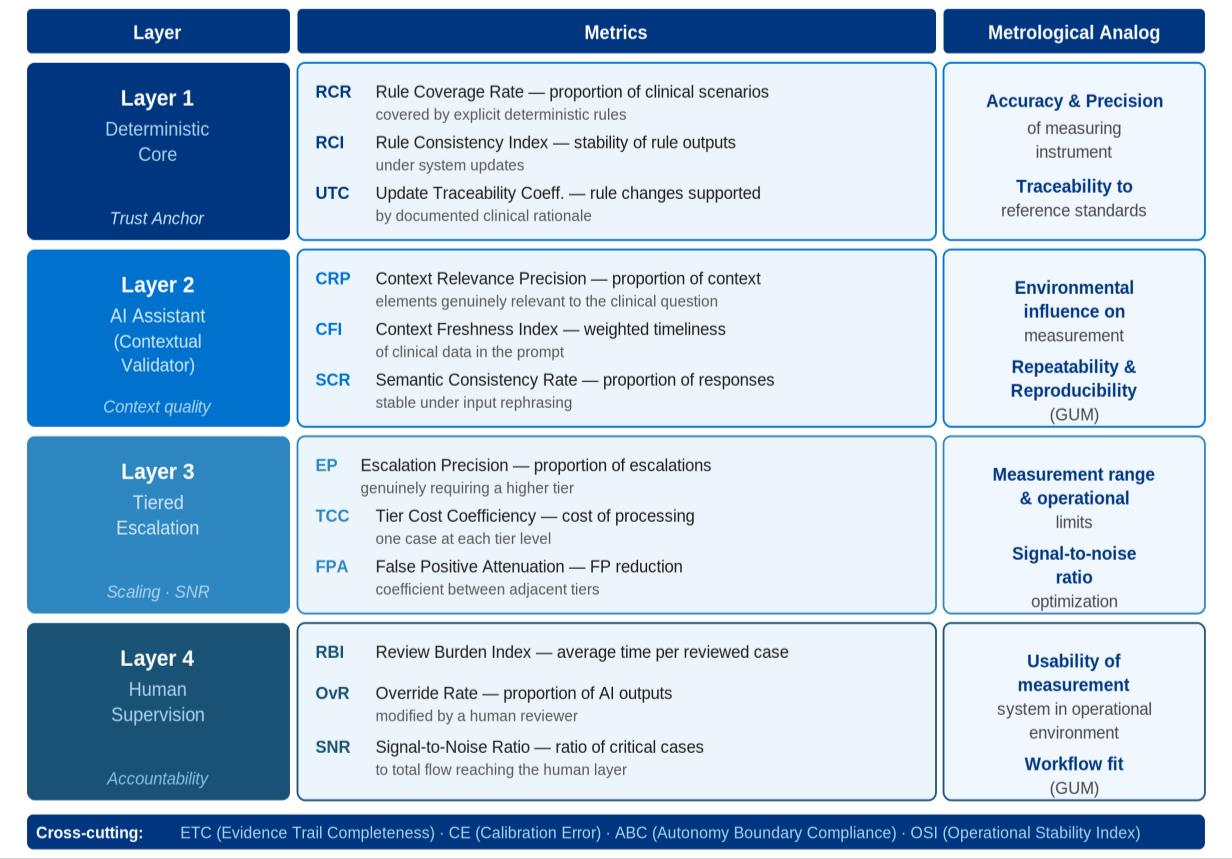
Figure 6: Trust metrics framework mapped explicitly to the proposed clinical AI architectural layers for targeted, repeatable evaluation.
Evaluation Paradigm and Practical Implications
Empirical evaluation shifts from superficial benchmark-driven metrics to rigorous, scenario-based, metrology-aligned calibration. Reference cases serve as analogs to physical calibration standards, with periodic reevaluation for drift and operational stability. This disciplined evaluation reframes development objectives away from maximizing autonomy, toward bounded, progressively scaled intelligence verifiable by empirical evidence and multi-layer supervision.
For clinical informatics teams, this necessitates investments not only in model performance but in context engineering, modular prompt discipline, escalation routing logic, and workflow-aligned human review processes.
Conclusion
This work reconceptualizes clinical AI trust as an architecturally instantiated, measurable system property, integrating evidence trails, human supervision, staged model escalation, disciplined context handling, and prompt engineering within a metrologically framed trust metrics architecture. Deterministic and generative methods are synthesized—not as adversaries but as mutually reinforcing pillars—while staged autonomy and selective verification guard against both under- and over-delegation. The resulting paradigm transitions clinical AI evaluation from subjective, black-box performance impressions to transparent, quantifiable trust targeted for real-world deployment.
The proposed measurable trust framework directly supports future directions in clinical AI governance: incorporating formal measurement uncertainty, operational limits, adaptive calibration, and clear-cut criteria for staged autonomy scaling. As empirical validation proceeds, such architectures may define the next standard for responsible and robust AI integration into clinical practice.

