- The paper introduces a training-free pipeline that uses multimodal and reasoning LLMs to achieve dense, temporally precise annotation of instructional videos.
- The paper’s method produces 2M annotated steps across 100K videos, significantly improving semantic and temporal alignment (F1: 75.8%, mIoU: 42.9%).
- The paper demonstrates enhanced downstream performance in video captioning, step grounding, and cross-modal retrieval, paving the way for scalable video-language models.
DenseStep2M: A Training-Free, Scalable Pipeline for Dense Instructional Video Annotation
Introduction
DenseStep2M introduces a robust, fully automated pipeline for the large-scale annotation of instructional videos, producing temporally grounded procedural step annotations that are essential for advanced long-term video understanding. The authors address fundamental limitations of previous instructional video datasets—in particular noisy ASR, poor temporal alignment between narration and visual activity, and the lack of dense, semantically rich step-level annotations—by leveraging state-of-the-art Multimodal LLMs (MLLMs) and advanced reasoning LLMs without requiring additional supervised training.
The pipeline yields DenseStep2M, a dataset with 100K curated instructional videos annotated with approximately 2 million timestamped procedural steps. The work further releases DenseCaption100, a dense, human-annotated benchmark for downstream evaluation. Evaluations of both the pipeline and dataset demonstrate pronounced improvements over extant approaches in semantic and temporal alignment of procedural steps, with immediate positive impact for fine-tuning and validating V-(L)LMs on long-form video understanding, captioning, procedural step grounding, and cross-modal retrieval.
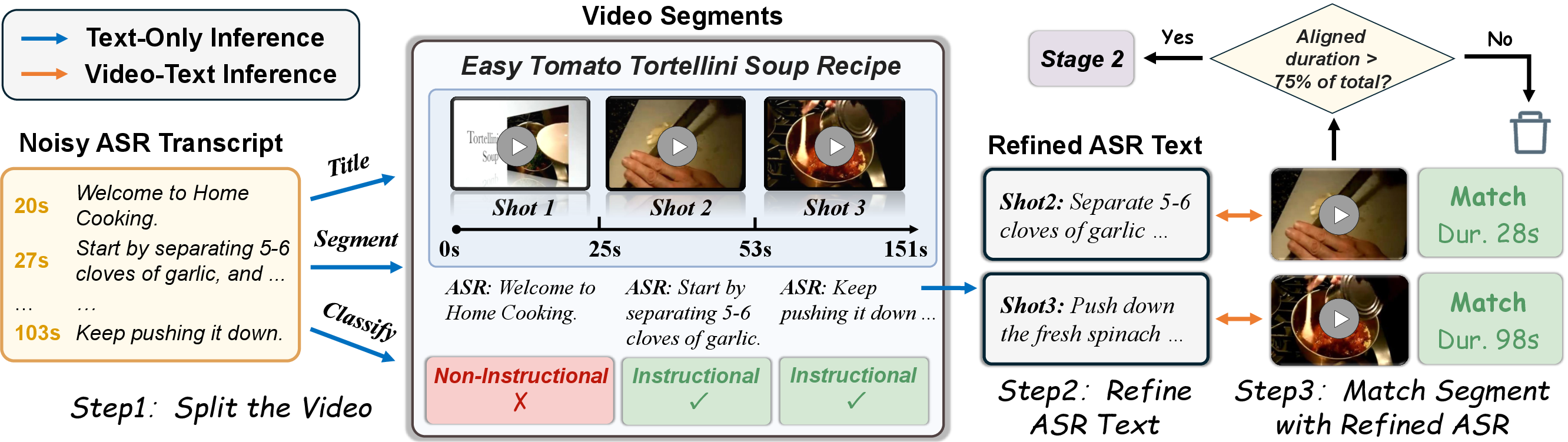
Figure 1: Three-step pipeline for Stage1 (Video Filtering and Segmentation), utilizing WhisperX for ASR, Qwen2.5 for segmentation, and DeepSeek-R1 plus Qwen2.5-VL for visual-semantic alignment.
Pipeline Architecture
The proposed pipeline is decomposed into three principal stages:
Stage 1: Video Filtering and Segmentation
Initial filtering is performed on the HowTo100M dataset using WhisperX-generated ASR transcripts (significantly improving timestamp and transcript quality over the original YouTube pipeline). Qwen2.5 is used to produce video titles and segment the videos into candidate instructional and non-instructional shots based on transcript semantics. The pipeline then invokes DeepSeek-R1 for further ASR refinement and applies Qwen2.5-VL to verify cross-modal semantic alignment between video and transcript segments. Only videos with over 75% instructional content—coinciding in both text and visual modalities—are retained for annotation.


Figure 3: Example of a HowTo100M video segment dominated by non-instructional content, illustrating the rationale for strict filtering.
Stage 2: Instructional Step Generation
Videos are split into visually coherent shots. For each shot, Qwen2.5-VL is provided with sampled frames, local ASR transcript, and the global video title. The model outputs natural-language procedural steps, each paired with explicit start/end timestamps. This multimodal conditioning ensures that generated steps capture both visual actions and narrated content, addressing the classic missed alignment issue of previous text-only pipelines.

Figure 4: Issues in initial step generation (Qwen2.5-VL): disordered steps, hallucinated actions, redundant steps, and inaccurate timestamps.
Stage 3: Step Refinement and Global Temporal Merging
The shot-level candidate steps are then globally audited and rectified by DeepSeek-R1. Taking the global ASR and title as context, DeepSeek-R1 eliminates fragmented, hallucinated, or redundant actions, aligns temporal boundaries, and merges semantically repeated or closely related steps into a canonical, globally ordered list per video. Crucially, this stage prioritizes logical coherence and narrative consistency, leveraging the reasoning LLM's causal inference capabilities.
Figure 2: The right panel shows DeepSeek-R1 refinement, merging, and correcting hallucinated and imprecise initial step proposals.
Dataset Analysis
The resulting DenseStep2M dataset comprises 99K high-purity instructional videos with over 1.9M annotated steps, averaging 19 steps per video—2x the step density of previous open-vocabulary datasets, and a mean step length of 10.4 words. The dataset skews towards Food and Entertaining (59.1%), but also contains substantial data from Hobbies and Crafts, and Home and Garden (see summary plots below).
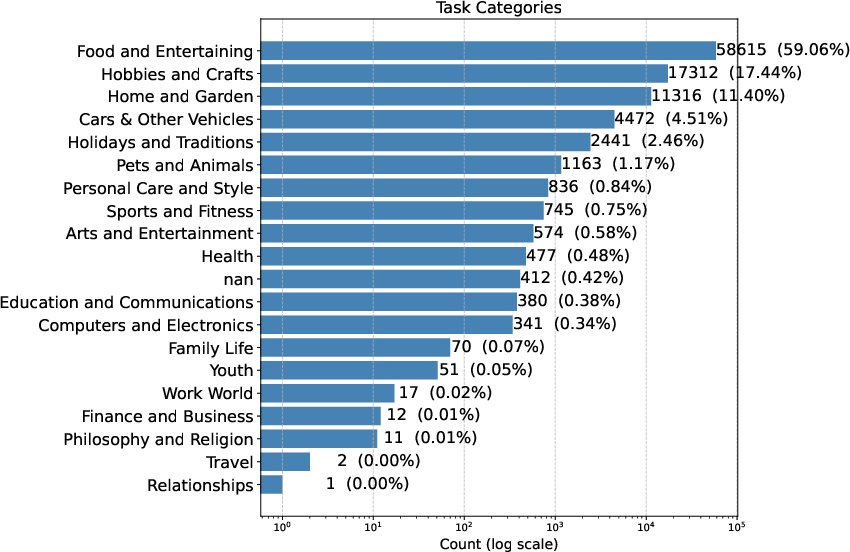
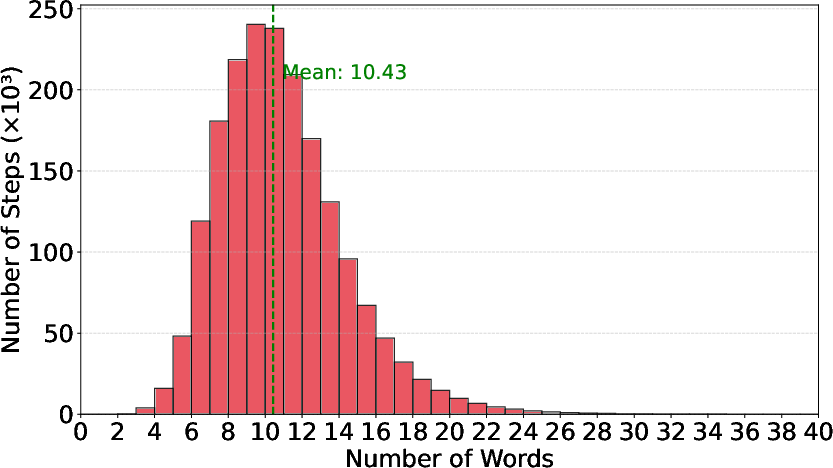
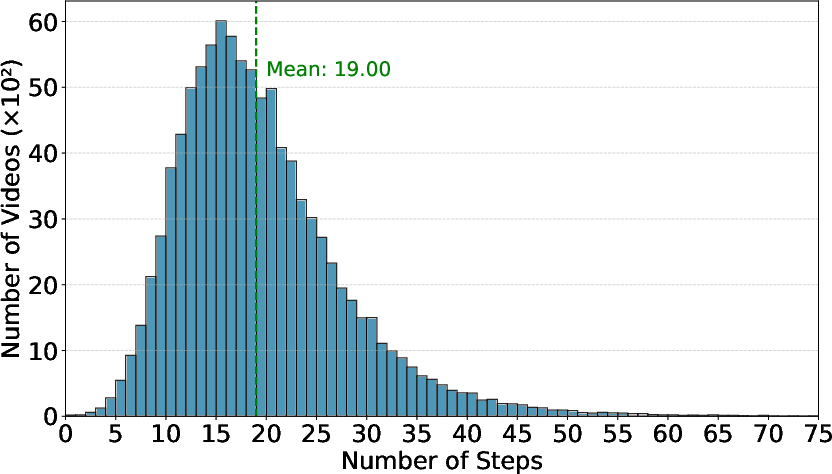

Figure 5: Dataset statistics: category distribution, histogram of step-per-video counts, and step word count.
DenseStep2M annotations showcase:
- Abstract and context-aware steps transcending surface visual actions.
- Explicit multimodal grounding: durations, object quantities, and inferred purposes.
- Systematic filtering for high instructional content and visual-textual alignment.
Furthermore, a manual evaluation demonstrated a dramatic increase in visually and temporally well-aligned steps (from 15.2%/21.3% in HowTo100M to 56.1%/62.0% in DenseStep2M).
Evaluation on Annotation Quality
On the DenseCaption100 benchmark, the full pipeline (Qwen2.5-VL + DeepSeek-R1) outperforms all baselines on F1 (75.8%) and mIoU (42.9%) for step alignment and timestamping, exceeding the prior state-of-the-art by substantial margins. Ablations confirm the necessity of high-capacity VLLMs and the critical synergy between initial visual anchoring and global reasoning-based refinement: the former supplies perceptual precision, the latter ensures logical and narrative coherence.
In addition, the pipeline achieves a METEOR score of 9.4, CIDEr 33.6, and SODA_c 5.6 on YouCook2, outperforming the best non-pretrained models (METEOR +3.3, SODA_c +0.3 absolute).

Figure 6: Illustration of R1-Score computation, demonstrating semantic matching, aggregated timestamp alignment, and computation of precision/recall/F1/mIoU.
Downstream Task Utility
Captioning and Grounding
Models fine-tuned on DenseStep2M demonstrate marked improvements in both dense video captioning (R1-mIoU +4.2%) and procedural step grounding (+8.6% mIoU) compared to vision-agnostic or text-only baselines. Vision-LLMs not fine-tuned on DenseStep2M underperform significantly, confirming the superior utility of this dataset for both semantic and temporal video understanding.
Broad Cross-Modal Retrieval
DenseStep2M-finetuned models (Qwen3-VL-8B, Embedding and Instruct variants) exhibit substantial improvements in exocentric domain tasks (YouCook2 R@1 +29.0%) and competitive/peak performance across egocentric, exocentric, and mixed (ego-exo) video-language retrieval tasks, especially when combined with complementary Ego4D pretraining. Notably, the dataset significantly mitigates exocentric blind-spots that limit ego-centric only training, supporting robust, perspective-invariant representations.
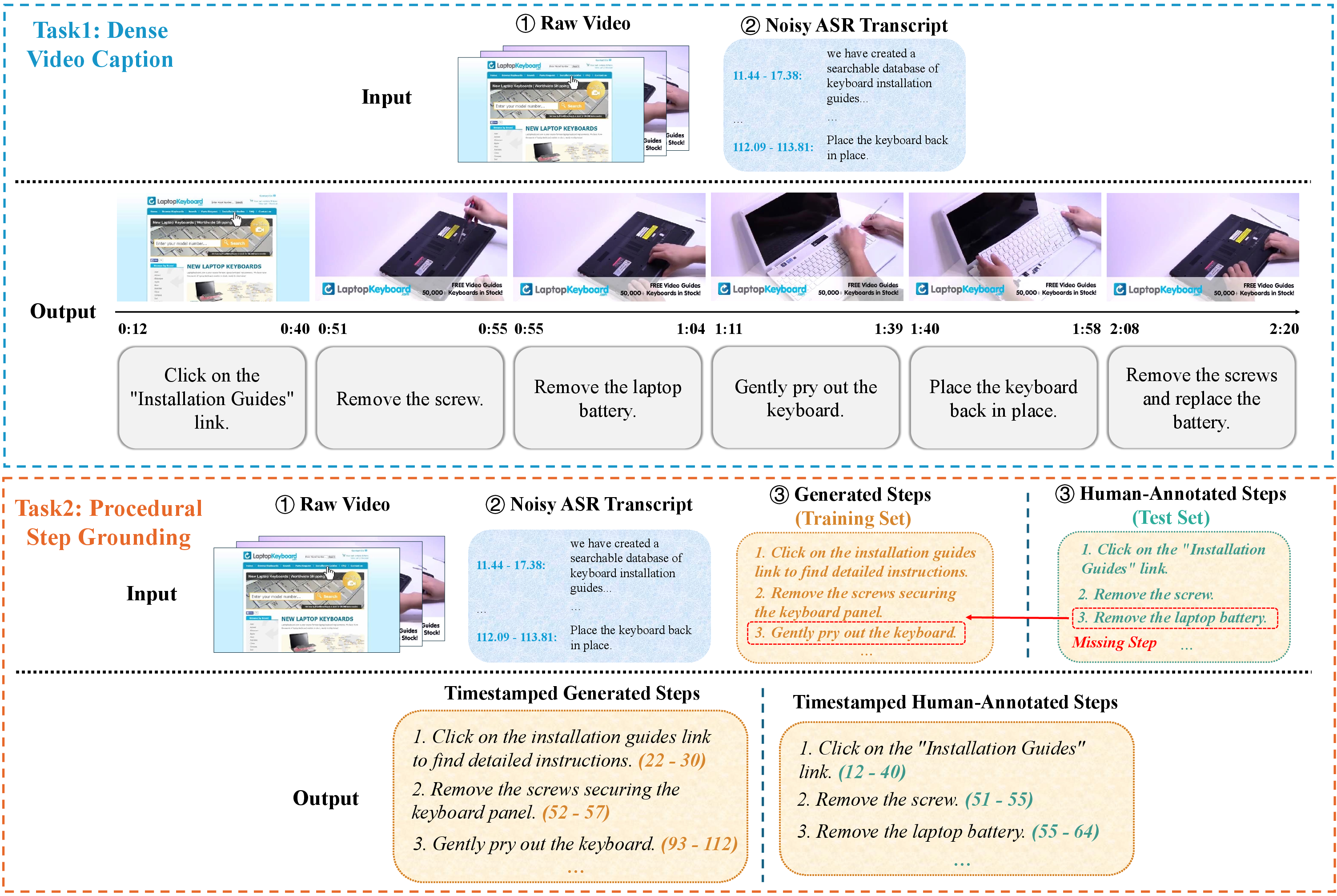
Figure 7: Visualization of downstream tasks enabled by DenseStep2M: (a) dense video captioning and (b) procedural step grounding.
Qualitative Results
Pipeline outputs maintain coherence, temporal accuracy, and step granularity for both short and long instructional videos. Step annotations include rich multimodal references and abstract, context-driven actions.


Figure 8: Qualitative examples from short videos demonstrate robust segmentation and step annotation fidelity by the pipeline.
Implications and Future Directions
DenseStep2M demonstrates that advanced, training-free LLM pipelines, properly architected, can achieve large-scale, semantically rich, and temporally precise annotation of in-the-wild video corpora. The shift from heuristic, noisy ASR-based alignment to joint multimodal and reasoning LLM curation supports research into fine-grained procedural understanding, long-horizon activity reasoning, and robust generative video-language modeling.
The dataset and pipeline enable the development of V-(L)LMs capable of truly scalable cross-task and cross-perspective transfer, bridging exocentric and egocentric video understanding, supporting embodied AI, and facilitating human-assistive applications.
Limitations include residual dependence on LLM and ASR errors, partial domain imbalance, and the upstream propagation of source data biases. Future work should integrate causal scene graph construction, unified video and dialog annotation, and further diversify sourcing beyond existing corpora.
Conclusion
DenseStep2M establishes a new paradigm in the automatic, training-free annotation of dense instructional video data, unifying high-density procedural annotation, multimodal temporal grounding, and large-scale scalability. The pipeline sets a new benchmark for dataset quality and enables state-of-the-art performance on a variety of downstream long-form video tasks, significantly advancing the capabilities and generality of video-language modeling systems.