- The paper shows that integrating text-only data at the encoder level leads to notable reductions in word error rate (WER).
- It compares TTS-based augmentation and pseudo-speech-encoder strategies, emphasizing the latter's efficiency and scalability.
- Experimental results indicate that a simple random duration pseudo-speech-encoder can outperform more complex modality matching approaches.
Text-Only Data Utilization in Encoder-Dominated Speech Recognition Models
Introduction
The paper "Text-Utilization for Encoder-dominated Speech Recognition Models" (2604.26514) addresses efficient integration of text-only data for automatic speech recognition (ASR) in models where the encoder dominates representational capacity and computation. Traditional approaches for leveraging text-only data include shallow fusion of separately trained LLMs (LM), text-to-speech (TTS) augmentation, and modality matching. This work provides a systematic comparison of various strategies, showing that models with large encoders and small decoders achieve equal or superior word error rate (WER), particularly when text-only data is incorporated into encoder training.
Approaches for Text-Only Data Integration
The investigation pivots on two principal methods to exploit text-only corpora: TTS-based augmentation and pseudo-speech-encoder architectures. TTS transforms text-only data into synthetic speech, enabling joint training with audio-text pairs. Pseudo-speech-encoders convert text input into representations resembling speech, allowing text-based samples to enter the encoder pathway directly. The central claim is that when text-only data is injected at the encoder level, especially in encoder-heavy models, recognition accuracy significantly improves without incurring the high computational expense of TTS synthesis.
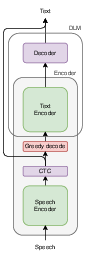
Figure 1: Speech recognition pipeline leveraging denoising LMs and TTS augmentation.
Model Architecture and Encoder-Decoder Configuration
The architecture encompasses three main modules: a speech-only encoder, dynamic downsampling to text-level, and a text-level encoder followed by CTC and an attention-based decoder. The speech encoder processes input features and downscales temporal resolution. Dynamic downsampling employs CTC-based compression to merge frames, targeting text-level granularity. The pseudo-speech-encoder receives text and outputs pseudo-speech features, which feed into the text-level encoder during training on text-only samples.
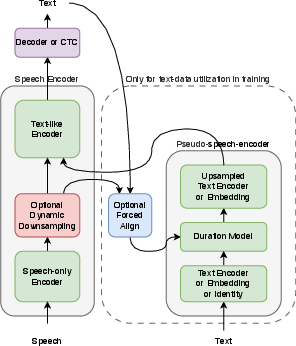
Figure 2: Model with pseudo-speech-encoder facilitating text-only data utilization during training.
Empirically, increasing encoder depth while reducing decoder complexity improves both efficiency and recognition accuracy. Ablation studies demonstrate that training only the decoder with text data yields negligible gains, while encoder-level text training is crucial. Direct integration via pseudo-speech-encoder outperforms decoder-only alternatives.
Dynamic Downsampling and Pseudo-Speech-Encoding
Dynamic downsampling converts speech encoder outputs to text-level representations using intermediate CTC alignment. This enables more efficient processing and aligns speech-text modalities for subsequent layers. The pseudo-speech-encoder variant with random duration models delivers strong results, rivaling more elaborate, trainable architectures. Contrary to prior approaches (e.g. MAESTRO [chen2022maestro]), explicit modality matching and duration modeling are not necessary for optimal performance.
Key findings:
- Simple random duration pseudo-speech-encoder surpasses complex/trained alternatives.
- Downsampling slightly decreases accuracy but increases training speed and reduces compute.
- Conformer blocks within the text-level encoder have marginally superior performance versus Transformer++.
Experimental Results and Numerical Analysis
The study uses LibriSpeech, focusing on large-scale paired audio-text and text-only data. Major findings:
- Encoder-dominated CTC + AED models with text-utilization achieve 1.49-1.60% WER (dev clean), outperforming traditional decoder-heavy LMs.
- TTS-based training of CTC + AED achieves 1.57% WER (dev clean), while pseudo-speech-encoder-based models reach 2.01% (dev clean) for pure CTC.
- Higher text-only data ratios correlate with better WER, but increase training time and data throughput requirements.
- Increasing the fraction of encoder layers exposed to text data yields incremental WER improvements; optimal split is approximately 4 speech-only and 12 text-level encoder layers.
These results underscore that text-only data contributes most effectively when integrated into the encoder training pipeline, especially in models architected with high encoder-to-decoder layer ratios.
Practical and Theoretical Implications
This work has substantial implications for ASR system design:
- Practical: Avoiding TTS reduces computational cost and pipeline complexity. Efficient training and recognition are realized via encoder-dominated models with small decoders, directly compatible with pseudo-speech-encoder training on massive text corpora.
- Theoretical: The findings challenge the necessity of complex duration modeling and modality matching, suggesting that text-speech alignment can be accomplished with simple stochastic models in the encoder pathway.
- Hybrid Training: Combining TTS and encoder text-utilization further improves recognition, but the trade-off favors pseudo-speech-encoder methods for most practical scenarios due to their reduced resource demand.
Future work will explore hybrid architectures and deeper analysis of TTS versus pseudo-speech encoding. Potential directions include leveraging larger or multilingual text corpora and integrating external LMs within encoder-dominated frameworks.
Conclusion
Overall, the paper establishes that encoder-dominated architectures with integrated text-only data via pseudo-speech-encoders are both efficient and effective for ASR. Simple random duration models suffice, obviating the need for complex modality matching or duration prediction. While there remains a gap to TTS-based text-utilization, pseudo-speech-encoding offers superior scalability and operational simplicity, setting the stage for further advancements in resource-efficient ASR training.