- The paper identifies misalignment between input and latent spaces as the key factor driving the accuracy-robustness trade-off and introduces the robust alignment principle.
- It presents the RAAT framework, which employs reduced boundary perturbations and DICAR regularization to enhance both clean accuracy and adversarial robustness.
- Empirical evaluations on CIFAR datasets demonstrate that RAAT consistently outperforms strong adversarial training baselines, achieving a balanced improvement in robustness and accuracy.
Harmonizing Clean Accuracy and Adversarial Robustness via Robust Alignment in Adversarial Training
Introduction
Adversarial Training (AT) has established itself as a primary methodology for enhancing the robustness of deep neural networks (DNNs) against adversarial examples. Despite its empirical success, a persistent trade-off has been observed: increasing adversarial robustness typically degrades clean sample accuracy. The work "Robust Alignment: Harmonizing Clean Accuracy and Adversarial Robustness in Adversarial Training" (2604.26496) systematically investigates this phenomenon and proposes a conceptual and algorithmic framework to mitigate it. Rather than focusing solely on the existing trade-off, the authors introduce the notion of "Robust Alignment," pinpointing the misalignment between input and latent feature spaces as the fundamental cause of the discord between robustness and accuracy. This leads to the development of the Robust Alignment Adversarial Training (RAAT) regime, grounded in both statistical evidence and theoretical insights, and substantiated by extensive empirical results.
Analysis of Adversarial Training and the Accuracy-Robustness Trade-Off
The conventional paradigm of AT leverages strong input perturbations to enforce local classifier invariance within an ϵ-ball around each natural sample, typically leading to highly intricate decision boundaries. This complexity, while conferring pointwise robustness, produces regions of semantic misalignment between input and feature spaces, making the latent manifold susceptible to adversarial perturbations that do not change the true semantics. As illustrated in the initial exposition,
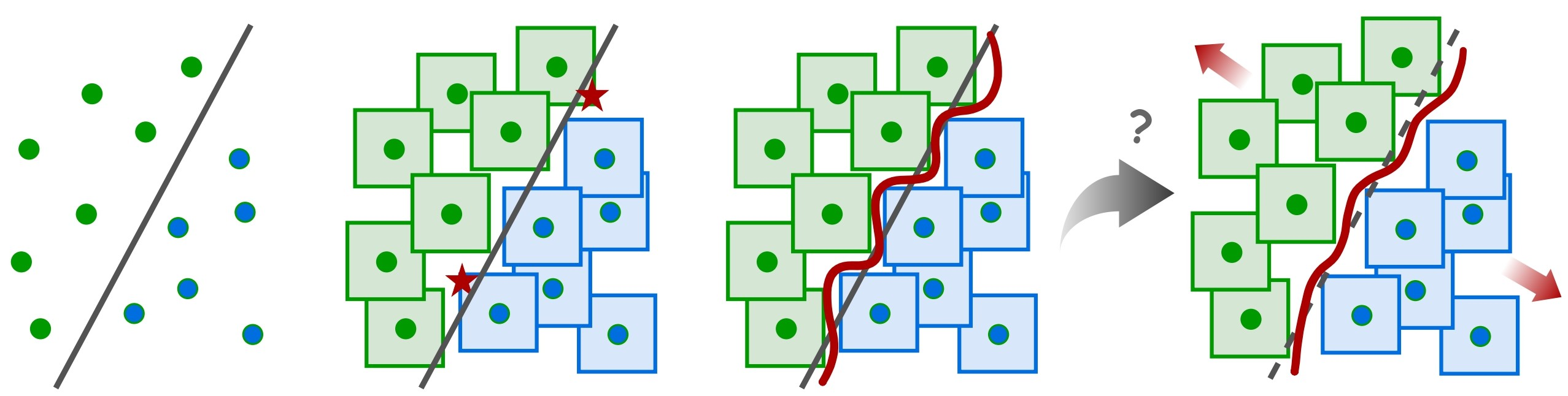
Figure 1: Visualization motivating robust alignment by showing how standard AT increases decision boundary complexity, risking semantic misalignment between input and latent representations.
the increased boundary complexity serves only to support local robustness, failing to generalize well on unseen or out-of-distribution adversarial examples.
The authors further dissect the long-standing debate regarding boundary samples—those correctly classified points near decision surfaces. A systematic evaluation demonstrates that the perturbation intensity applied to these boundary samples has minimal influence on global robustness, yet it does degrade clean accuracy due to the introduction of non-informative noise, as evidenced by controlled experiments on CIFAR-10:
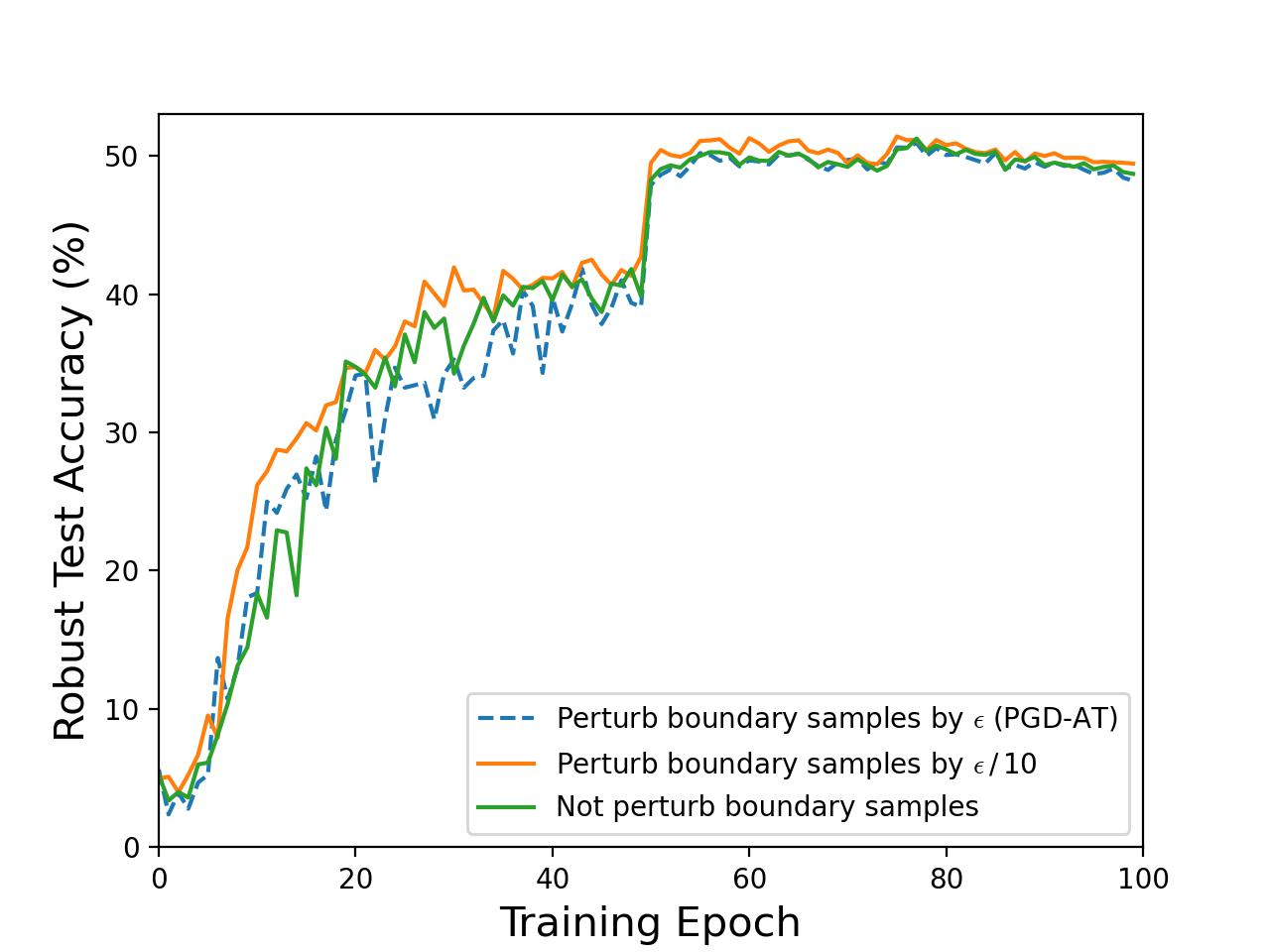
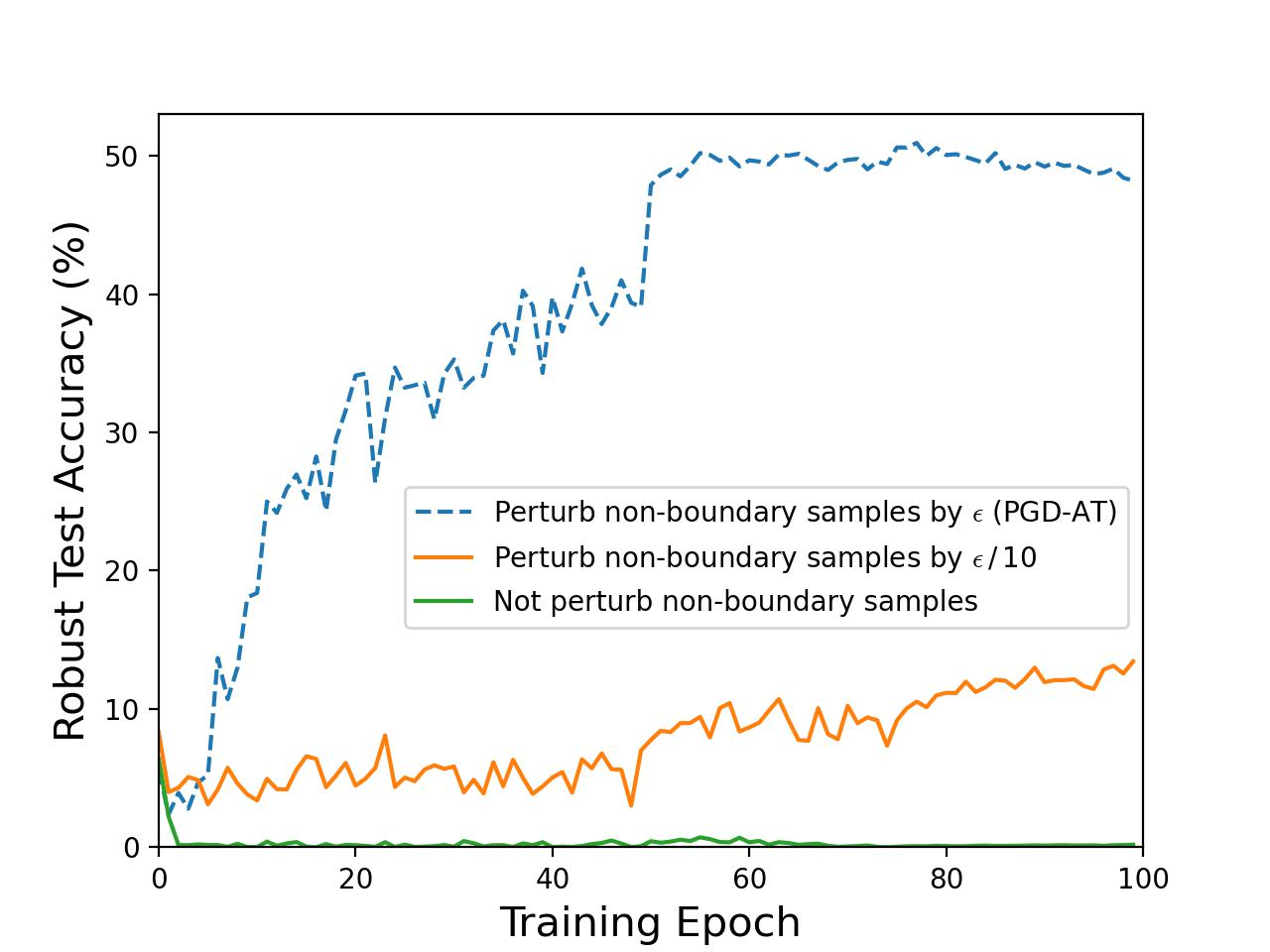
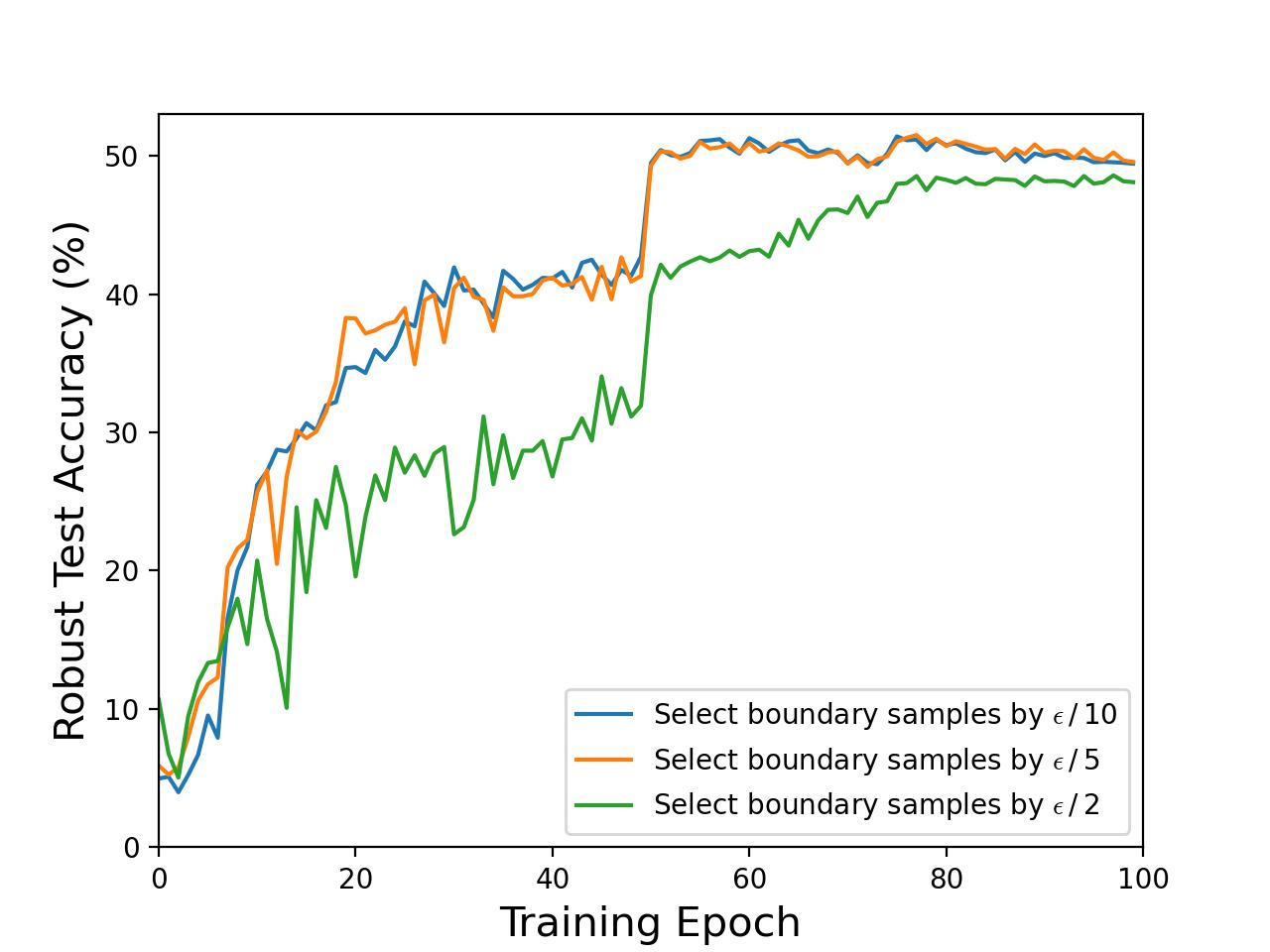
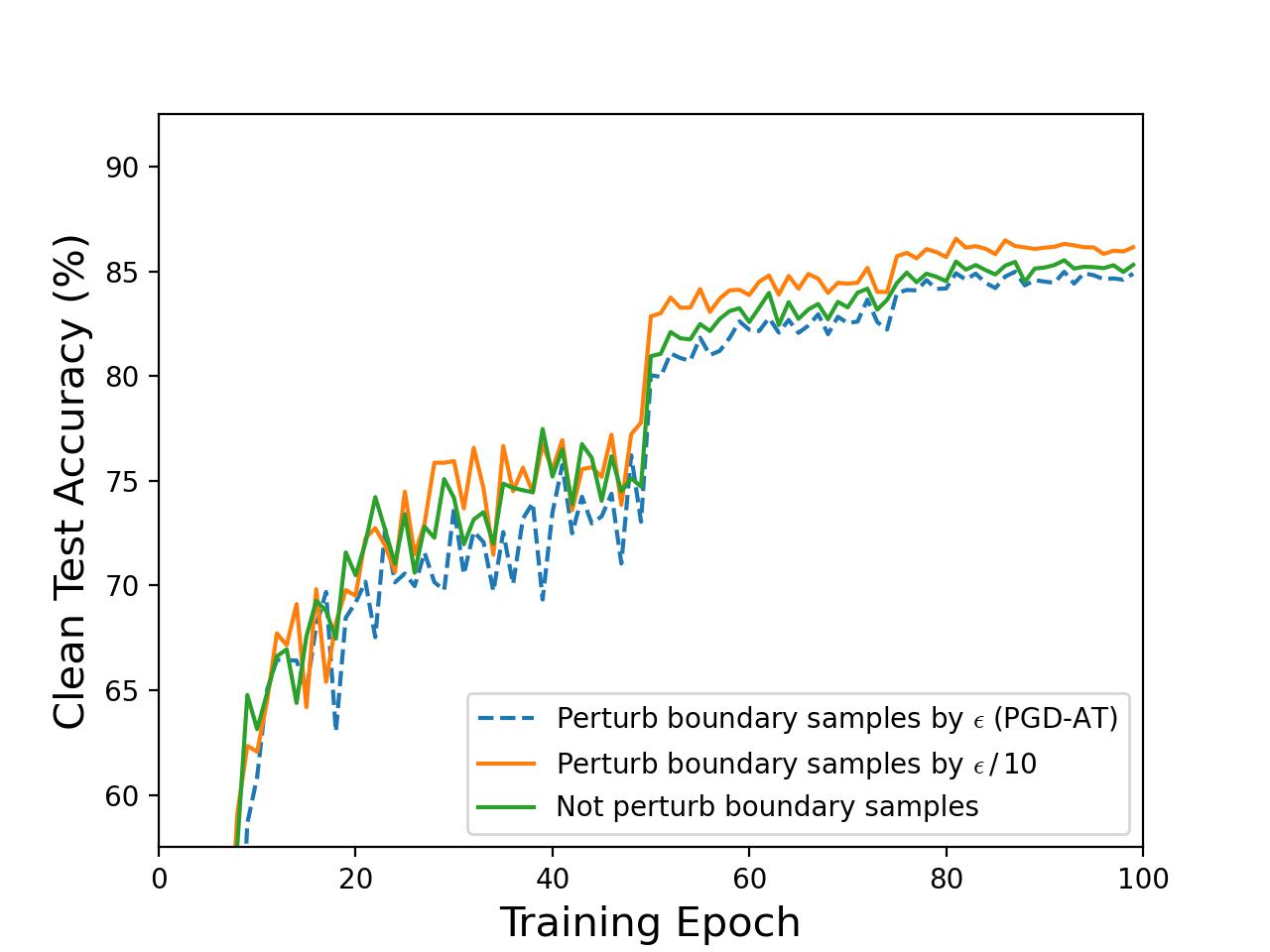
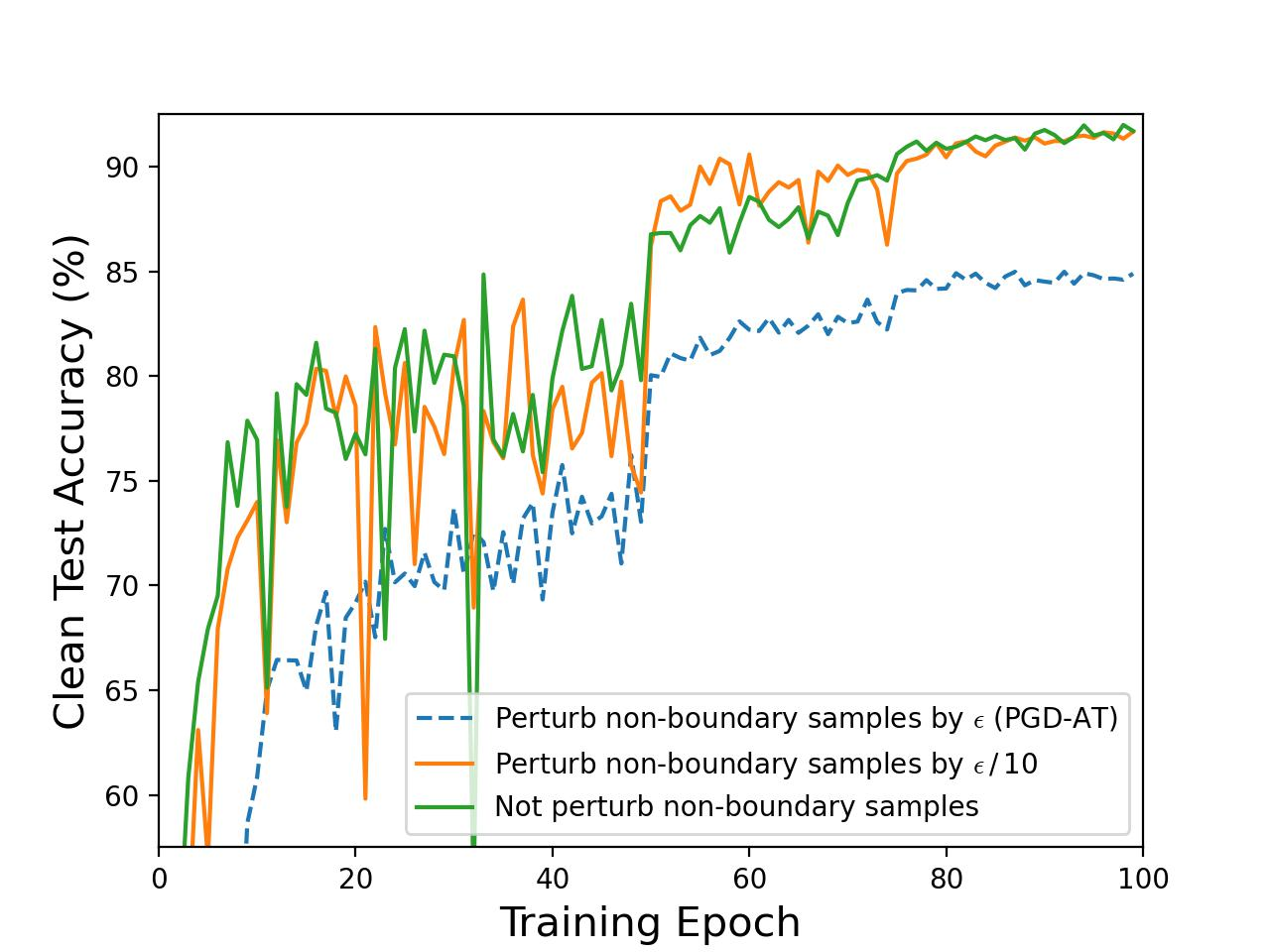
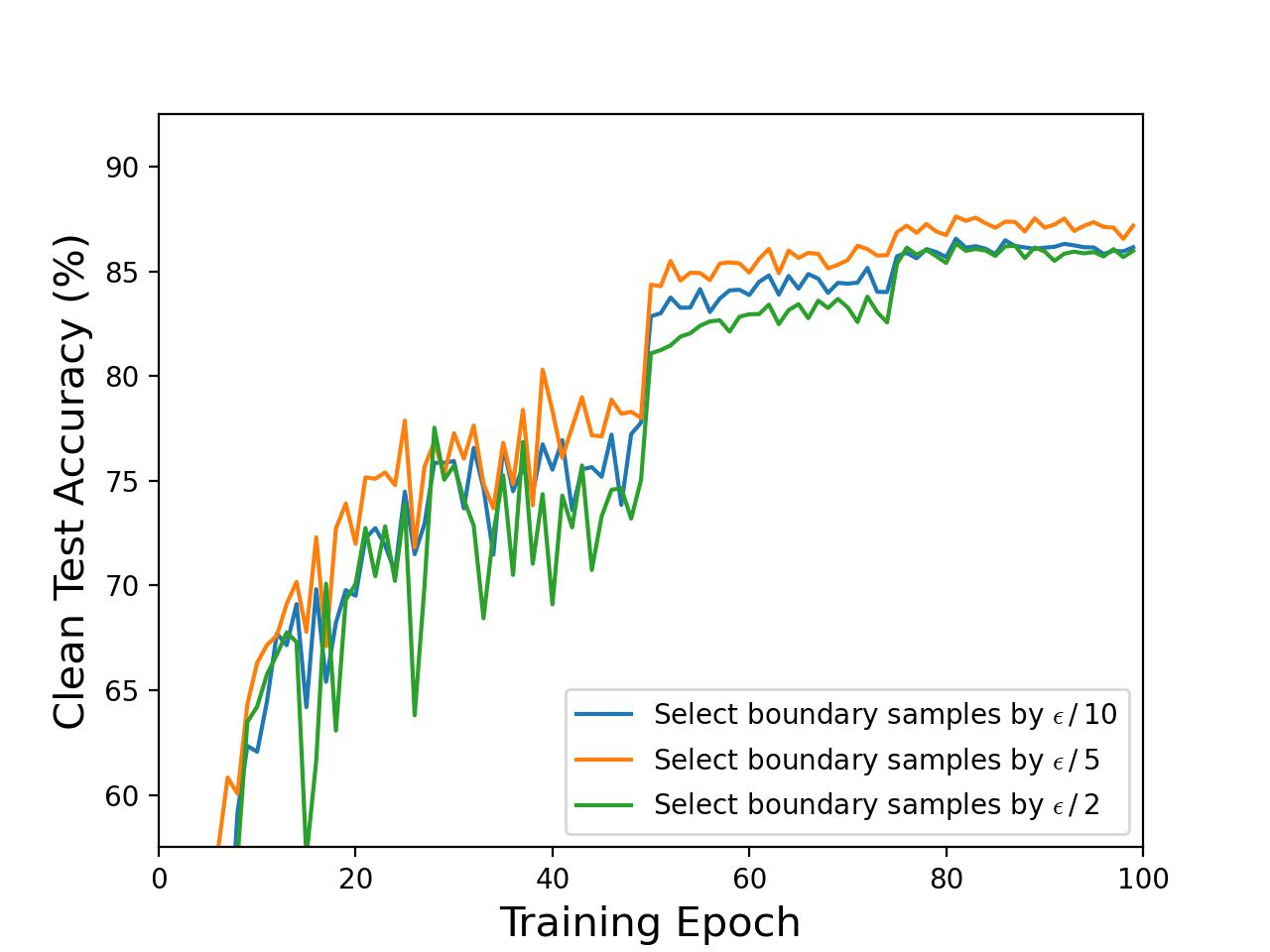
Figure 2: Empirical demonstration that reducing boundary sample perturbation intensities does not diminish model robustness but improves clean accuracy; full perturbation of non-boundary samples is vital for robustness.
This fundamentally challenges prior works that increase focus on such samples, highlighting that uniform AT does not efficiently align input semantics with latent representations.
To resolve the identified misalignment, the authors formalize the Robust Alignment target. This principle advocates that DNNs should modify their latent perceptions in proportion to input perturbations, provided the classifier's prediction remains stable. Robust Alignment thereby bridges input and latent space semantics, reducing inconsistency and mitigating the robustness-accuracy trade-off.
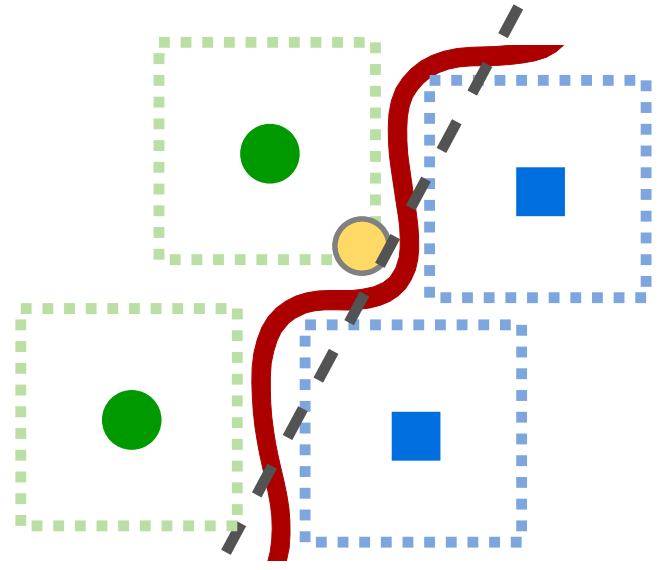
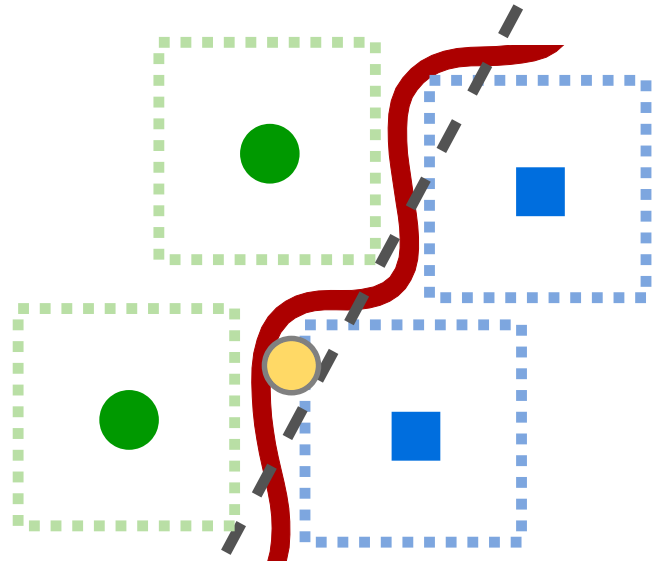
Figure 3: Schematic showing the generalization issues of standard AT and improvements with robust alignment; unaligned domains in latent space enable adversarial vulnerability outside robustified regions.
Implementation of Robust Alignment is twofold:
- Reduced Boundary Perturbations: Perturbation budgets for boundary samples are decreased and fixed, transforming perturbations into learnable, structured signals rather than stochastic noise that exacerbates overfitting and boundary fragmentation.
- Domain Interpolation Consistency Adversarial Regularization (DICAR): This regularizer, rooted in consistency regularization (CR) theory, aligns model predictions for interpolated adversarial inputs derived from different augmentations of the same data point. The mechanism generalizes classical consistency constraints by considering domain-level (rather than pairwise) consistency, semantically knitting latent representations closer to input variations.
The underlying algorithmic pipeline—Robust Alignment Adversarial Training (RAAT)—integrates these strategies within a new adversarial risk formulation, supported by surrogate losses (cross-entropy, margin-boosted losses, and Jensen–Shannon consistency regularization), offering flexibility over standard AT baselines.
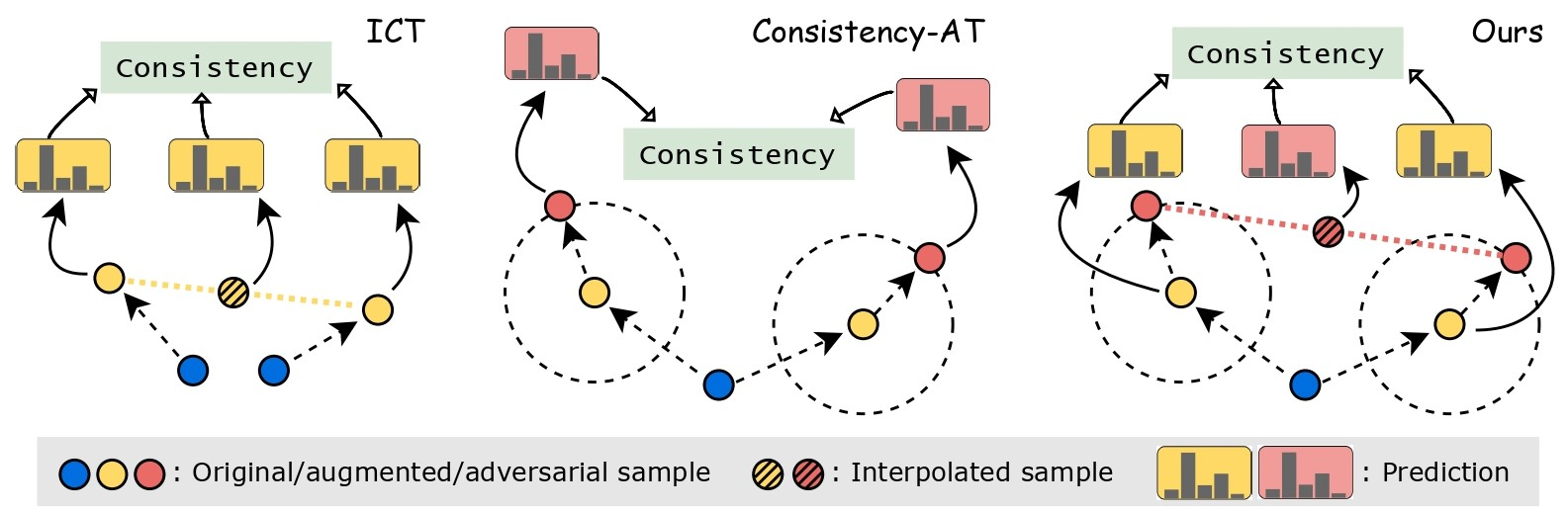
Figure 4: Conceptual comparison of CR-based methods: ICT matches interpolation of predictions with prediction on interpolated sample; Cons-AT aligns adversarial variants from different augmentations; proposed DICAR enforces domain-level consistency between adversarial interpolations and interpolated predictions.
Empirical Evaluation
Comprehensive experiments on CIFAR-10, CIFAR-100, Tiny-ImageNet with ResNet-18, WideResNet-28-10, and PreActResNet-18 architectures reveal the efficacy of RAAT and its advanced variant RAAT++. The framework consistently achieves performance gains over four strong AT baselines (PGD-AT, TRADES, MART, Cons-AT), as well as surpassing a dozen recent SOTA methods. Improvements manifest both in clean accuracy and robustness, quantitatively breaking the classical trade-off:
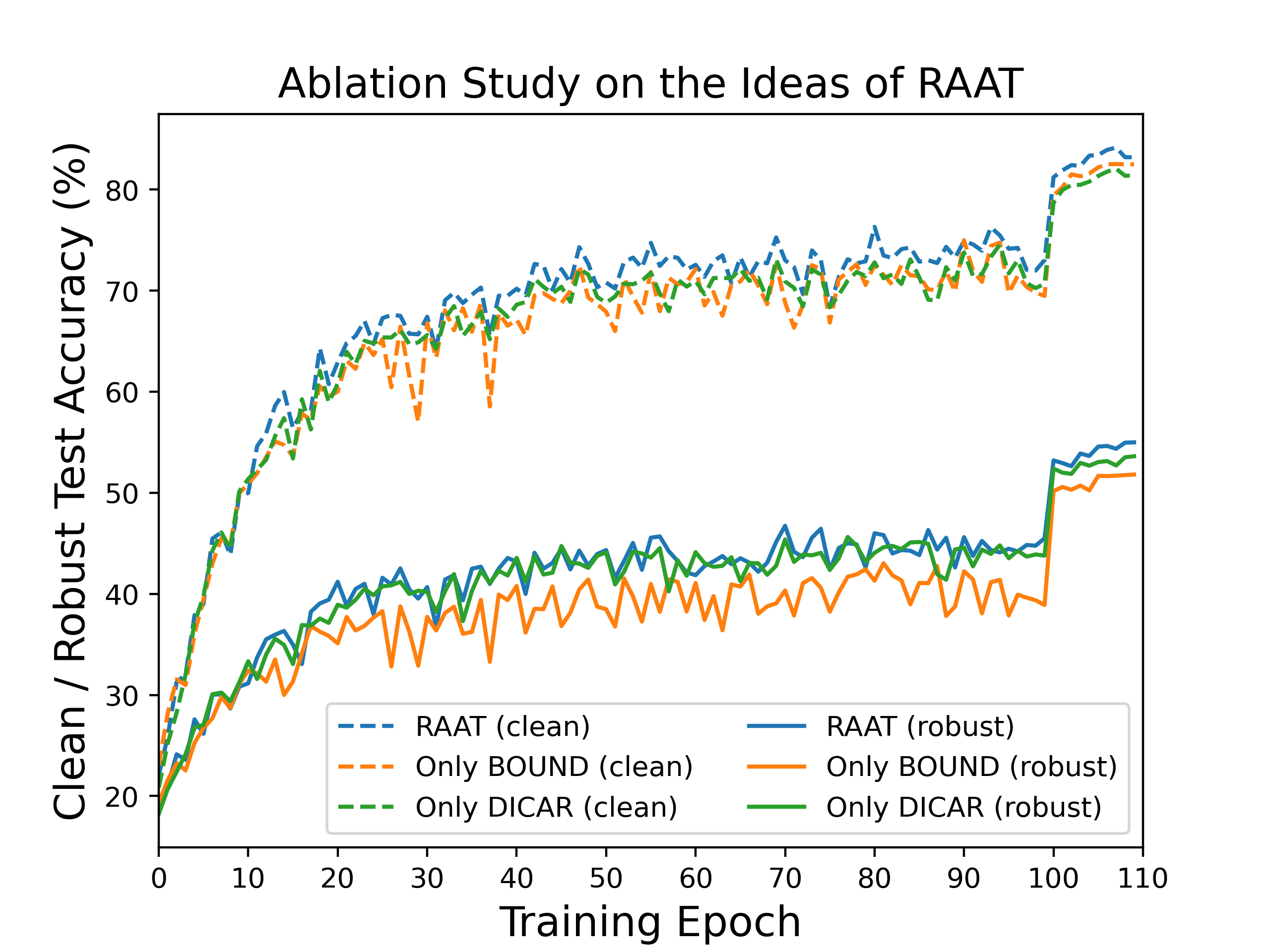
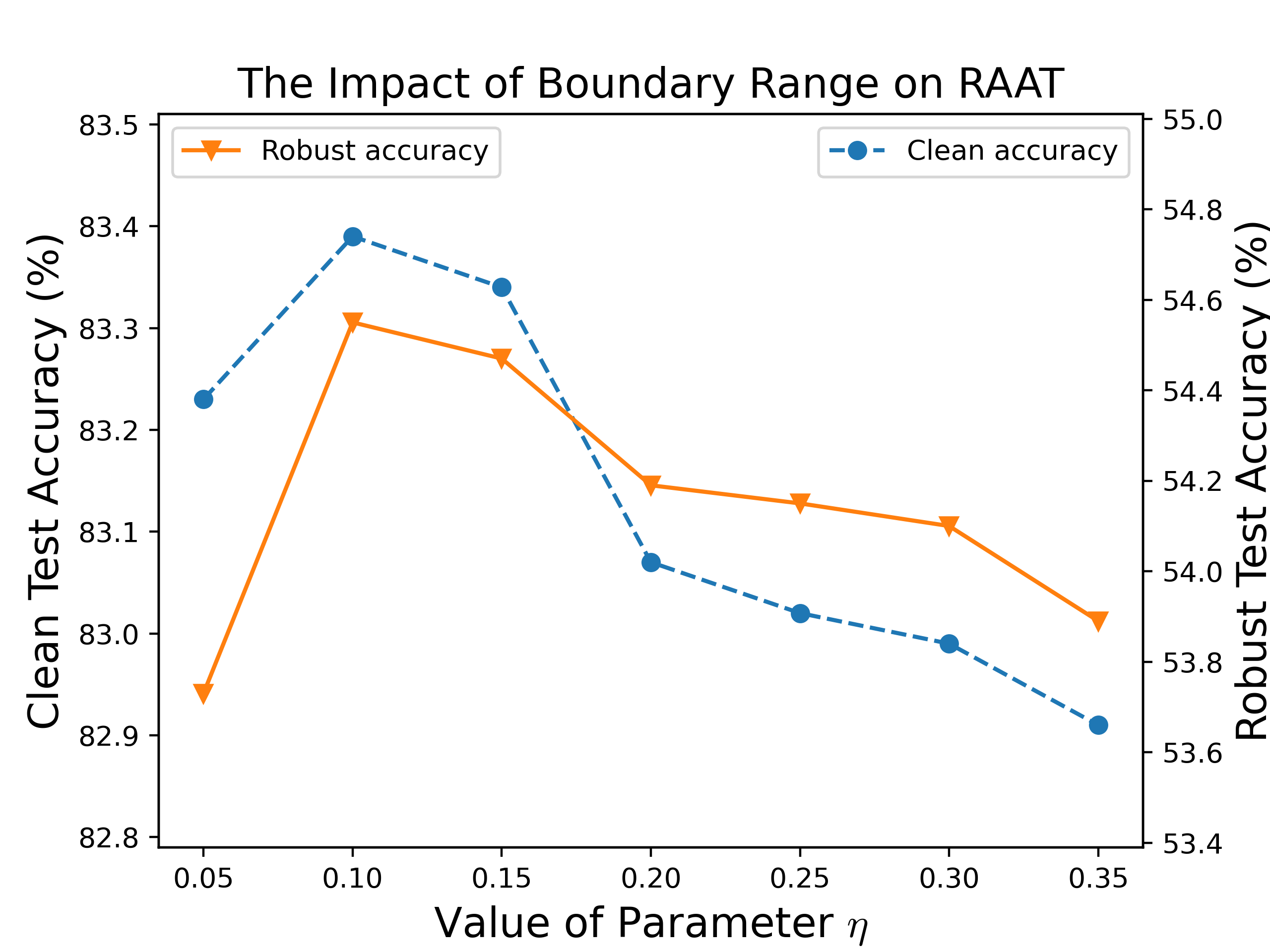
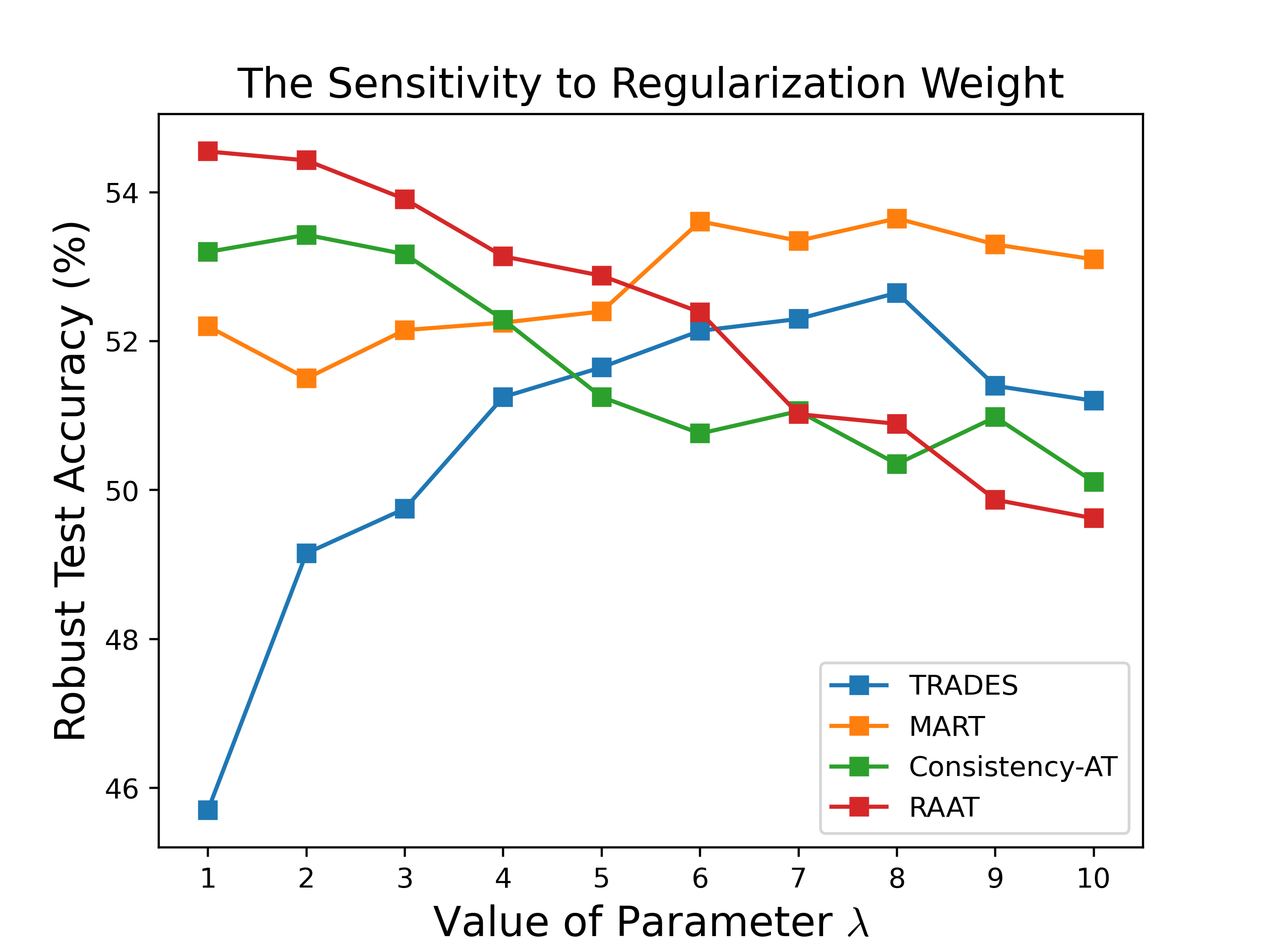
Figure 5: Ablation results on CIFAR-10, showing the contribution of reduced boundary perturbations and DICAR regularization to both robustness and accuracy.
For instance, on CIFAR-100 and PreActResNet-18, RAAT# (integrating ReBAT baseline tricks) achieved the highest mean accuracy/robustness score and the Natural-Robustness Ratio (NRR), demonstrating effective joint optimization of both metrics.
Implications and Future Directions
The findings and formulations in this work expose the limitations of treating adversarial robustness purely as a matter of local prediction invariance. The identification of the input–latent misalignment as a central mechanism clarifies why prior AT regimes stall at a suboptimal trade-off. Practically, RAAT and DICAR offer modular tools to build more generalizable robust models, which is essential for deploying DNNs in safety-critical and distribution-shifting settings.
Theoretically, the interrogation into alignment and DICAR's regularization (provably acting on derivatives of all orders in the loss landscape) sets the stage for new regularization techniques that optimize not just robustness but semantic fidelity across both natural and adversarial domains.
Future research will likely address the computational costs of domain-wise consistency constraints, seek architectural modifications to amplify input–latent alignment, and extend robust alignment frameworks to tasks beyond classification, such as generative modeling or structured prediction under adversarial threat.
Conclusion
This work formalizes and operationalizes robust alignment as the critical factor underlying the accuracy-robustness trade-off in AT. With a new suite of methods—reduced perturbation on boundary samples and DICAR—the proposed RAAT framework achieves harmonization of clean accuracy and adversarial robustness, validated theoretically and empirically across datasets and architectures. The insights on alignment are expected to galvanize further exploration into more efficient, semantically faithful robust learning protocols.

