- The paper introduces EEGVFusion, which integrates self-supervised EEG pre-training, video feature extraction, and optimal transport alignment for robust seizure detection in rodents.
- It employs transformer architectures and cross-modal fusion, ensuring perfect event sensitivity while significantly reducing false positive rates.
- Quantitative results show high balanced accuracy and reliability across sessions, outperforming unimodal approaches in terms of event-level performance.
Multimodal Self-Supervised Fusion for Rodent Seizure Detection: The EEGVFusion Framework
Introduction
High-fidelity continuous seizure monitoring in preclinical epilepsy research is critically dependent on synchronized video and EEG recordings in animal models. Manual annotation remains the de facto standard for such studies, but this approach is both laborious and susceptible to inter-observer variability. This task is further complicated by the complementary failure modes of each modality—behavioral video is easily confounded by stereotyped actions that mimic seizures, while EEG is highly sensitive to motion artifacts during convulsive manifestations.

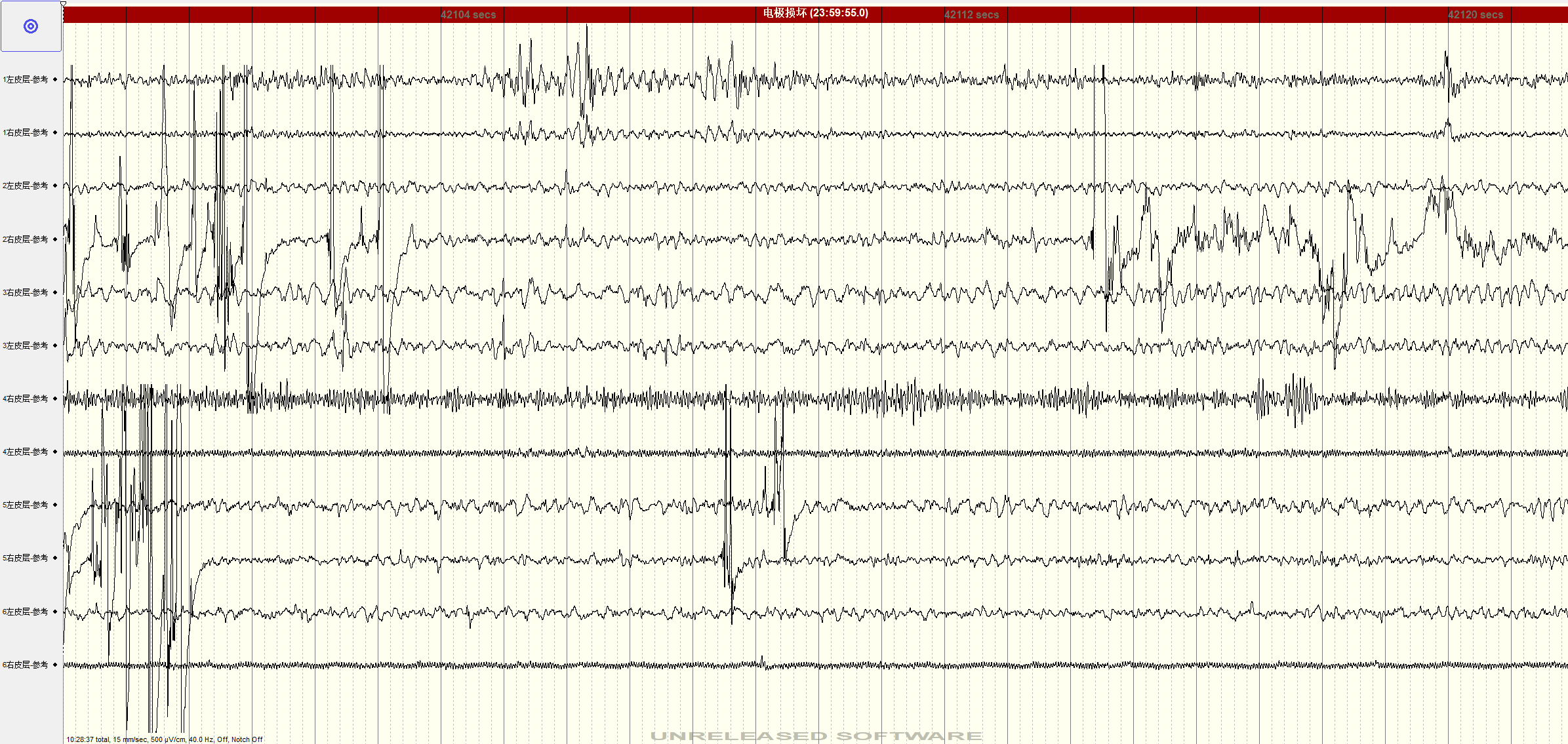
Figure 1: Illustration of the synchronized monitoring platform capturing behavioral video and neural EEG signals in parallel across multiple cages.
Recent advances in transformer-based architectures and self-supervised representation learning present opportunities for developing robust multimodal systems that leverage the distinct strengths of video and EEG evidence. The study introduces EEGVFusion, a self-supervised multimodal framework designed to exploit these advances for the automation of long-term seizure detection in rodent models, with an emphasis on event-level reliability for practical screening.
Methodological Framework
Data Acquisition and Processing
EEGVFusion was validated on a curated, expert-annotated dataset comprising 93 sessions from 15 mice, each involving dual-channel intracranial EEG and continuous behavioral video. Rigorous preprocessing was applied to both modalities: EEG underwent band-pass and notch filtering along with baseline correction, preserving both high-amplitude rhythmic ictal discharges and lower-power interictal backgrounds.
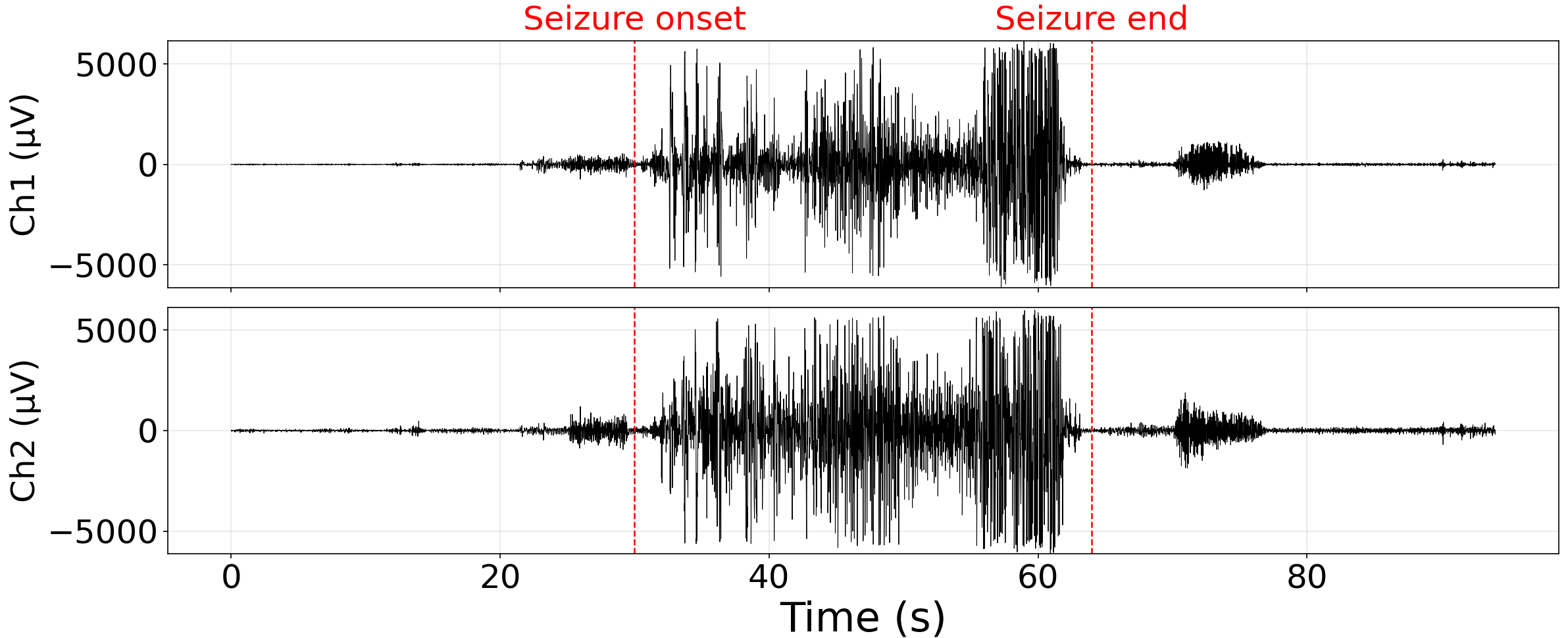
Figure 3: Preprocessed EEG signals during a seizure display distinct high-amplitude, rhythmic patterns clearly aligning with annotated ictal intervals.
Power spectral density (PSD) analyses revealed pronounced separability of seizure versus interictal segments in the frequency domain across subjects.
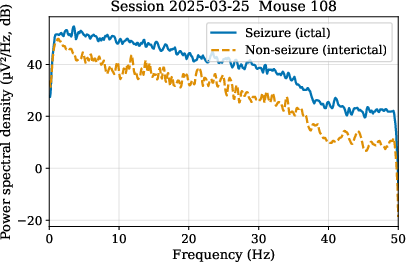
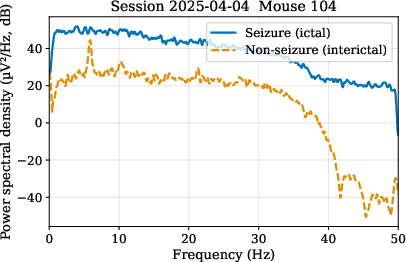
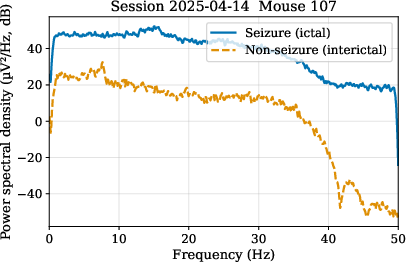
Figure 2: PSD characterization underscores the discriminative frequency signatures associated with seizures in the rodent EEG dataset.
Videos were downsampled to 6.25 fps to balance downstream computational efficiency with retention of macroscopic behavioral attributes relevant for seizure characterization.
Self-Supervised EEG Pre-training via Masked Autoencoding
Robust neural representations were obtained using a modality-adapted Masked Autoencoder (MAE). Patches of the EEG signal, embedded using parallel temporal and spectral encoders, were subject to random masking; the transformer encoder and lightweight decoder were then trained to reconstruct the masked signal, optimizing for mean squared reconstruction error. This procedure enabled robust feature learning strictly from unlabeled data, aligning with recent evidence for the efficacy of masked autoencoding in neural time series domains.
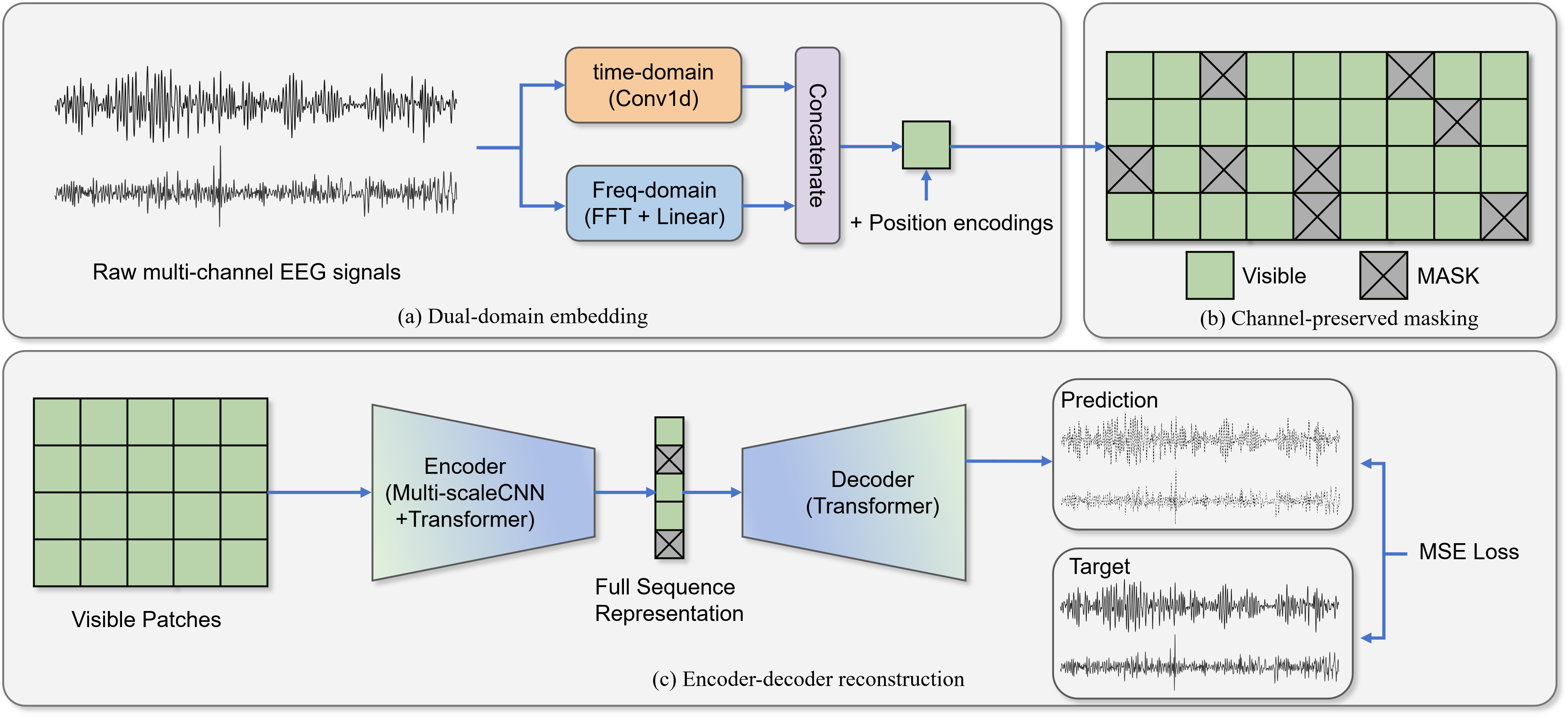
Figure 4: MAE pre-training pipeline: the model reconstructs masked EEG patches, learning transferable features critical for downstream supervised tasks.
Video Feature Extraction and Multimodal Alignment
Spatio-temporal visual features were extracted using VideoMAE v2, capitalizing on its strong inductive bias for modeling temporally extended, partially occluded behavioral patterns typical in murine seizures.
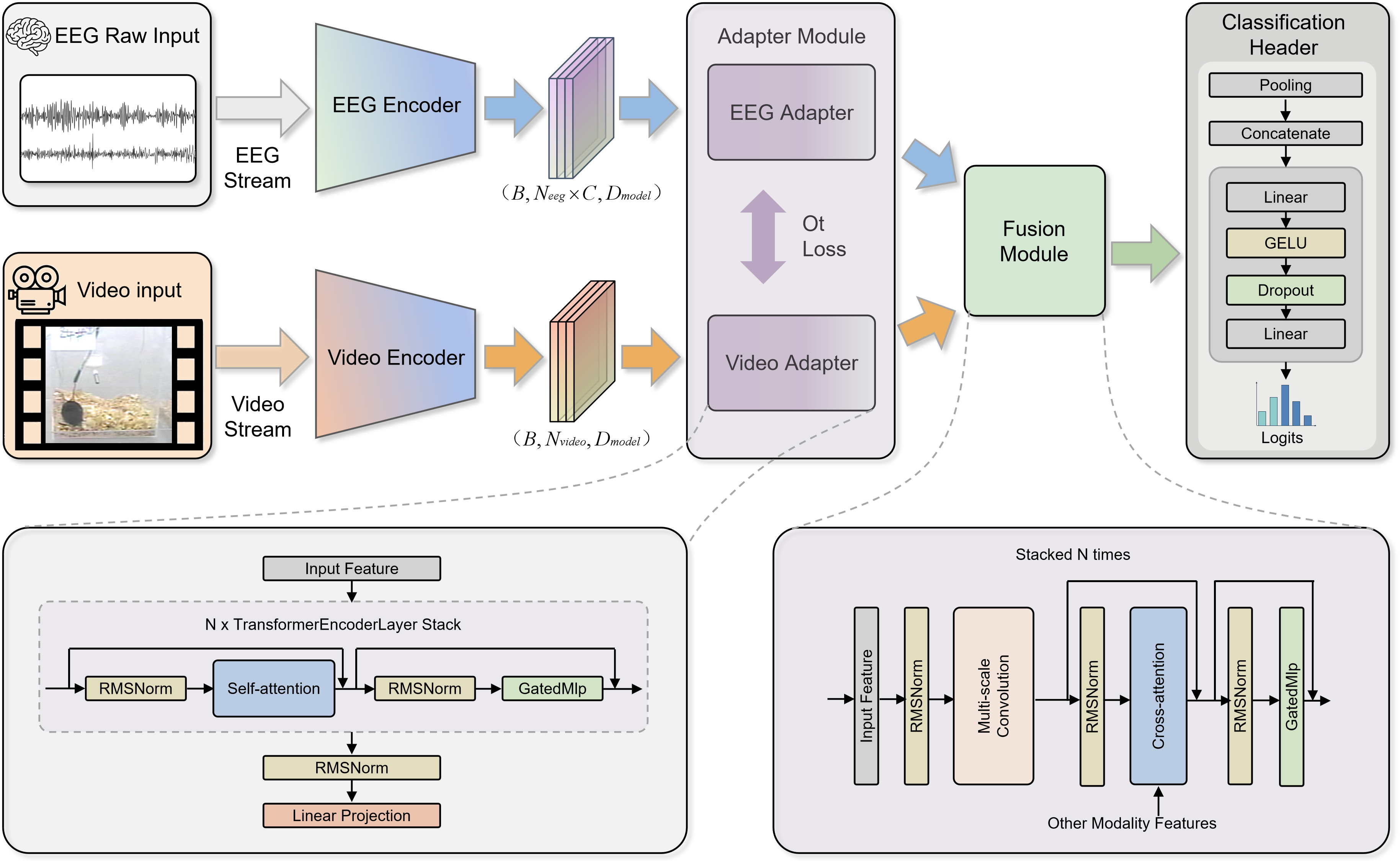
Figure 5: EEGVFusion architecture: parallel EEG and video encoders, cross-modal adaptation, optimal transport alignment, and bidirectional cross-attention for robust fusion and classification.
Cross-modality adaptation was performed by projecting each modality into a shared latent space, followed by an optimal transport (OT) alignment module. This module estimated a transport plan to minimize the distributional gap between neural and visual tokens, with the alignment error contributing explicitly to the multimodal loss during supervised training:
Ltotal=LCE+LOT
Feature integration was further refined via multi-scale temporal convolutions and bidirectional cross-attention, facilitating contextual evidence exchange—mitigating the failure modes that arise when one modality is unreliable.
Temporal Aggregation and Event-Level Decision
Fused outputs were aggregated and classified using a gated MLP head. Postprocessing harmonized model outputs to standardized event-level predictions via merging and duration heuristics, permitting direct performance comparisons at clinically relevant temporal scales.
Experimental Results
EEGVFusion demonstrated compelling improvements over established baselines. In the random-session split, it achieved a Balanced Accuracy of 0.9957, perfect event sensitivity, and an Event FAR of 0.625 FP/h, outperforming leading convolutional and attention-based models on all axes.
In the more challenging held-out-subject evaluation, EEGVFusion delivered a Balanced Accuracy of 0.9718 and reduced Event FAR from 2.7250 to 0.4833 FP/h compared to its EEG-only ablation, with event sensitivity remaining perfect in both cases.
Ablation (e.g., removal of EEG pre-training or OT alignment) consistently raised false alarm rates, confirming the complementary utility of each architectural component.
Feature Space Analysis
t-SNE visualizations confirmed that multimodal fusion yields superior cluster separation between seizure and non-seizure states, compared to unimodal encoders.
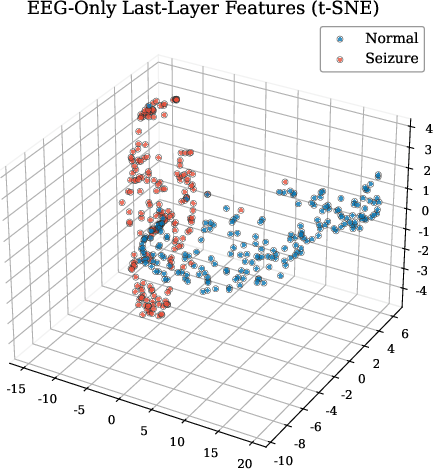
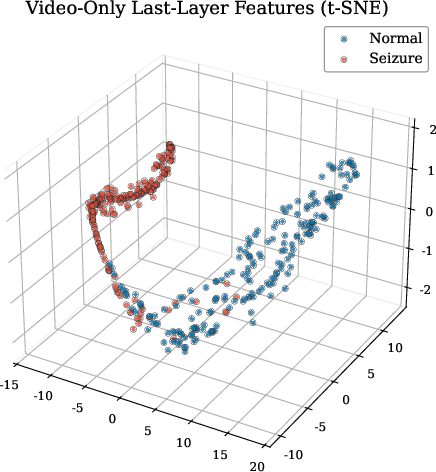
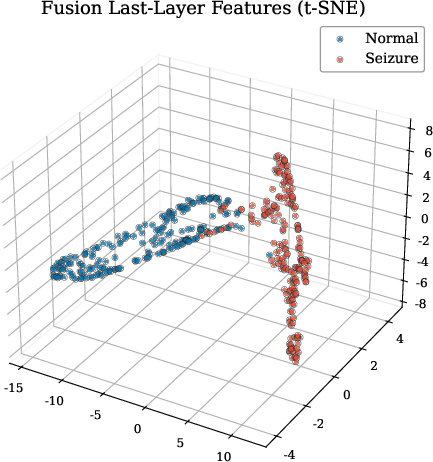
Figure 6: t-SNE projections of penultimate layer representations: fusion yields enhanced discriminability absent in unimodal spaces.
Generalization
Secondary experiments on the EAV emotion recognition corpus indicated strong transfer potential: EEGVFusion achieved 0.8139 average accuracy, outperforming single-modality and recent state-of-the-art fusion baselines, further reinforcing the versatility of the architecture.
Theoretical and Practical Implications
The results substantiate that explicit multimodal fusion—optimized using domain-adapted self-supervised learning, OT alignment, and contextual cross-attention—is able to address the complementary noise signatures and artifact profiles of EEG and video. Notably, this framework does not simply trade sensitivity for specificity or vice versa, but advances both simultaneously, particularly minimizing false alarms, a key metric for scalable long-term deployment.
From a methodological perspective, ablations demonstrate that (1) self-supervised MAE pre-training is essential for in-distribution robustness and sample efficiency on highly imbalanced event data, and (2) OT-based feature alignment is critical for suppressing spurious detections in multiday preclinical contexts, especially under moderate subject shift.
In practice, the reduction in false alarms translates directly to substantial savings in manual expert review for long-duration experiments. The generalization results suggest potential for cross-domain behavioral time series integration beyond seizure research, subject to further validation.
Limitations and Future Directions
While the dataset curation and annotation protocols are rigorous, class imbalance remains severe, and generalization beyond the tested hippocampal model and dual-channel montage warrants further study. Complete leave-one-subject-out validation, extension to other pathophysiological models (e.g., focal vs. generalized seizures), and adaptation to broader recording infrastructures are necessary for full deployment. Additional fusion strategies and formal quantification of OT alignment strength across domains represent meaningful theoretical avenues.
Conclusion
EEGVFusion establishes a highly effective multimodal integration pipeline for rodent seizure detection, leveraging self-supervised EEG representation learning and robust video encodings, novel OT-based alignment, and cross-attention fusion. The framework achieves state-of-the-art event-level sensitivity and minimizes false alarms, supporting its adoption for large-scale, scalable preclinical epilepsy monitoring. Broader applicability to cross-domain behavioral time series analysis is promising but will require continued architectural and empirical refinement.

