- The paper demonstrates a novel coupled optimization approach leveraging Camera-Invariant Semantic Anchoring and Global Style Diversification to mitigate semantic-style conflict in federated person re-ID.
- It shows improved mAP and Rank-1 performance over existing baselines, particularly robust on challenging domains even with imperfect metadata.
- The framework efficiently balances decentralized learning with privacy preservation by using lightweight statistical exchanges and prompt-based tuning.
CO-EVO: Co-evolving Semantic Anchoring and Style Diversification for Federated Domain Generalization in Person Re-ID
Introduction
Federated Domain Generalization for Person Re-Identification (FedDG-ReID) targets the deployment of robust ReID models across decentralized and heterogeneous camera networks while preserving data privacy. The central technical challenge arises from the semantic-style conflict: local models overfit to client-specific stylistic artifacts, leading to shortcut learning where non-transferable cues dominate over true identity semantics. The CO-EVO framework presents a coupled optimization strategy that addresses this conflict via two key mechanisms: Camera-Invariant Semantic Anchoring (CSA) and Global Style Diversification (GSD). CSA distills robust, domain-agnostic identity representations; GSD synthesizes realistic domain shifts, expanding the coverage of the learned feature space.
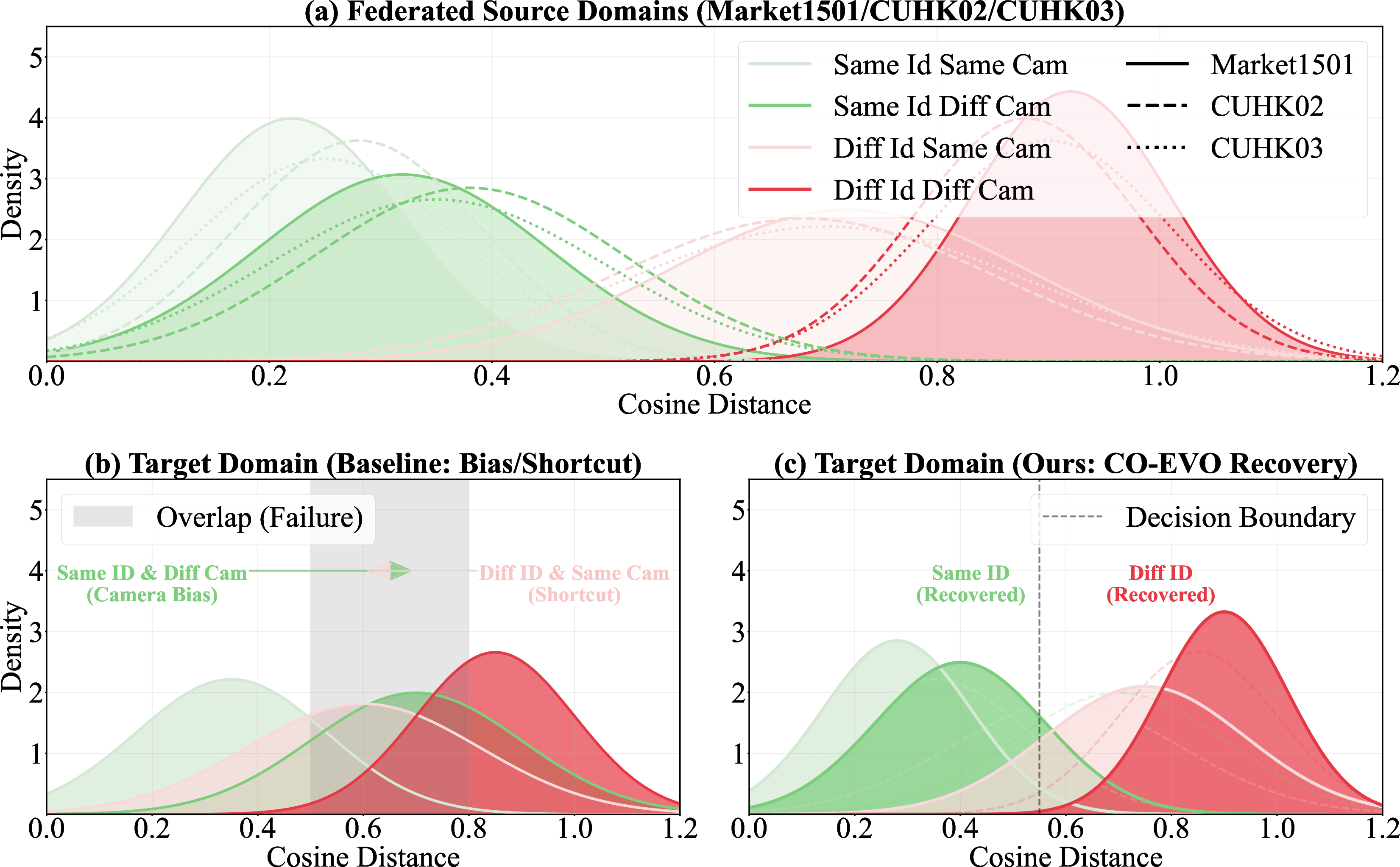
Figure 1: Cosine distance distributions illustrating the motivation of CO-EVO. (a) Source Training: Model learns identity discrimination under consistent source distributions. (b) Baseline Failure: On unseen target domains, camera bias and shortcut learning lead to distribution overlap. (c) CO-EVO Recovery: By coupling stable CSA with GSD, our framework restores the decision boundary.
Framework Architecture
CO-EVO operationalizes semantic-style synergy in a federated system. Each client node conducts a phase of language-guided optimization via CSA, producing purified identity prototypes robust to camera-induced semantic distortions. Subsequently, a subset of lightweight, global camera-style templates is aggregated into the GCSB—a bank of statistical photometric variations. During federated optimization, clients alternate between semantic alignment (anchoring visual features to static identity prototypes) and style diversification (sampling GCSB statistics for on-the-fly input perturbation). This coupled process compels the encoder to embed both original and stylized views into a unified, domain-invariant representation.
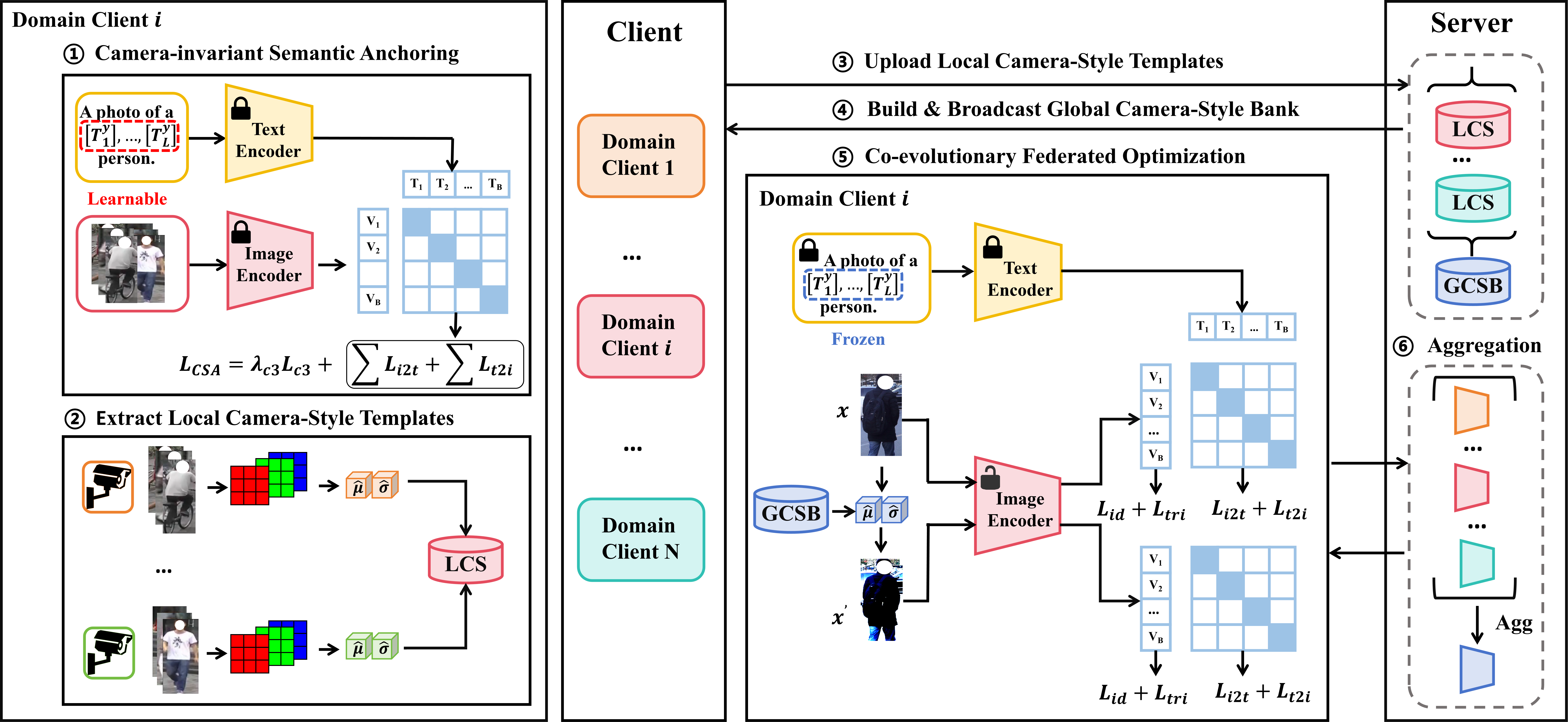
Figure 2: The overall architecture of CO-EVO for FedDG ReID, highlighting the six-step coupled semantic--style procedure and the global sharing of the camera-style bank.
Camera-Invariant Semantic Anchoring (CSA)
CSA leverages visual-language modeling for decentralized prompt tuning. For each identity y, a fixed-length sequence of learnable tokens is synthesized and used in a templated prompt, e.g., "a photo of a [X1y]...[XLy] person". During this anchoring phase, the image encoder remains fixed; only prompt tokens are updated. A bi-directional contrastive loss aligns visual samples and textual prototypes, while a cross-camera consistency regularizer (Lc3) maximizes agreement of features corresponding to the same identity but different camera IDs. This regularizer is essential—without it, semantic anchors absorb camera bias, destabilizing cross-domain identity transfer. Local CSA prototypes are cached and subsequently serve as static gravitational centers throughout the coupled training loop.
Global Style Diversification (GSD)
GSD eschews parametric generative models in favor of template-based normalization. For each camera, channel-wise mean and variance statistics are extracted; these form the GCSB. Stylization occurs via re-normalization: original features are mapped to zero-mean, unit-variance, then rescaled/shifted using randomly sampled GCSB templates. This mechanism is computationally negligible (<0.1% training time per client) and requires only a single metadata exchange. GSD is specifically constructed to augment photometric variations—illumination, color temperature, and texture consistency—rather than geometric attributes.
Coupled Federated Optimization
Each federated round samples both original and GSD-perturbed views. The local loss aggregates an identity cross-entropy, triplet ranking, and semantic alignment against the static CSA anchor. CSA ensures semantic drift is precluded even under aggressive style perturbations. After each round, parameter averaging and GCSB synchronization propagate updated models and augmented camera-style statistics across nodes.
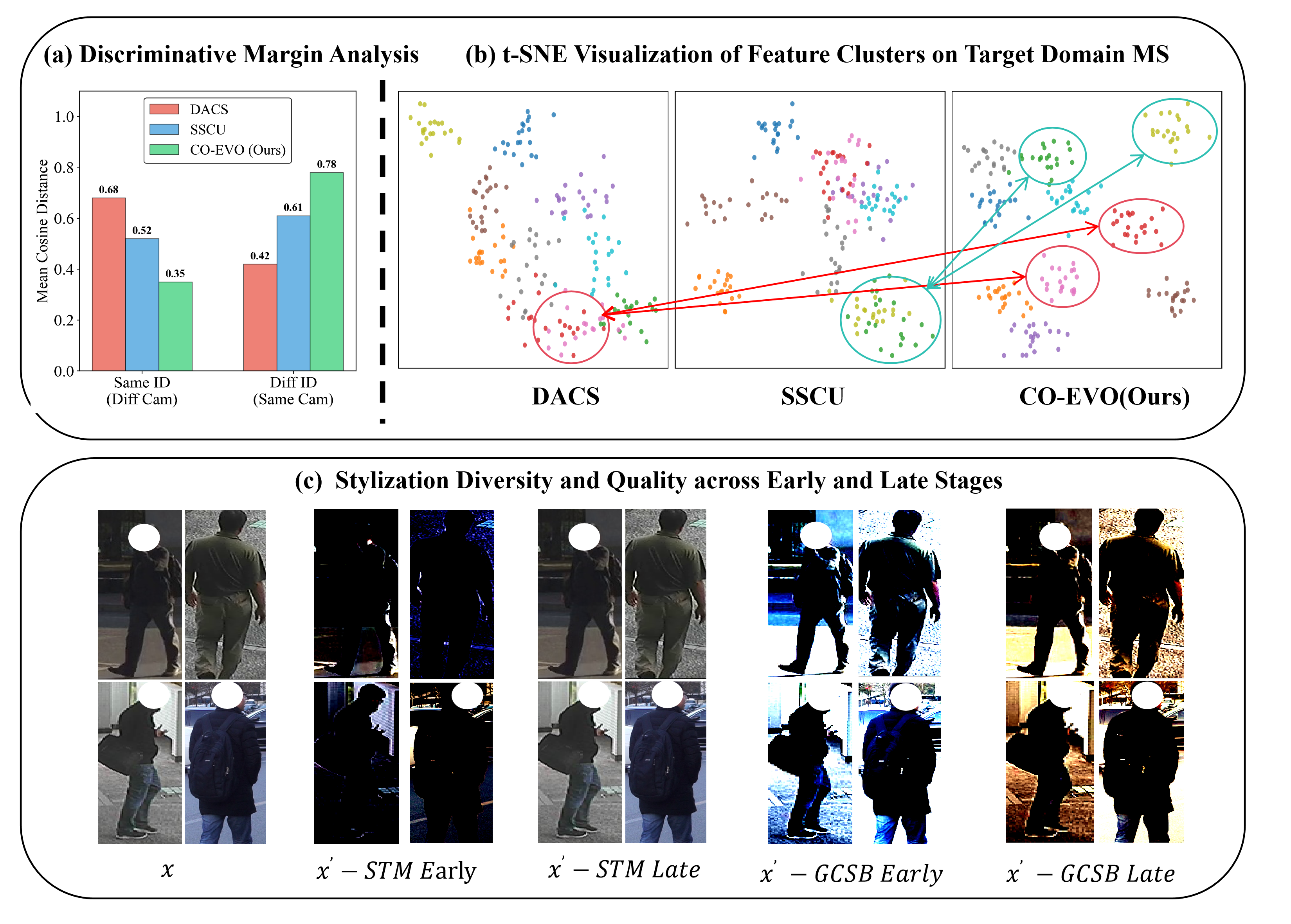
Figure 3: (a) Discriminative Margin Analysis: mean cosine distance improvements. (b) t-SNE on MS target domain: CO-EVO yields compact, separable identity clusters. (c) Stylization Diversity and Quality: GSD maintains diverse and realistic synthetics compared to baseline STM.
Experimental Results
CO-EVO achieves strong empirical results across three challenging protocols. In a leave-one-domain-out setting (Protocol I), it attains 2.0% mAP / 3.0% Rank-1 gains over the best previous baseline (SSCU), with stronger gains on more challenging domains (e.g., MSMT17). Robustness holds under varying numbers of source domains (Protocol II) and, importantly, CO-EVO maintains high discriminability on source domains themselves (Protocol III). Notably, CO-EVO remains robust under imperfect and missing camera metadata; style diversification via pseudo-grouped statistics via k-means still outperforms baselines that use gold labels. Ablations confirm that both CSA and GSD are critical—removing either causes substantial collapse, and maximal performance is only achieved when both operate in tandem.
Semantically, CO-EVO improves the inter-class margin and reduces intra-class scattering under strong style perturbation, as demonstrated quantitatively by cosine margin analysis and qualitatively by t-SNE projections. The GSD module outperforms generative STM systems in both diversity and artifact suppression over the course of training.
Implications and Future Directions
CO-EVO positions static, purified identity prototypes as foundational components for distributed, robust ReID systems. Its style diversification mechanism, leveraging non-learned, real-world style statistics, is attractive for privacy-sensitive and compute-constrained federated environments. The framework is agnostic to backbone (ResNet, ViT) and resilient to unreliable metadata—a strong fit for real-world deployment scenarios featuring heterogeneous, decentralized observational data.
From a theoretical standpoint, the framework underscores the utility of disjoint, decoupled optimization of semantic and stylistic features in mitigating shortcut learning. However, limitations remain in capturing non-photometric shifts (e.g., viewpoint, heavy occlusion), and the absence of formal privacy guarantees for statistical metadata exchange suggests an avenue for secure aggregation or differential privacy integration.
Future improvements may focus on (1) integrating more expressive, invariant style representations (e.g., structure-aware normalization, self-supervised geometric cues), (2) formalizing privacy constraints for low-dimensional metadata sharing, and (3) extending the co-evolutionary framework to other heterogeneous, federated vision tasks.
Conclusion
CO-EVO establishes a robust solution to semantic-style conflict in FedDG-ReID by presenting a coupled semantic--style federation mechanism. Through static CSA anchoring and realistic GSD-based domain shifts, it achieves superior domain transferability without sacrificing source discriminability or efficiency. The demonstration of resilience to imperfect metadata and agnostic backbone support broadens its applicability for privacy-preserving, decentralized vision deployments. Open questions remain in addressing non-photometric shifts and privacy formalization; nevertheless, the principles of purified semantic grounding and structure-driven stylization set a precedent for future federated generalization research.
Reference: "CO-EVO: Co-evolving Semantic Anchoring and Style Diversification for Federated DG-ReID" (2604.26363).