- The paper introduces OCARM, a two-stage distillation framework that uses onboarding content to create a leakage-free, temporally aware teacher-student model for retention prediction.
- It employs a Hierarchical Attention Encoder and a Sequence Fusion Encoder to capture temporal dependencies and align representations without feature leakage.
- Experimental results on a large-scale dataset demonstrate significant improvements in AUC and GAUC, confirming OCARM's effectiveness in enhancing retention metrics.
Distilling Post-Conversion Content for Retention Modeling: OCARM Framework
Introduction and Motivation
Retention modeling is pivotal for the long-term growth of recommender-driven platforms, as it captures post-conversion user engagement more robustly than immediate response signals. In real-time bidding (RTB) advertising scenarios, the retention model’s prediction must be executed before the user returns and experiences any in-app content, rendering subsequent onboarding content inaccessible during the crucial bidding decision. However, empirical analysis highlights that onboarding content—user interactions and content consumption immediately after platform re-entry—embodies highly predictive signals for future retention. Training with these post-conversion features results in severe feature leakage, producing a distribution gap between training and deployment phases and ultimately undermining real-world performance.
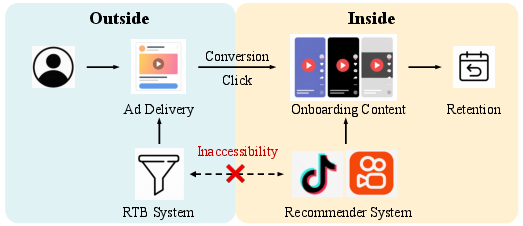
Figure 1: The temporal inaccessibility boundary in the user retention journey; bidding decisions occur before onboarding content is available.
OCARM: Two-Stage Distillation-Aligned Retention Modeling
To address the dichotomy between highly informative but inaccessible onboarding content and the necessity to prevent feature leakage, the OCARM framework implements a two-stage distillation strategy. Stage 1 deliberately introduces onboarding content as side information during training to learn a hierarchical, temporally aware encoding—serving as the teacher representation. Stage 2 then encapsulates the prediction model as a student, leveraging only observable features and learning to approximate the teacher’s onboarding content representation through representation-level distillation. The approach ensures that at inference, only permissible, pre-conversion features are used, effectively mitigating the distribution mismatch while benefiting from the implicit structure of future content consumption.
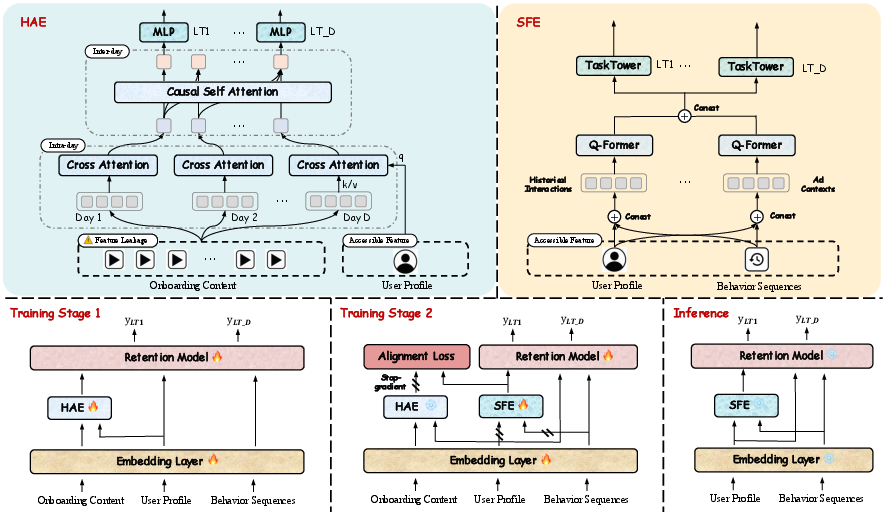
Figure 2: Overview of OCARM’s two-stage framework: Stage 1 generates teacher representations via hierarchical attention encoder (HAE) using leaked onboarding content; Stage 2 distills student representations from observable features for deployment.
Stage 1: Hierarchical Attention Encoder with Onboarding Content
The framework utilizes a hierarchical attention encoder (HAE) that exploits both intra-day and inter-day temporal dependencies within the multi-day, multi-event onboarding content sequence. By using cross-attention mechanisms conditioned on user profiling and causal self-attention across days, the model compacts onboarding interactions into semantically rich representations. This expressive onboarding encoding is tailored via task-specific towers for various retention horizons (e.g., LT1, LT7), and the associated representation is jointly optimized with retention prediction losses to maximize task alignment.
Stage 2: Sequence Fusion Encoder with Representation Distillation
The student network employs a Sequence Fusion Encoder (SFE), which processes observable user-side features—static profiles, historical interactions, and ad contexts—using cross-modal Q-Former modules to synthesize a unified user representation. Through distillation, the student optimizes a representation-alignment loss (e.g., cosine similarity) with the frozen teacher while simultaneously maintaining predictive supervision for the retention task. During deployment, only the student encoder and retention head are active; all computations are strictly leakage-free.
Experimental Evaluation
The framework's empirical evaluation leverages a large-scale industry dataset comprising millions of users and billions of interaction records gathered from a commercial short-video platform. Two principal prediction tasks, LT1 and LT7 (1-day and 7-day retention), are assessed using AUC and GAUC.
Quantitative offline analysis reveals that models trained with onboarding content (leakage enabled) establish a strong upper bound for retention prediction. When only the student (Stage 2) is used without prior alignment, performance deteriorates—attributed to unstable or collapsed representations in the absence of a robust teacher. The full OCARM pipeline, which first learns high-quality teacher representations then distills to the student, achieves clear and consistent improvements over baseline models lacking access to onboarding content.
Architecture ablations show progressive gains: simple MLP encoders (both teacher and student) underperform, while replacing with HAE for the teacher and SFE for the student yields the strongest lift, confirming the necessity of expressivity and alignment in both encoders.
A critical mechanistic observation is the positive monotonic correlation between the similarity of user and onboarding content representations and the retention prediction performance. As the model better aligns user-side estimations with teacher-provided representations (manifesting higher similarity), it more effectively bridges the inaccessibility gap, directly improving retention metrics.
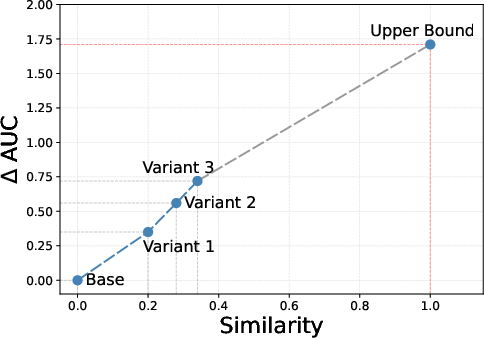
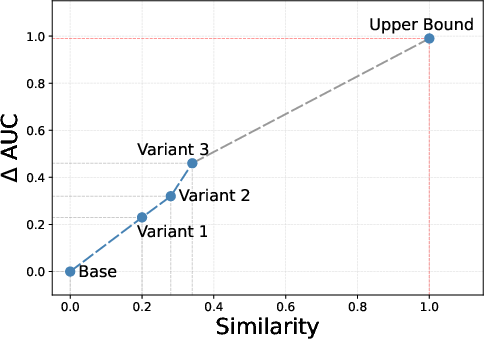
Figure 3: Performance improvement of retention prediction as a function of increased representation similarity—demonstrating that better distillation translates into stronger retention gains.
Online Deployment and Practical Implications
A/B tests conducted in a live industrial RTB system demonstrate that OCARM yields significant improvements in re-engaged device rates and long-term retention, most notably for previously uninstalled user cohorts. This result underscores the framework's efficacy in addressing user segments with inherently low re-engagement probabilities. The approach establishes a practical path for leveraging post-conversion signals without incurring feature leakage in real-world applications, operationalizing the synergy across growth and recommendation systems.
Theoretical Implications and Future Directions
OCARM’s two-stage pipeline formalizes a strategy to approximate counterfactual and temporally unavailable information through latent space distillation. This paradigm, situated at the boundary of causal inference and deep representation learning, highlights the power of structured knowledge transfer even under strict feature visibility constraints. Future development may explore more fine-grained sequential and cross-domain distillation objectives, adaptive teacher-student dynamics, or reinforcement-informed supervisory signals—targeting the residual upper-bound gap revealed in current evaluations. Expansion into cold-start and multi-modal retention prediction pipelines represents another promising line of inquiry.
Conclusion
OCARM advances retention modeling by exploiting onboarding content as a latent teacher during training, aligning student models in the absence of explicit post-conversion data. The methodology refines the boundary between feature exploitation and leakage prevention, yielding both robust offline lifts and significant online retention gains in production-scale systems. The framework delineates a new direction for distillation-based transfer in temporally constrained sequential modeling architectures.

