- The paper introduces efficient upcycling of dense models into sparse Mixture-of-Experts architectures, activating only ~5% of parameters per token for expert specialization.
- It employs a multi-phase curriculum over 5.1 trillion tokens to boost performance in both high- and low-resource languages, setting new benchmarks in efficiency.
- The open-source release and unsupervised expert routing demonstrate replicability and scalability, addressing multilinguality challenges without excessive compute.
Marco-MoE: Open Multilingual Mixture-of-Expert LLMs with Efficient Upcycling
Introduction
Marco-MoE establishes a new standard for open, efficient, and highly performant multilingual language modeling by leveraging Mixture-of-Experts (MoE) architectures with fine-grained expert specialization and an efficient upcycling methodology. The work addresses the inherent trade-off in scaling multilingual LLMs—broadening language coverage at fixed parameter budgets typically leads to diminished per-language proficiency, a phenomenon often termed the “curse of multilinguality.” Marco-MoE distinguishes itself by combining extreme sparsity (approximately 5% parameter activation per token), a rigorous multi-phase data curriculum encompassing 5.1T tokens, and full transparency of datasets, training recipes, and model weights.
The key methodological contributions are:
- The first sparse multilingual upcycling paradigm targeting compact models.
- Sub-matrix expert initialization, facilitating fine-grained specialization.
- Full open-sourcing, enabling replicability, scrutiny, and extension.
Sparse MoE Architecture and Upcycling Methodology
Marco-MoE adopts a decoder-only transformer, replacing traditional FFN layers with highly sparse MoE layers, following the conditional computation principle. The architecture is optimized for efficiency and specialization: Marco-Nano-Base (8B total/0.6B active) and Marco-Mini-Base (17.3B total/0.86B active) variants demonstrate the design, activating only a fraction of parameters per token. Fine-grained expert specialization is implemented via sub-matrix weight splitting, rather than coarse FFN replication.
The upcycling pipeline comprises three steps:
- Partitioning pre-trained dense FFN weights into multiple sub-matrices (pseudo-experts).
- Drop-Upcycling: stochastic re-initialization of select weight subsets, calibrated by empirical mean and variance.
- Weight scaling by N1/3 (number of experts per layer), stabilizing optimization and rectifying magnitude mismatches due to the gating mechanism.
This approach demonstrates rapid convergence and robust expert specialization, outpacing vanilla dense-FFN or coarse-grained MoE upcycling baselines.
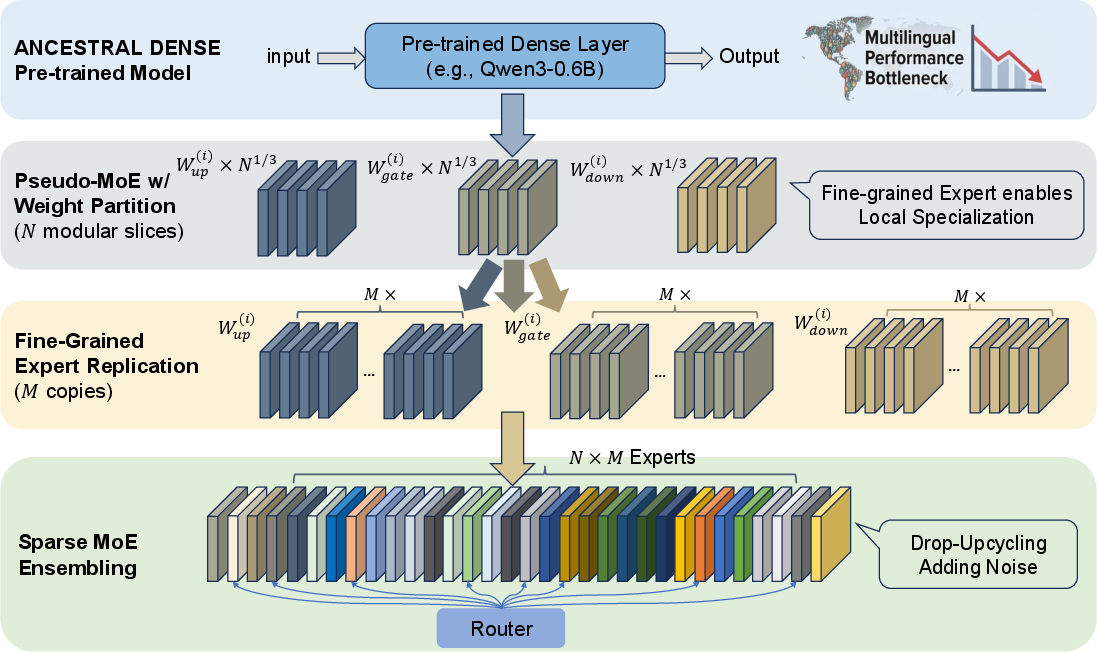
Figure 1: Fine-grained upcycling strategy from dense to MoE models, enabling efficient and specialized initialization.
Pre-Training Data and Curriculum
A multi-stage, language-diversifying curriculum is central to Marco-MoE's training efficiency. Four sequential phases progressively expand language coverage and emphasize reasoning and cultural data:
- Phase 1: High-resource languages, reasoned, and instruction data (2.4T tokens)
- Phase 2: Upsampling reasoning and Chinese; reducing English data (1.7T)
- Phase 3: Introduction of nine new medium-resource/low-resource languages (0.5T)
- Phase 4: Focus on curated synthetic/cultural multilingual data (0.5T)
Empirical evaluation shows that staged curriculum switching yields monotonic gains on English, general multilingual, and regional/cultural benchmarks, saturating only when the model approaches hardware or data constraints.
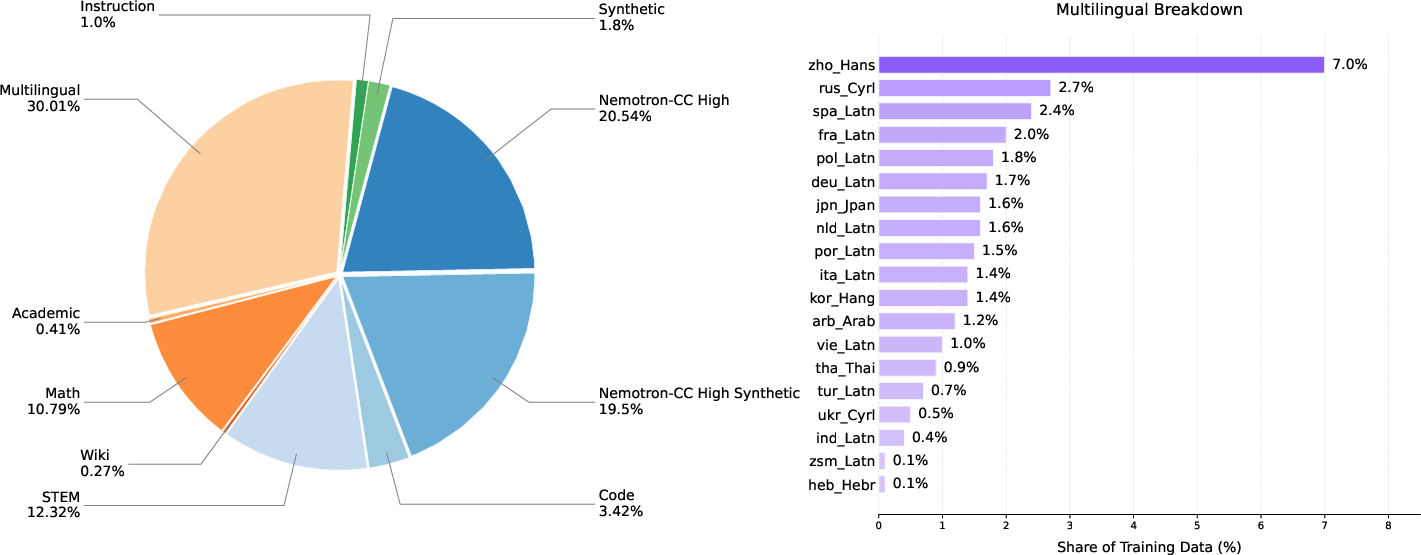
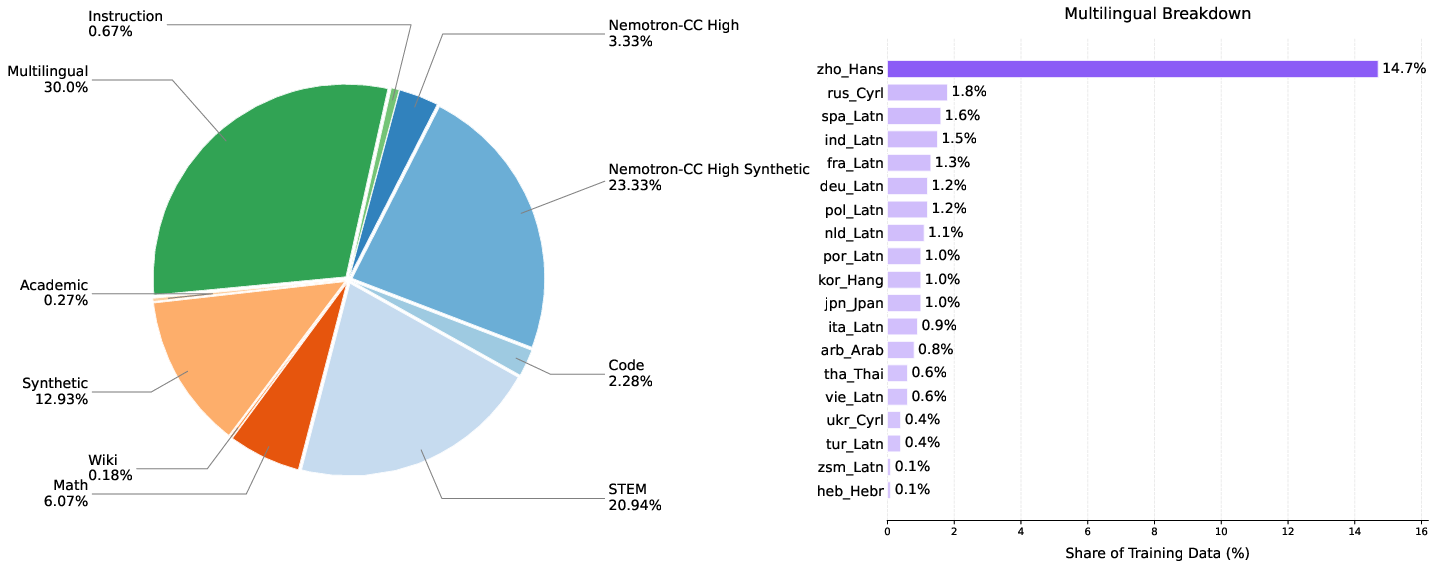
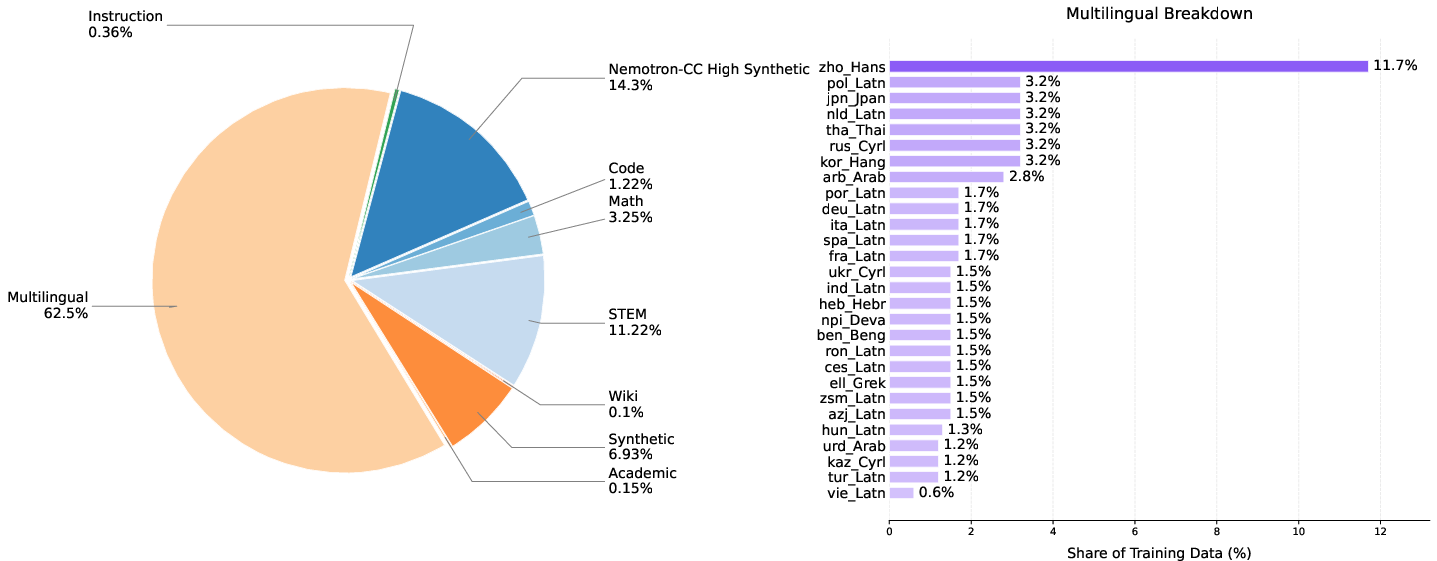
Figure 2: Evolution of data mixture ratios through pre-training phases, reflecting the shift toward broader and more specialized multilingual coverage.
Overall Results
Benchmarked against a suite of strong open-weight LLMs (Qwen3, Gemma3, Trinity, Granite4, Llama3.2, SmolLM3, Tiny-Aya), Marco-MoE models (both Nano and Mini) exhibit the following properties:
- Superior or state-of-the-art performance across English and multilingual tasks for their compute class.
- Robust gains as the number of active parameters increases, demonstrating smooth scaling.
- Outperformance of dense models with 3-14× more active parameters, especially on efficiency metrics.
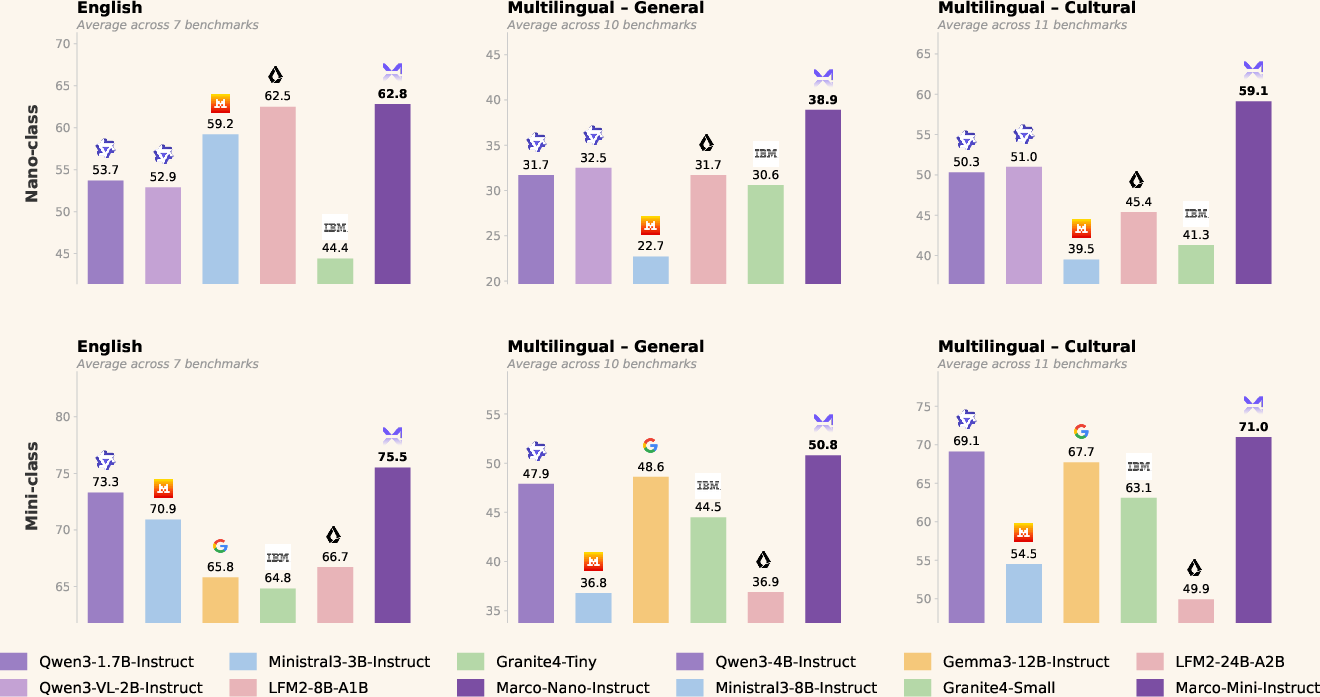
Figure 3: Marco-MoE-Instruct models outperform open-weight baselines on English, generic multilingual, and regional benchmarks, despite low parameter activation.
Efficiency and Scaling
Marco-Mini-Base (0.86B active) and Marco-Nano-Base (0.6B active) set a new efficiency frontier, dominating in performance-to-FLOP ratio. Notably, these models excel in long-tail and low-resource languages, with the performance gap increasing inversely with language resource availability.
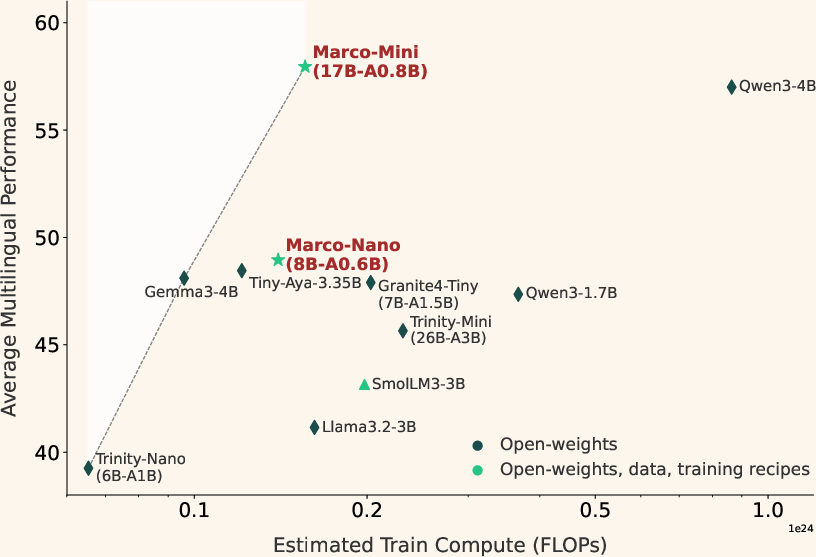
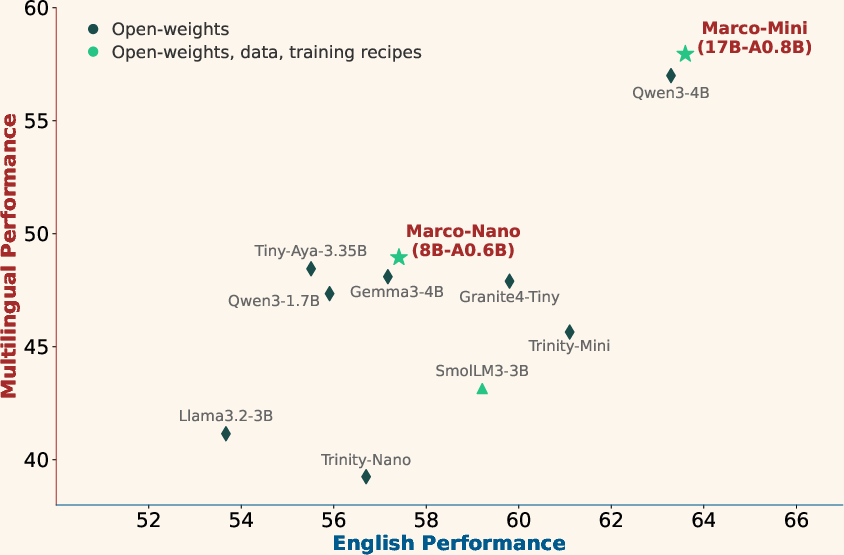
Figure 4: Performance-to-compute ratio (left) and simultaneous proficiency in English and multilingual evaluation (right) highlight superior scaling and generalization for Marco-MoE.
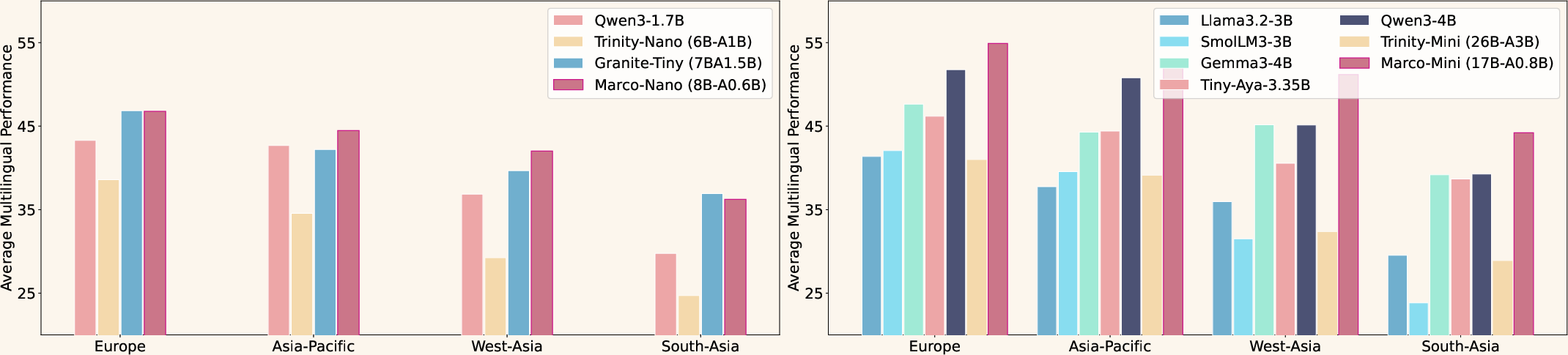
Figure 5: Geographic region-specific multilingual performance demonstrates Marco-MoE’s superiority, especially in resource-scarce language families.
Expert Routing, Linguistic Structure, and Language Scaling
Hierarchical analysis of expert activation signatures shows that the routing mechanism in Marco-MoE models strongly correlates with known language families. Cross-lingual transfer arises naturally for Romance, Germanic, Slavic, Austronesian, and Indic languages, whereas typologically isolated languages (e.g., Thai, Vietnamese, Arabic, Hebrew) induce unique expert pathologies—minimizing interference.
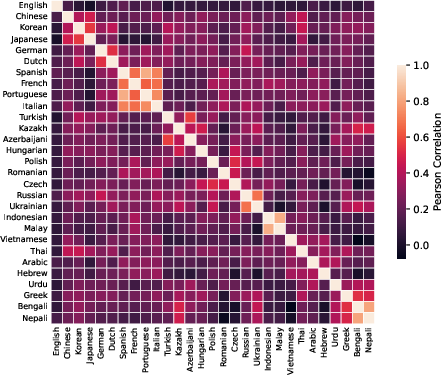
Figure 6: Language-labeled expert activation correlations demonstrate clustering by linguistically-related groups and specialization for isolated languages.
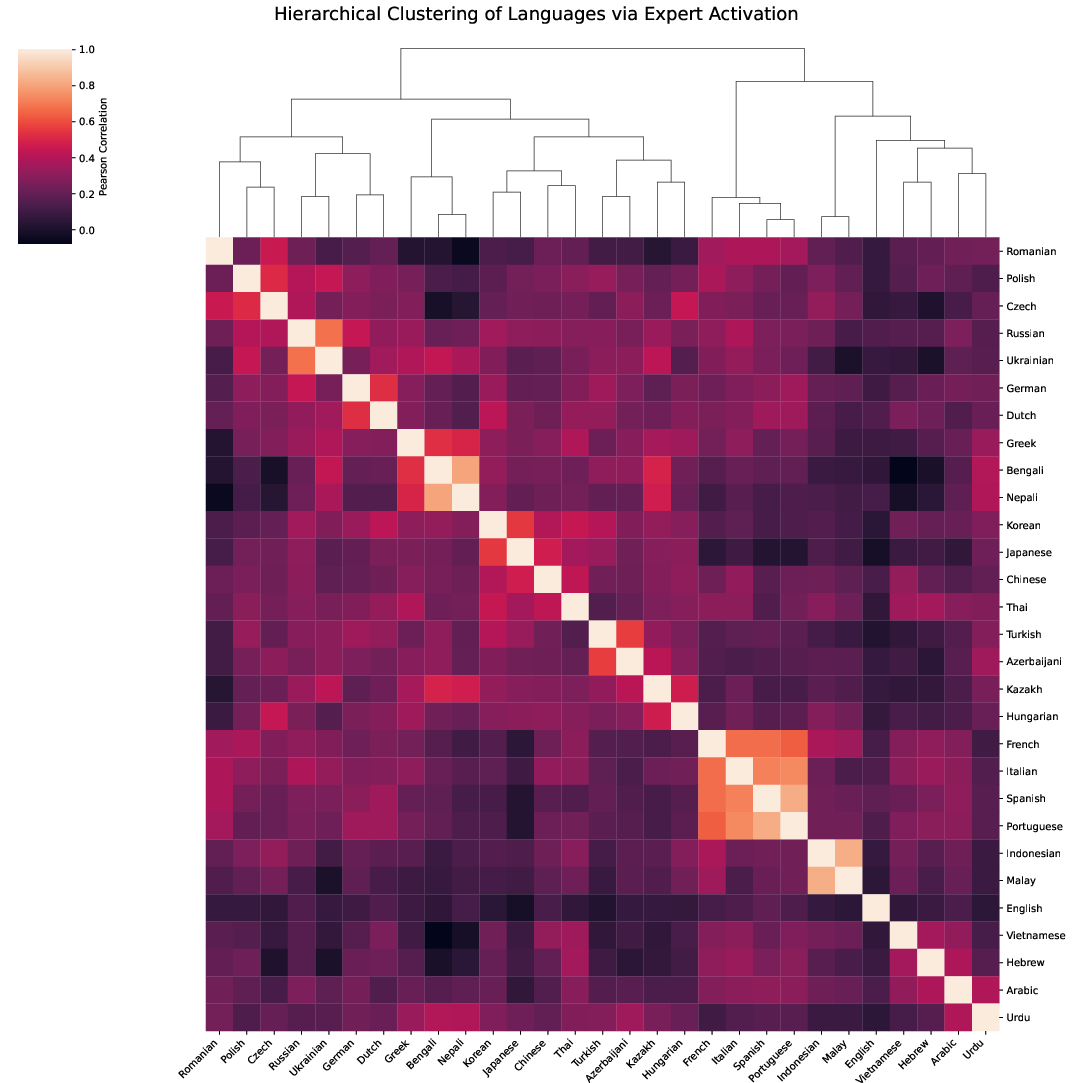
Figure 7: Hierarchical clustering of expert routing recovers canonical language families, illustrating unsupervised phylogenetic structure in routing patterns.
Further, the framework easily scales to 64 languages with consistent performance, with only a modest compute increase.
Post-Training: Instruction Tuning and On-Policy Distillation
Marco-MoE-Instruct models are produced via SFT on curated instruction, reasoning, and regional data, followed by cascaded On-Policy Distillation (OPD) from strong teacher models (Qwen3-30B, Qwen3-80B). OPD leverages trajectories sampled from the student’s policy, providing dense, high-signal updates that correct exposure bias and distribution shift inherent to SFT and vanilla off-policy distillation. This yields consistent incremental performance improvements for both general and cultural evaluation axes.
Open Research Implications
Marco-MoE's methodological openness—full data, recipe, code, and model weight release—enables reproducibility and broader scrutiny. The framework underscores MoE viability (especially fine-grained expertization and upcycling) as a path to defeating multilingual-capacity bottlenecks under constrained compute, rather than relying on massive-scale monolithic pretraining.
Strong empirical claims:
- Marco-MoE-Instruct matches or surpasses the real-world usability of state-of-the-art baselines, despite operationalizing orders-of-magnitude fewer active parameters.
- Structured expert routing trajectories inherently mirror typological language relationships without explicit supervision.
- MoE enables genuinely additive growth to language coverage—scalable to at least 64 languages—without destructive performance interference, as typically observed in dense LLMs.
Future Directions
Key avenues for further research:
- Extending Marco-MoE’s language reach into unseen, ultra-low-resource, or endangered language domains.
- Dynamic, modular routing or expert expansion for incremental language addition without full model retraining.
- Enhanced architectural or token-level routing mechanisms for efficient super-long input contexts and long-range dependency modeling.
Conclusion
Marco-MoE substantiates sparse fine-grained MoE architectures, upcycled from dense precursors, as a robust paradigm for efficient, open, and truly multilingual LLMs. Through architectural innovations, systematic multilingual dataset construction, multi-phase curriculum learning, and advanced distillation strategies, Marco-MoE sets a new practical and analytical benchmark in compact multilingual LLM research. By enabling community access to all components, it provides a reproducible foundation for ongoing expansion and scientific inquiry into high-performance, resource-efficient multilingual NLU.