- The paper introduces Fed-FSTQ, which uses token-level Fisher information to guide dynamic quantization and sparsification in federated LLM fine-tuning.
- It achieves a 46× reduction in uplink traffic and a 6.8× speedup per round while maintaining robust accuracy under non-IID data and packet loss.
- The method preserves semantically critical tokens, ensuring efficient and reliable model adaptation on resource-constrained edge devices.
Fisher-Guided Token Quantization for Federated On-Device LLM Fine-Tuning
Introduction and Motivation
The paper "FED-FSTQ: Fisher-Guided Token Quantization for Communication-Efficient Federated Fine-Tuning of LLMs on Edge Devices" (2604.25421) addresses the fundamental system bottleneck for deploying LLMs on mobile/edge devices in federated settings: uplink communication constraints. While Parameter-Efficient Fine-Tuning (PEFT) methods like LoRA enable adapting LLMs on devices with limited compute and memory, the repeated communication of model updates, especially under realistic non-IID data distributions and heterogeneous bandwidth, forms a straggler-limited bottleneck. Traditionally, quantization and sparsification alleviate this bottleneck via uniform or magnitude-based criteria, but such methods are agnostic to the semantic importance of token-level evidence—particularly problematic since rare but structurally critical tokens (e.g., negations, code delimiters) may require preferential retention for robust convergence and reliability.
Methodological Framework
The central contribution is Fed-FSTQ, a model-agnostic system primitive that leverages token-level Fisher information to inform both sparsification and mixed-precision allocation of uplink payloads during federated fine-tuning. The key insight is to repurpose lightweight token-level Fisher proxies (empirical squared input-embedding gradients) as a semantic saliency signal that quantifies structurally decisive evidence. This proxy is used to guide:
- Sensitivity-aware token selection via dynamic top-K masking, with exponential moving average smoothing to stabilize under stochastic gradient noise.
- Fisher-weighted rate–distortion optimization for bit allocation: coordinates with high Fisher-weighted update importance (i.e., high curvature and large delta) receive higher-bitwidth quantization (e.g., FP16), while low-importance coordinates are aggressively quantized (e.g., INT2) or pruned (b=0).
- Sparse uplink packing yielding low-overhead, bandwidth-efficient messages that are compatible with FedAvg-style server aggregation and require no server-side modification.
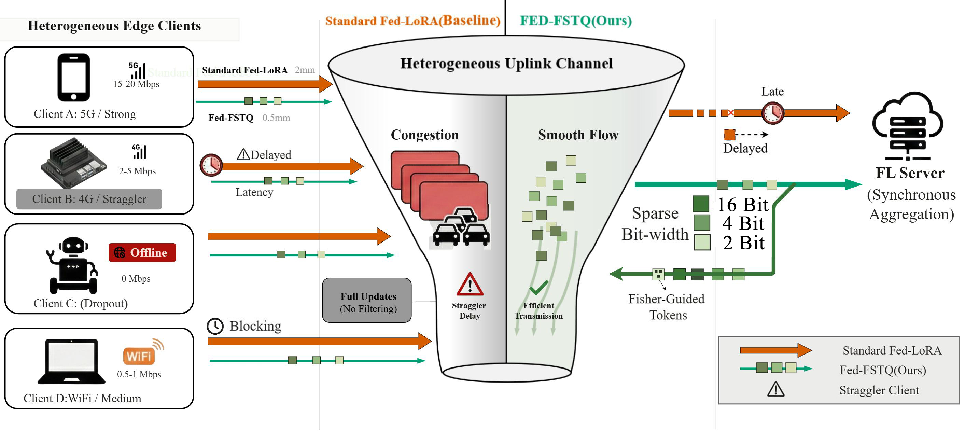
Figure 1: The uplink bottleneck in federated LLM fine-tuning; clients with poor Rk,t dominate round completion unless payload is aggressively and intelligently reduced.
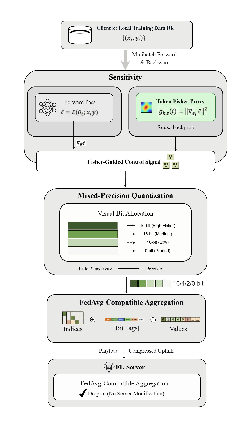
Figure 2: Fed-FSTQ system architecture: Fisher-guided sensitivity estimation, adaptive quantization, and sparse message formation on each client.
Communication–Accuracy Efficiency
Fed-FSTQ delivers a substantial improvement in the communication–quality Pareto frontier. Analysis shows that, to a fixed target validation accuracy (60%), Fed-FSTQ achieves a 46× reduction in cumulative uplink traffic relative to standard Fed-LoRA (LoRA atop FedAvg). This is not simply due to aggressive compression, but the semantic alignment between Fisher-weighted prioritization and preservation of critical, non-redundant update coordinates.
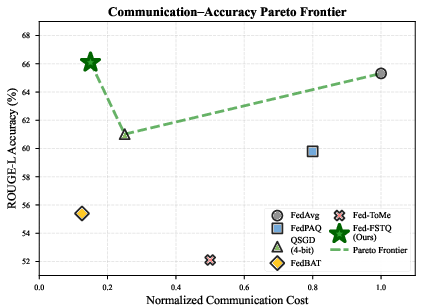
Figure 3: Communication–accuracy Pareto frontier: Fed-FSTQ achieves target accuracy with drastically reduced uplink.
Multilingual evaluation (e.g., Fed-Aya with Dirichlet-skewed clients in 8 languages) shows that communication cost is not only low, but also more balanced across structurally distinct languages—another indication of semantic robustness, particularly in low-frequency or information-dense scripts.
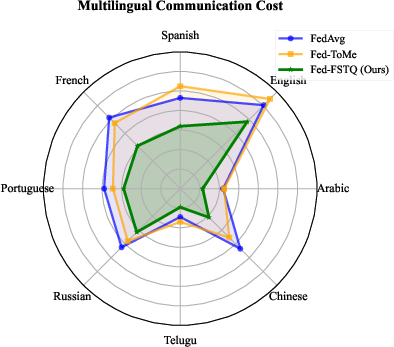
Figure 4: Multilingual communication cost radar chart; Fed-FSTQ remains balanced across language partitions.
System and Resource Efficiency
Despite the addition of token-level Fisher computation, per-round client overhead is minimal: an additional 0.85s client compute is offset by a 6.8× reduction in end-to-end round time (e.g., from 414.6s to 61.05s per round) when operating under realistic LTE uplink profiles. The overall wall-clock time-to-accuracy improves by 52% compared to Fed-LoRA, as the tail latency driven by straggler clients is sharply mitigated.
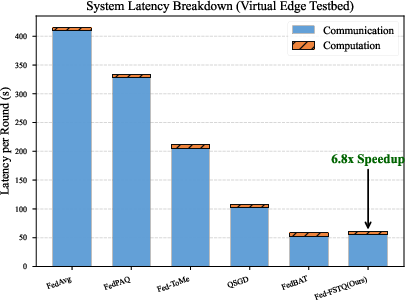
Figure 5: Breakdown of client round time: computation increases marginally but communication time plummets with Fed-FSTQ.
Battery and energy analyses confirm that, across radio power envelopes (0.1–5 W), reductions in communication time drop total per-round client energy below 100 J, significantly lower than all baselines.
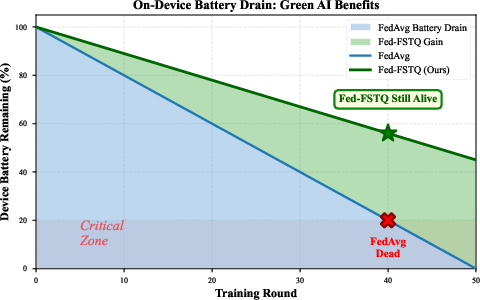
Figure 6: On-device battery drain is dominated by communication; Fed-FSTQ yields pronounced energy savings.
Furthermore, the approach is the only method tested that maintains a sub-2GB peak memory footprint, compatible with Jetson-class edge devices.
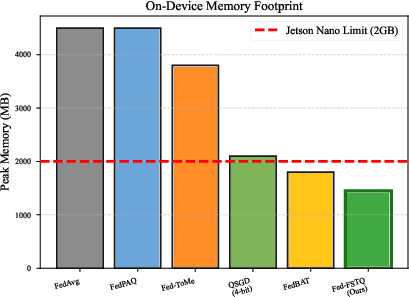
Figure 7: Fed-FSTQ remains deployable within the 2GB edge RAM limit, while baselines are excessive.
Robustness: Heterogeneity, Loss, and Scale
Fed-FSTQ displays unusual robustness under all forms of system and statistical heterogeneity:
- Under extreme non-IID partitions (Dirichlet α=0.1), Fed-FSTQ preserves high accuracy (0.51), surpassing FedAvg/PEFT (0.18) and QSGD (0.04).
- With packet loss rates up to 20%, accuracy drop (0.66 to 0.58) is much smaller than for FedAvg (0.65 to 0.34).
- Retains performance under severe client dropout regimes (up to 70% dropout, accuracy decreases by only 0.10).
- Scales well: time-to-convergence (hours) increases sublinearly with client count, significantly outperforming mainstream alternatives.
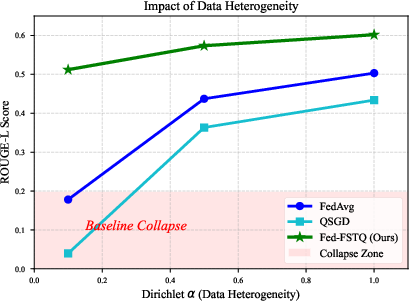
Figure 8: Fed-FSTQ stability under Dirichlet heterogeneity; sharp degradation in baselines absent.
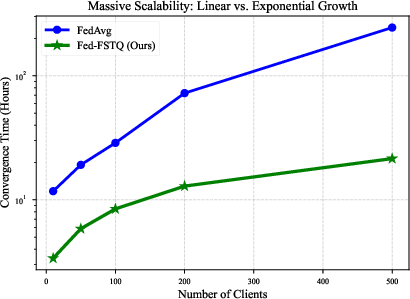
Figure 9: Time-to-convergence scales gracefully with the number of clients.
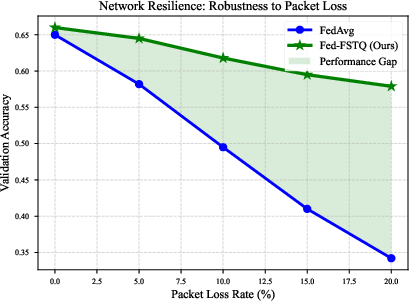
Figure 10: Uplink packet loss marginally affects Fed-FSTQ robustness.
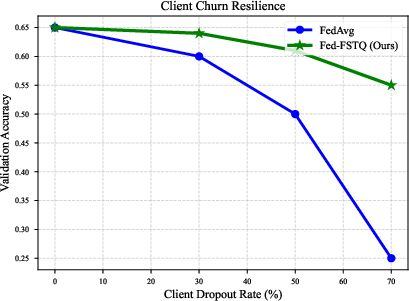
Figure 11: Graceful degradation under client dropout (partial participation).
Semantic Reliability and Integrity
A core differentiator is Fed-FSTQ's preservation of semantically relevant tokens. Compared to attention-driven or random compression, selected tokens overlap much more with those deemed critical in uncompressed references (Token Recall: 0.83 vs. 0.65 for attention heuristics). This translates directly to downstream performance—on medical QA (PubMedQA), Fed-FSTQ delivers state-of-the-art task metrics (ROUGE-L, METEOR, LLM-based judgements).
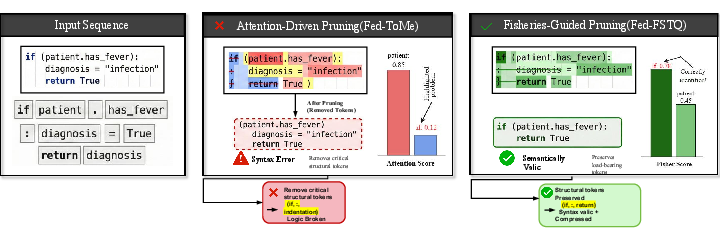
Figure 12: Fisher-based heatmaps identify structurally critical tokens missed by attention alone.
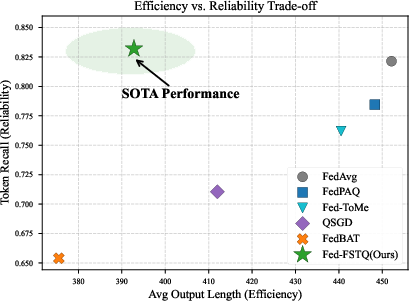
Figure 13: Efficiency–reliability trade-off: Fed-FSTQ achieves both high compression and high information retention.
Ablations and Design Study
Component ablation confirms Fisher-guided selection and adaptive bit allocation are essential; removing Fisher prioritization collapses quality (0.66 → 0.42 ROUGE-L at fixed payload), and disabling pruning/quantization inflates payload without meaningful quality gain. Token–parameter Fisher coupling was found to significantly accelerate convergence and improve accuracy under matched payload constraints, underscoring the need for semantic coupling during transmission, not just inference.
Implications and Future Work
Fed-FSTQ establishes Fisher-guided token sensitivity as a systems control primitive translating information-theoretic insights into practical communication and reliability gains for federated LLM adaptation on edge devices. The direct system-level impacts—substantially reduced wall-clock training time, improved energy efficiency, robustness to non-IID drift and network failures, and strict adherence to edge device constraints—support large-scale, privacy-preserving, cross-device learning for real-world applications (clinical, multilingual, code, etc.).
The theoretical implication is making curvature/sensitivity signals actionable not only for optimization (as in natural gradient or continual learning), but as part of a dynamic, locally computed resource allocation mechanism in large distributed systems. This may set the stage for further advances at the systems-algorithm interface, including extensions to asynchronous FL protocols and privacy-aware aggregation with integrated semantic control.
Conclusion
Fed-FSTQ introduces a robust, deployable, and model-agnostic communication primitive that respects both bandwidth constraints and semantic fidelity in federated LLM fine-tuning. The divergence from parameter-centric uniform compression to Fisher-guided, token-sensitive transmission enables both efficiency and reliability at scale. The approach is particularly relevant for future developments in mobile AI, where communication, privacy, and semantic adaptation intersect.