- The paper demonstrates that standard transformers trained with next-token prediction can learn a program interpreter for MicroPy, a minimal Turing-complete language.
- It employs dual training pipelines and PENCIL scaffolding to decouple time complexity from context length, achieving perfect execution on traces up to 7,552 steps.
- The results confirm compositional generalization and indicate that even modest transformers can emulate universal computation under explicit operational semantics.
Motivation and Problem Statement
The practical computational universality of transformer architectures has emerged as an active area of investigation, bridging theoretical expressiveness results with empirically demonstrated algorithmic learning. While recent work establishes that, in theory, transformers augmented with chain-of-thought-style (CoT) intermediate computations can simulate arbitrary Turing machines provided sufficient context and depth, there is limited empirical evidence that gradient-based training endows transformers with actual universal computational ability. This study addresses the critical question: Can a standard, non-modified transformer trained only with next-token prediction, learn a program interpreter for a computationally universal language, and thereby act as a universal computer? (2604.25166).
MicroPy: Language Design and Execution Semantics
To facilitate rigorous evaluation, the authors introduce MicroPy, a minimal yet Turing-complete language. MicroPy supports recursive procedures, conditionals, and mutable state (modeled by object attributes), but its semantics are formalized using a small, finite set of retrieval and rewrite rules. Program execution is decomposed into repeated application of these rules, including lookups from procedure and expression dictionaries, stack-frame manipulations, environment and effect management, and local primitive evaluations.
An important design decision is to represent each MicroPy execution as a sequence of explicit, local, small-step rewrites, interleaved with retrievals of program or environment definitions. This explicitness allows training data to cover the entire rule space without requiring extensive enumeration of complex programs.
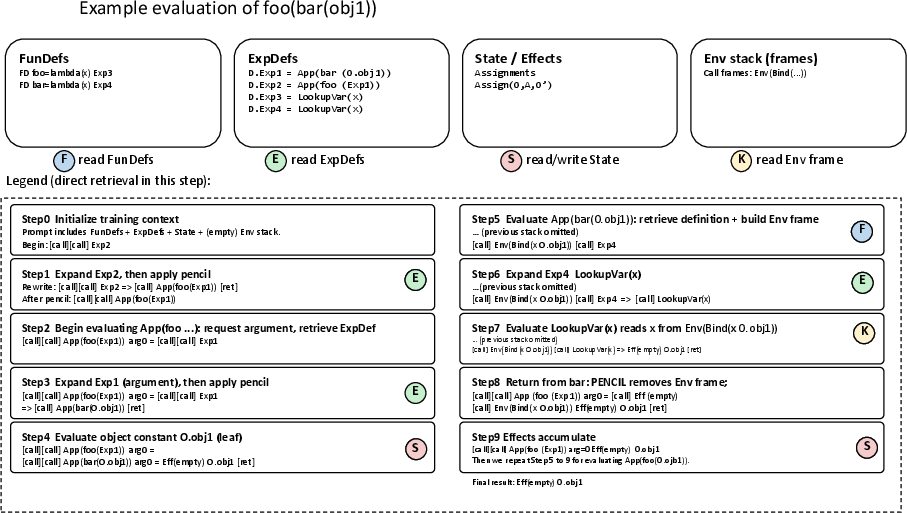
Figure 1: Evaluation of a MicroPy expression involves stepwise application of retrievals and rewrites, illustrated here with nested identity functions. Each step manipulates stack frames, environments, and object stores in a structured way.
PENCIL Scaffolding and Context Management
A practical barrier, both empirically and theoretically, is the context-length bottleneck: standard transformer CoT reasoning accumulates intermediate states linearly with the number of steps, quickly exhausting fixed context windows. To decouple task time-complexity from context length, the authors incorporate PENCIL scaffolding. This approach compresses completed computation traces—interpreted as nested [call]–[ret] blocks—down to their conclusions, bounding the necessary context by the space complexity of the computation rather than its time complexity.
This mechanism enables small transformers to correctly process and generalize to program traces far longer than those observed during training, as only a bounded working set needs to be maintained in context.
Data Generation and Training Protocol
Two complementary training data generation pipelines are implemented:
- Program Sampler: Samples full random MicroPy programs (procedure definitions and main expressions) from a generative grammar, running each to generate traces capped at 128 lines per program.
- Plan Sampler: Constructs targeted stack configurations by sampling planning skeletons that enumerate all possible combinations of retrieval and continuation shapes, ensuring full coverage of the MicroPy operational semantics.
Each training example is an explicit PENCIL rewrite, mapping context prefixes to their correct next step.
Model and Experimental Evaluation
A 59.5M-parameter decoder-only transformer (using RoPE positional embeddings) is trained with next-token prediction on the generated traces. The evaluation suite consists of held-out, human-written MicroPy programs spanning bitwise operations (copy, flip), arithmetic (binary addition, multiplication), and combinatorial search tasks (SAT verification and solving). Crucially, these test programs feature execution traces up to 7,552 steps—over 60 times longer than the training cap.
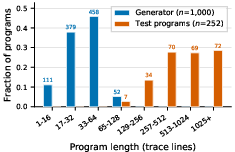
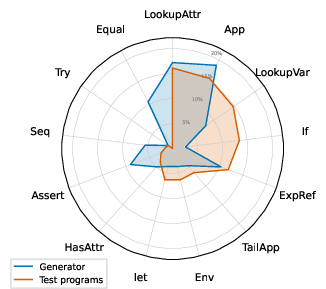
Figure 2: The plotted program length distributions show negligible overlap; training exposes the model only to short programs, while evaluation traces are much longer and substantially out-of-distribution.
The model achieves perfect (100%) stepwise prediction accuracy on all held-out programs within the context window. This demonstrates both compositional and strong length generalization, as the local rule set learned is sufficient to execute arbitrarily sampled, combinatorially complex computations over long unseen traces.
Analysis of Model Behavior
The authors provide further mechanistic insight through a suite of execution-step analyses:
- Leaf retrieval procedures (Figure 3) highlight operation-specific context manipulations (e.g., variable lookup from the current environment frame, attribute access from object state).
- Dictionary-backed expansions (Figure 4) clarify how function application and expression expansion rely on prompt-local program dictionaries.
- Control primitives and effect composition (Figure 5) illustrate the compositional combination of stack effects, as in sequencing, conditional branching, effect assertion, and equality test.

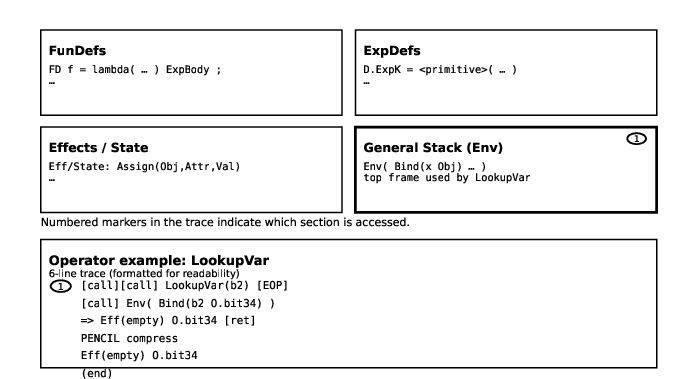
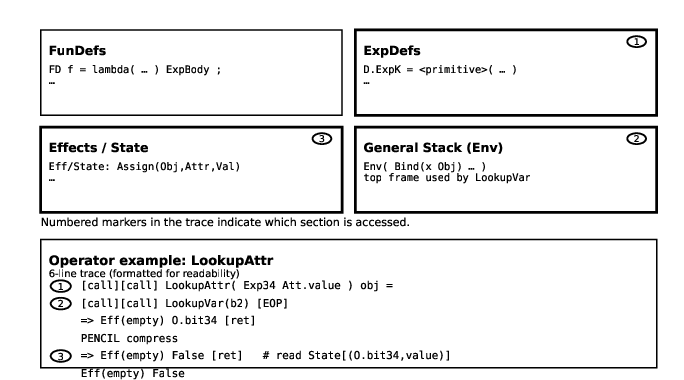
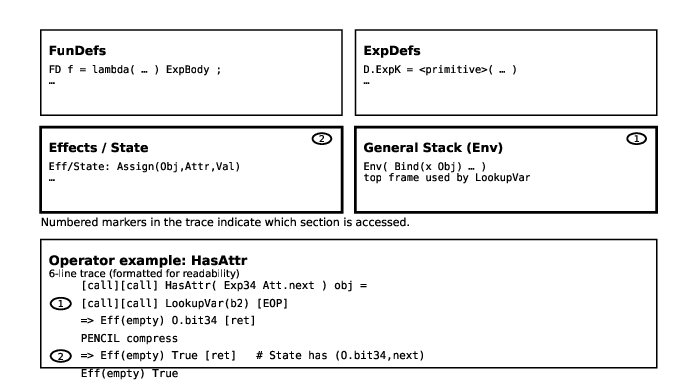
Figure 3: Leaf retrieval steps depend exclusively on the current (deepest) stack frame and the relevant dictionary or store.

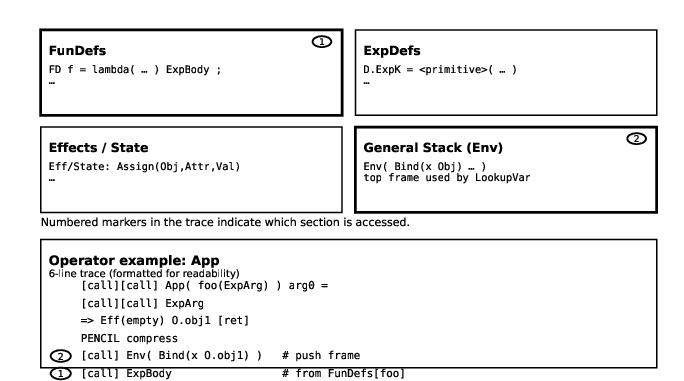
Figure 4: Dictionary-backed steps: expression expansion (left) and function application (right) attended via definition retrieval.




Figure 5: Control and effect composition: primitives such as Assert, Seq, If, and Equal form the backbone of program semantics.
Implications and Limitations
Theoretical Implications
The empirical demonstration that standard transformers can learn a program interpreter for a universal language—when exposed to the right mixture of rule-combinatorial training data and provided a scaffolding for space-bounded context reuse—closes a foundational gap between expressivity and learnability. These results reinforce the conjecture that context-managed transformer architectures implement a strong form of inductive bias for compositional, executable phrase structure, which is a cornerstone both of programming languages and the interpretation of natural language semantics.
Practical Implications
From a systems perspective, these findings indicate that autoregressive transformers, even with modest parameter budgets, can reliably act as neural interpreters for Turing-complete languages under explicit operational semantics and context management. Additionally, compositional generalization is shown to follow from local supervision and decomposition principles, not from memorization of specific program patterns.
Limitations
The main restriction is the fixed context window: while PENCIL scaffolding increases the effective working memory, trace length remains ultimately bounded. Additionally, the universality claim is made within the MicroPy formalism; extending to richer language features and more dynamic classes of programs remains an open challenge. Generalizing to program understanding and manipulation absent explicit execution traces is not directly addressed.
Future Directions
Prospective extensions include:
- Scaling to richer or dynamically scoped languages with higher-order features;
- Integrating external retrieval or long-term memory architectures;
- Training models to generate or analyze (rather than merely execute) programs from text;
- Empirical exploration of natural language generalization under analogous compositional scaffolding protocols.
Conclusion
This study delivers the first strong empirical evidence that a small transformer, using only next-token training and explicit context-window management via PENCIL, can be trained to act as a universal computer within a nontrivial programming language. Results demonstrate perfect generalization to out-of-distribution, semantically rich programs orders of magnitude longer than those used during training. The outcomes directly inform both the theory and practice of neural computation, compositionality, and program synthesis with contemporary transformer architectures.