WildLIFT: Lifting monocular drone video to 3D for species-agnostic wildlife monitoring
Abstract: Monocular RGB cameras mounted on drones are widely used for wildlife monitoring, yet most analytical pipelines remain confined to two-dimensional image space, leaving geometric information in video underexploited. We present WildLIFT, a computational framework that integrates three-dimensional scene geometry from monocular drone video with open-vocabulary 2D instance segmentation to enable species-agnostic 3D detection and tracking. Oriented 3D bounding box labels with semantic face information enable quantitative assessment of viewpoint coverage and inter-animal occlusion, producing structured metadata for downstream ecological analyses. We validate the framework on 2,581 manually curated frames comprising over 6,700 3D detections across four large mammal species. WildLIFT maintains high identity consistency in multi-animal scenes and substantially reduces manual 3D annotation effort through keyframe-based refinement. By transforming standard drone footage into structured 3D and viewpoint-aware representations, WildLIFT extends the analytical utility of aerial wildlife datasets for behavioural research and population monitoring.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper introduces WildLIFT, a computer system that turns regular drone videos (shot with a single normal camera) into 3D information about wild animals. It helps researchers find animals, follow them over time, and understand which side of an animal (left, right, front, back, top) the camera is seeing—all without needing special sensors or building a separate model for each species.
The main questions the researchers asked
- Can we use ordinary drone videos to recover 3D information about animals, not just flat 2D pictures?
- Can we track the same animal across many frames more reliably by using 3D positions instead of only 2D images?
- Can we label simple 3D boxes around animals and tag the boxes’ faces (front, left, top, etc.) to know which views we captured?
- Can we measure which viewpoints are well covered (for example, “lots of right-flank photos, almost no left-flank photos”) and when animals block each other?
How the system works (in simple terms)
Think of watching an animal while slowly walking around it. Even with one eye (one camera), because you move, your view changes and your brain can “build” a sense of 3D. WildLIFT does something similar with drones and video.
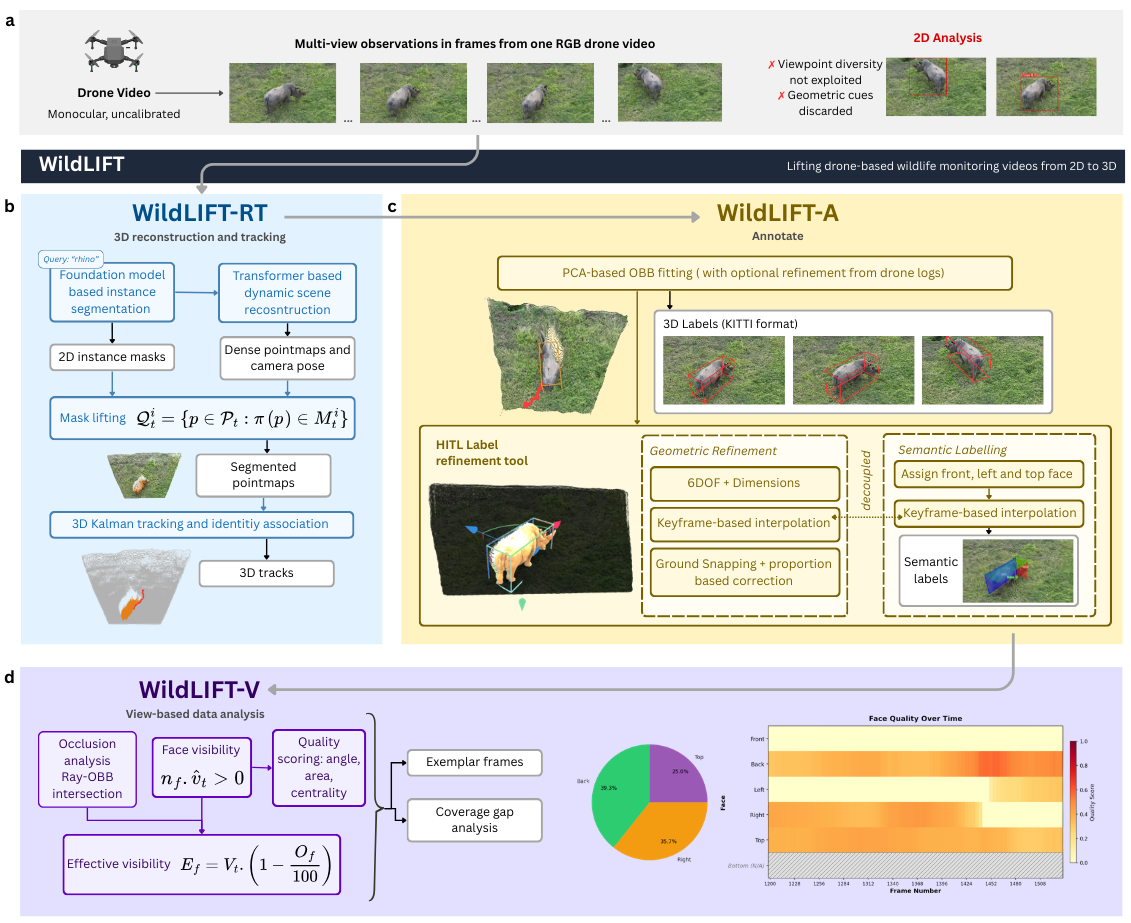
WildLIFT has three parts that work one after another:
- WildLIFT-RT (Reconstruct & Track): It:
- Finds animals in each frame using a “type what you want to find” detector. For example, type “zebra” and it highlights zebras without retraining a model.
- Rebuilds the scene in 3D by using many frames as the drone moves, like turning a flipbook into a pop-up book.
- Uses simple motion predictions (like guessing where something will be next based on how it’s moving) to follow the same animal over time, even if it disappears behind a tree for a while.
- WildLIFT-A (Annotate): It:
- Fits a 3D box around each animal. Imagine a shoebox snugly around an elephant or zebra. The box rotates to match the animal’s orientation.
- Lets a human quickly fix any mistakes by editing only a few “key” frames, while the computer fills in the rest smoothly.
- Labels the box faces (front, top, left). From those three, the system knows the other sides automatically.
- WildLIFT-V (View): It:
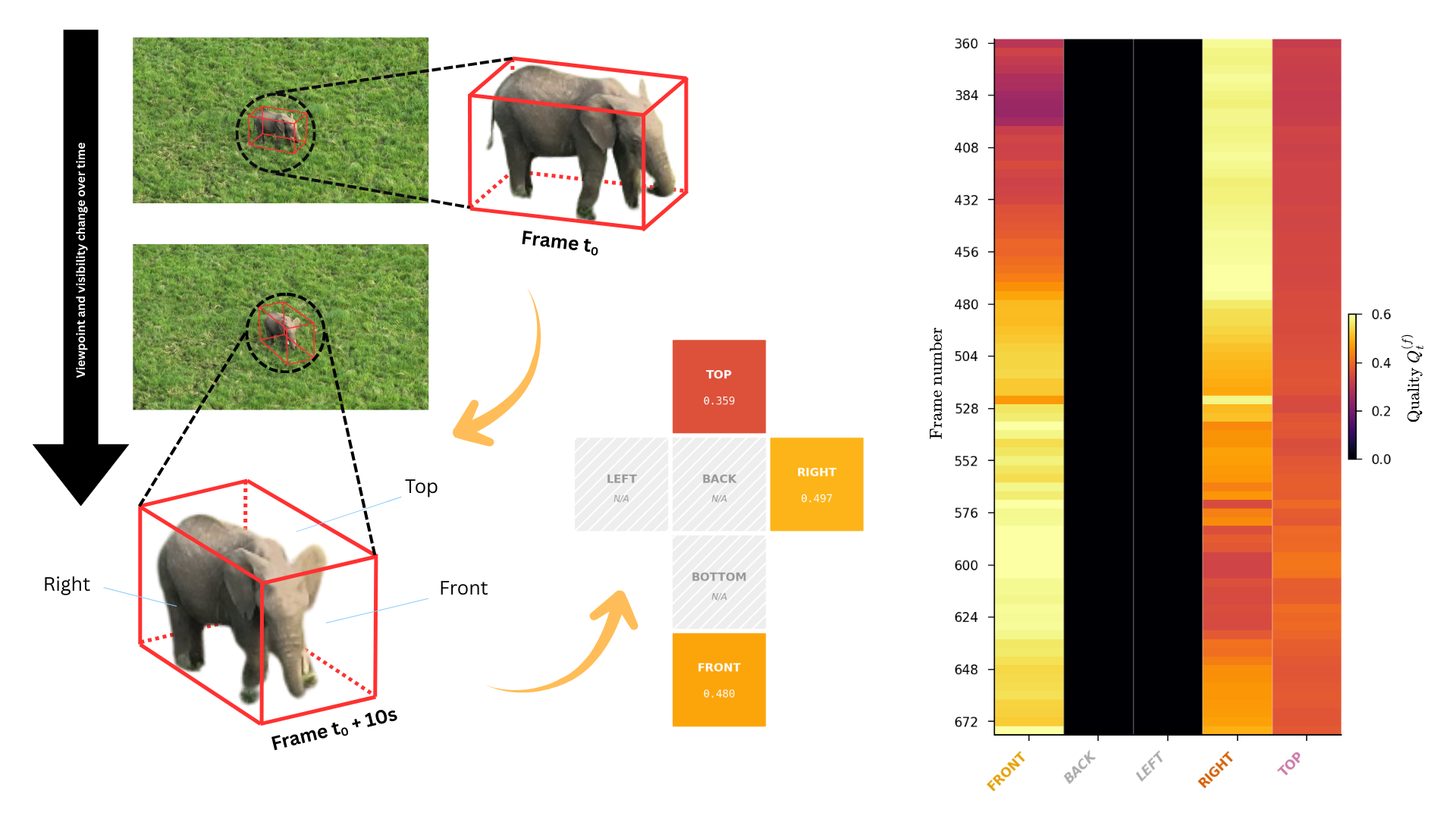
- Checks which side of the animal is facing the camera in each frame and how “good” that view is (is it centered, big enough, and seen at a clear angle?).
- Checks if another animal blocks part of the view.
- Summarizes coverage so researchers can quickly see if they have the right types of photos for identifying individuals (for example, right-flank shots for zebras).
What they found and why it matters
The team tested WildLIFT on 27 videos (2,581 frames) covering four species—rhinos, elephants, zebras, and giraffes—and got the following results:
- Better tracking by using 3D:
- WildLIFT kept perfect recall (it didn’t miss detections) and had very high identity consistency (IDF1 ≈ 0.982), meaning it was very good at keeping the same ID on the same animal across frames.
- It was especially strong when animals were hidden by vegetation for many frames. Because it uses 3D positions and motion predictions, it could “remember” where an animal should reappear and avoid mixing up identities when they came back into view.
- Fast, mostly automatic 3D labeling:
- The system’s automatic 3D boxes were accurate enough that people didn’t need to adjust them in 93% of frames.
- When edits were needed, users only tweaked about 2–3% of frames and the computer smoothed the rest in between. That’s a big time-saver compared to drawing boxes frame by frame.
- Clearer understanding of viewpoints:
- WildLIFT could tell which sides (front, back, left, right, top) were visible in each frame, with about 86–95% overall accuracy compared to human labels.
- It found real-world biases in footage. For example, in a zebra sequence, most views were of the right side, while front, left, or top views were rare or missing. This matters because some animal ID methods need specific sides (like the right flank) to recognize individuals.
- In multi-animal scenes, 15–40% of frames that looked “visible” were partly blocked by another animal, so the system also calculates “effective visibility” (clear line of sight).
In short, WildLIFT turns ordinary drone videos into rich 3D information that helps track animals reliably and quickly figure out which views were captured well.
Why this research is important
- Helps identify animals: Many species are identified by certain angles (like a zebra’s flank). WildLIFT shows exactly which views you have and which you’re missing, so scientists can plan better flights or pick the best frames.
- Saves time: Most 3D boxes are correct automatically, and only a few frames need editing. This makes creating training data for future AI tools much faster and cheaper.
- Works across species: Because it uses general 3D boxes and text-based detection (“find elephants”), it doesn’t need a special 3D model for each animal type.
- Useful for old videos: It works on regular videos already collected with consumer drones, so researchers can re-analyze existing footage in new ways.
Overall, WildLIFT makes drone wildlife videos much more useful for behavior studies, population monitoring, and building better future models—by lifting 2D footage into a structured, viewpoint-aware 3D world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains uncertain or unexplored in the paper and could guide future research.
- Metric scale and geo-referencing: The reconstruction is scale-ambiguous and unregistered to world coordinates. How can absolute scale and geolocation be recovered reliably (e.g., fusing GPS/IMU/altimeter, species-specific size priors, known-ground constraints) without sacrificing the species-agnostic goal?
- End-to-end detection robustness: The pipeline assumes open-vocabulary segmentation outputs but does not quantify detection precision/recall across habitats, lighting, and backgrounds or analyze prompt sensitivity. How robust is Grounded-SAM (or alternatives) in clutter, under camouflage, or with multiple similar species, and how do detection errors propagate to 3D tracking and viewpoint metrics?
- Multi-species scenes and class disambiguation: The framework targets a single prompted species per run. How to detect, separate, and track multiple species simultaneously and prevent cross-species identity swaps in mixed herds?
- Generalization across taxa and morphologies: Evaluation is limited to four large terrestrial mammals. Does the OBB abstraction and mask lifting hold for birds (wings), marine mammals (surfacing), small mammals, long-necked birds, or highly deformable taxa where box proxies are poor anatomical surrogates?
- Articulation and deformable appendages: PCA-based OBB fitting is sensitive to pose-induced shape changes (e.g., elephant trunks, giraffe necks). Can learning-based OBB regression, articulated proxies, or robust fitting with priors reduce heading flips and geometric skew under partial or deformable observations?
- Quantitative geometric accuracy: The paper reports acceptance rates and viewpoint classification accuracy but not metric 3D errors (e.g., position/orientation error of OBBs, camera pose drift) against ground truth. How accurate are trajectories and orientations, and what reference protocols (calibration targets, surveyed landmarks, known-size objects) are feasible in field settings?
- Backbone sensitivity and alternatives: CUT3R is adopted without a systematic comparison. How do different feed-forward backbones (e.g., VGGT, MonST3R) trade off consistency, drift, latency, and robustness to motion blur/low texture for aerial wildlife footage?
- Robustness to acquisition conditions: Performance degradation under rapid camera motion, motion blur, low-texture terrain (snow/sand/water), nadir views, or strong shadows is noted but unquantified. What operating envelopes (altitude, speed, FPS, shutter) maintain reliable reconstruction, detection, and tracking?
- Motion and association modeling: The constant-velocity Kalman model may fail under accelerations or abrupt turns. Can higher-order motion models, learned dynamics, or interaction-aware trackers improve identity consistency without overfitting to species-specific priors?
- Hybrid geometry+appearance tracking: 2D trackers with appearance cues slightly outperform geometry in close crossovers (e.g., zebras). Can a principled fusion of 3D geometry with re-ID embeddings yield best-of-both-worlds performance across species and scenarios?
- Long-horizon identity linkage: The approach re-identifies after intra-sequence occlusions of tens of frames, but linking across longer gaps, scene breaks, or separate flights is not addressed. What mechanisms (appearance priors, spatial-temporal priors, geo-tags) enable cross-clip identity stitching?
- Environmental occlusion modeling: Occlusion analysis considers only other animals’ OBBs. How to incorporate vegetation/terrain occluders (e.g., via ground plane, DEM, or environment meshes from reconstruction) to estimate effective visibility in cluttered habitats?
- Ground plane estimation and telemetry errors: Ground snapping and vertical-axis stabilisation rely optionally on gimbal telemetry. How robust are results to telemetry noise, and can ground planes be estimated reliably from pointmaps without external sensors?
- Viewpoint quality calibration and validation: Quality score components (angle, area, centrality, foreshortening) and thresholds are heuristic. Which weights/criteria best predict downstream utility (e.g., re-ID success), and can they be learned from human-judged exemplars?
- Real-time operation and closed-loop acquisition: Although CUT3R is online, latency/throughput for real-time use are unreported. Can viewpoint coverage feedback drive autonomous flight (e.g., active planning to fill coverage gaps) and what control policies achieve this safely?
- Uncertainty quantification: The pipeline outputs pointmaps, OBBs, and coverage scores without calibrated uncertainties. How can per-frame geometric and semantic uncertainties be estimated and propagated to viewpoint and occlusion metrics for risk-aware decision-making?
- Scalability and throughput: The paper notes modest VRAM needs but does not report runtime per frame, energy use, or batch-processing scalability. What are the performance profiles across hardware tiers, and how can the pipeline be optimized for large archives?
- Dataset breadth and openness: The evaluation uses 2,581 frames and 77 individuals. Will the authors release code, annotations (KITTI OBBs + face labels), and scripts to enable benchmarking, and what dataset scale/diversity is needed to train reliable supervised 3D wildlife detectors?
- Automatic semantic face labelling: Human-in-the-loop annotation is efficient but still required for face semantics and heading flips. Can head/tail or keypoint detectors automate semantic faces, and can temporal smoothing prevent label flips without manual intervention?
- End-to-end ecological impact: The viewpoint curation outputs are not empirically tied to gains in downstream tasks (e.g., higher re-ID match rates, improved mark–recapture estimates). Do coverage grades predict identification success across species, and by how much compared with 2D baselines?
- Cross-sequence scale alignment: Trajectories are internally consistent but not aligned across sequences. What strategies (GPS/IMU fusion, known-size priors, multi-flight bundle adjustment) enable consistent scaling and merging of tracks over multiple sorties?
- Dense-crowd and high-ego-motion regimes: Identity consistency is shown up to seven individuals and moderate occlusion. How does performance scale to larger herds, higher densities, or swarming behaviors with frequent crossings?
- Sensor/modal expansion: Can the framework leverage thermal/multispectral cameras (common in conservation) or multi-drone/multi-view data to improve detection under low light and reduce occlusions, while preserving the species-agnostic design?
- Ethical and operational constraints: The method’s effectiveness at altitudes and standoffs that minimize disturbance is not studied. What is the trade-off between altitude for animal welfare and the geometric fidelity required for reliable 3D lifting?
Practical Applications
Below is an overview of practical, real-world applications enabled by the WildLIFT framework’s findings, methods, and innovations. Each item notes sectors, actionable outputs/workflows, and key dependencies that affect feasibility.
Immediate Applications
These can be deployed now with the described pipeline and a standard GPU.
- Viewpoint-aware curation for photo-ID and cataloging
- Sectors: Conservation/NGOs, Academia (ecology/behaviour), Software/AI, Media
- What it enables: Automatically selects exemplar frames showing required anatomical profiles (e.g., left/right flank, front) and grades coverage to support identity pipelines for zebras, giraffes, whales, etc. Reduces manual triage and missed-ID risk due to suboptimal viewpoints.
- Tools/workflow: WildLIFT-RT + WildLIFT-A + WildLIFT-V; export “coverage vectors,” letter grades, and exemplar frame lists to existing photo-ID systems.
- Dependencies/assumptions: Adequate 3D reconstruction from monocular video (parallax, limited blur), accurate open-vocabulary segmentation for target species, OBB abstractions sufficiently proxy anatomical faces; absolute scale not required.
- High-fidelity multi-animal 3D tracking for behaviour budgets and movement studies
- Sectors: Academia, Conservation/NGOs
- What it enables: Identity-consistent tracks through occlusions and crossovers; improved group-structure quantification, inter-individual spacing (relative), and temporal event analysis with fewer ID switches than 2D trackers.
- Tools/workflow: WildLIFT-RT; track export to analysis notebooks (e.g., R/Python) for behaviour metrics.
- Dependencies/assumptions: Stable frame-to-frame geometry and detectable instances; absolute distances require scale calibration (e.g., altitude from telemetry or a known-size object).
- Semi-automated 3D dataset production for training detectors
- Sectors: Software/AI, Academia, Conservation tech startups
- What it enables: Rapid generation of KITTI-format 3D oriented bounding boxes (OBBs) from video with a 2–3% keyframe intervention ratio; bootstraps training corpora for future supervised monocular 3D wildlife detectors.
- Tools/workflow: WildLIFT-A browser tool for keyframe-based refinement; batch export of KITTI labels; integration with model training pipelines.
- Dependencies/assumptions: Quality of 3D fits depends on reconstruction and segmentation; HITL time still needed for semantic flips and occasional geometry fixes.
- Coverage and occlusion QA for survey planning and post-hoc audit
- Sectors: Conservation/NGOs, Policy/Protected area management, Consulting
- What it enables: Quantifies where/when individuals were visible and unobstructed; flags coverage gaps that warrant additional flight passes; produces QA metrics for reporting and reproducibility.
- Tools/workflow: WildLIFT-V’s quality scoring, occlusion tests, and entropy-based diversity indices; inclusion in survey reports.
- Dependencies/assumptions: OBB faces must align reasonably with animal profiles; segmentation and reconstruction quality impact visibility/occlusion reliability.
- Legacy video uplift: turning archives into 3D-structured datasets
- Sectors: Academia, NGOs, Media archives, Citizen science
- What it enables: Reprocess existing monocular drone footage into 3D tracks, OBBs, and viewpoint-aware metadata without new sensors; improves the scientific utility of historical collections.
- Tools/workflow: Offline batch runs on consumer GPUs (~6 GB VRAM); ingest via simple text prompts for detection.
- Dependencies/assumptions: Sufficient multi-view variation and video quality; performance drops with severe motion blur or very low texture.
- Media and editorial shot selection
- Sectors: Media/Documentary, Education
- What it enables: Automated selection of clips that best depict desired sides/profiles; saves edit time and ensures narrative continuity.
- Tools/workflow: Use WildLIFT-V’s exemplar extraction and quality heatmaps to assemble reels per viewpoint.
- Dependencies/assumptions: Same as viewpoint-aware curation; relies on consistent OBB-to-anatomy proxy.
- Livestock and ranch operations: herd-level monitoring from drones
- Sectors: Agriculture/Livestock, Agri-tech software
- What it enables: Species-agnostic tracking and viewpoint-aware frame selection for individual ID (ear tags/brands) and condition checks; efficient coverage audits after a flight.
- Tools/workflow: Run WildLIFT with species prompts (e.g., “cattle”); export exemplar frames for ID/health review.
- Dependencies/assumptions: Open-vocabulary segmentation must perform well on livestock domains; scale required for absolute body-size or spacing metrics.
- Compliance and safety checks (post-hoc)
- Sectors: Policy/Regulation, Operations/Field teams
- What it enables: Post-flight assessment of relative geometry (e.g., angle, proximity) to verify adherence to best-practice disturbance guidelines.
- Tools/workflow: WildLIFT-RT/V; generate compliance summaries with coverage grades and relative separation.
- Dependencies/assumptions: For absolute standoff distances, add scale via gimbal telemetry, drone altitude, or ground control; monocular recon is scale-ambiguous otherwise.
- Integration with geospatial workflows
- Sectors: Geospatial/Mapping, Conservation planning
- What it enables: Register 3D tracks to maps for habitat-use overlays and proximity to features (water, roads).
- Tools/workflow: Export tracks; import to GIS (e.g., QGIS) via GPX/GeoJSON after georeferencing.
- Dependencies/assumptions: Requires camera pose to world alignment (telemetry/SLAM-to-GPS alignment); without georeferencing, only relative coordinates are available.
Long-Term Applications
These require further development, scaling, or validation beyond the current paper.
- Real-time, closed-loop flight to “fill” viewpoint gaps
- Sectors: Robotics/UAS, Conservation
- What it could enable: Onboard WildLIFT-style tracking with live coverage metrics to autonomously reposition the drone for missing profiles (e.g., capture both flanks for every individual).
- Tools/workflow: Streaming inference, low-latency integration with flight controllers (e.g., WildWing), real-time coverage scoring and path planning.
- Dependencies/assumptions: Edge compute on the drone, reliable telemetry, and regulatory clearance for autonomy; robust performance under motion blur.
- Swarm-based multi-perspective coverage and occlusion minimization
- Sectors: Robotics/UAS, Field operations
- What it could enable: Cooperative drones plan vantage points to maximize face diversity and minimize inter-animal occlusion in herds.
- Tools/workflow: Multi-agent planning over per-drone coverage scores; inter-UAS communication.
- Dependencies/assumptions: Swarm-safe autonomy, spectrum management, site permits, and robust multi-view reconstruction under diverse baselines.
- Supervised monocular 3D wildlife detectors (no reconstruction at inference)
- Sectors: Software/AI, Conservation tech
- What it could enable: Training detection models directly in 3D using KITTI-format labels generated by WildLIFT-A, reducing reliance on reconstruction at deployment and enabling faster real-time systems.
- Tools/workflow: Large-scale labeled corpora, model training and benchmarking pipelines, domain adaptation across species/environments.
- Dependencies/assumptions: Need for broad, high-quality annotations; per-species diversity; standardized evaluation benchmarks.
- End-to-end identity pipelines leveraging 3D viewpoint linking
- Sectors: Conservation/NGOs, Academia, Software
- What it could enable: Combine WildLIFT’s viewpoint-aware selection with species-specific re-ID models to achieve bilateral completeness (e.g., both flanks) and raise match accuracy.
- Tools/workflow: API from WildLIFT-V into re-ID engines; rules to fuse multi-view matches.
- Dependencies/assumptions: Reliable re-ID models per taxon; consistent OBB face-to-anatomy mapping across poses.
- Population monitoring with scaled, georeferenced 3D metrics
- Sectors: Policy/Regulation, Conservation planning, Environmental consulting
- What it could enable: Density, spacing, and body-size proxies with uncertainty, feeding into standardized population estimates and EIA workflows.
- Tools/workflow: Add scale via telemetry/GCPs; automate QA/uncertainty reports; integrate with mark–recapture databases.
- Dependencies/assumptions: Accurate scale and georeferencing; validation studies across habitats and taxa; clear ethical/permits framework.
- Multi-modal sensing (RGB + thermal or depth) for low-visibility conditions
- Sectors: Robotics/UAS, Conservation
- What it could enable: Robust detection and 3D tracking under canopy/night via thermal fusion; improved occlusion reasoning.
- Tools/workflow: Sensor fusion modules extending WildLIFT-RT; calibration between modalities.
- Dependencies/assumptions: Added payload and power; calibration complexity; cost and regulatory constraints.
- Anti-poaching and real-time alerting
- Sectors: Public safety, Conservation enforcement
- What it could enable: Persistent 3D tracks of humans/vehicles and wildlife with intelligent alerts when risky proximity or pursuit trajectories are detected.
- Tools/workflow: Streaming 3D tracking + detection of human classes; geofenced alerts to rangers.
- Dependencies/assumptions: Connectivity, latency, false-positive management, ethical and privacy considerations.
- Extension to birds, marine mammals, and small-bodied taxa
- Sectors: Academia, Conservation
- What it could enable: Generalization beyond megafauna; adapt geometry (e.g., elongated bodies, wings, flexible shapes) and consider shape models or learned 3D boxes.
- Tools/workflow: Domain-specific evaluation, modified OBB parameterization or articulated models.
- Dependencies/assumptions: Adequate segmentation performance; new validation datasets; potentially higher frame rates and stabilized acquisition.
- Standards and policy for drone-based monitoring QA
- Sectors: Policy/Regulation, Standards bodies
- What it could enable: Institutionalize coverage grades, occlusion rates, and minimum data quality thresholds in permits and monitoring protocols.
- Tools/workflow: Publish open metrics schemas; reference implementations and audit tools based on WildLIFT-V.
- Dependencies/assumptions: Community consensus on metrics; regulator adoption; cross-site validation.
- Cloud platforms and services for automated 3D wildlife analytics
- Sectors: Software/SaaS, NGOs, Citizen science
- What it could enable: Upload videos, receive 3D tracks, labels, and coverage reports; optional HITL annotation marketplace.
- Tools/workflow: Scalable GPU backends; secure data handling; APIs for downstream apps.
- Dependencies/assumptions: Cost-effective compute, data governance, and funding models.
- Edge-optimized on-drone inference
- Sectors: Robotics/UAS, Hardware
- What it could enable: Low-power, low-VRAM implementations for long endurance flights and remote operations.
- Tools/workflow: Model compression, quantization, and efficient reconstruction backbones; hardware integration.
- Dependencies/assumptions: Performance–latency trade-offs; accuracy retention under compression; platform heterogeneity.
Key cross-cutting assumptions/dependencies:
- Reconstruction quality depends on sufficient parallax, limited motion blur, and scene texture; CUT3R provides consistency but is scale-ambiguous.
- Open-vocabulary segmentation must generalize to the target species; prompt design and potential fine-tuning may be needed for novel taxa.
- Absolute distances and geospatial analyses require scale and georeferencing (telemetry, altitude, ground control).
- OBBs are a pragmatic, species-agnostic proxy; they do not capture articulated pose and can be less accurate for highly non-box-like morphologies.
- Ethical, regulatory, and wildlife-disturbance considerations govern operational deployment of drones and automation levels.
Glossary
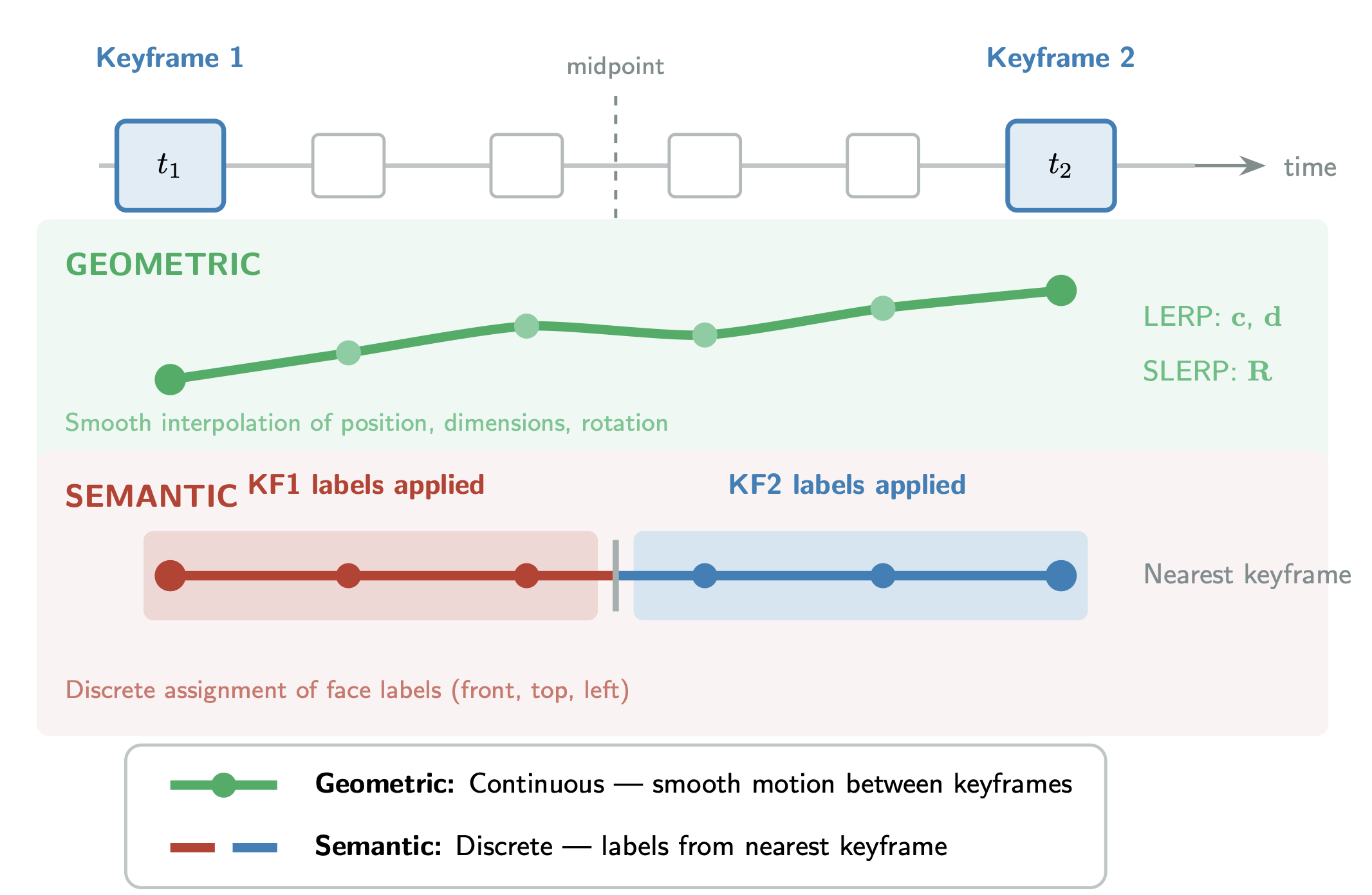
- 6-DOF (six degrees of freedom): The full 3D pose parameters of an object (3 translations, 3 rotations) that can be adjusted during annotation. "geometric correction (6-DOF adjustment, keyframe-based interpolation via LERP/SLERP, ground snapping)"
- Animal3D: A benchmark/dataset for articulated 3D animal modeling and evaluation. "articulated shape models such as SMAL~\cite{zuffi_3d_2017} and recent benchmarks like Animal3D~\cite{xu_animal3d_2023}"
- Bilateral re-identification: Identification workflows that require views from both left and right sides of an animal. "For bilateral re-identification workflows that require complementary left-flank and right-flank images of the same individual"
- Camera intrinsics: Internal calibration parameters of a camera (e.g., focal length, principal point) required for metric reconstruction. "from uncalibrated video without requiring camera intrinsics"
- Constant-velocity model: A tracking motion model that assumes the object's velocity remains constant between frames. "A Kalman-filtered tracker with a constant-velocity model associates 3D point clusters across frames"
- Domain adaptation: Techniques or adjustments to make models perform well when deployed in a different data domain than they were trained on. "necessitates species-specific motion model tuning---a form of implicit domain adaptation"
- Domain shift: A mismatch between training and deployment data distributions that degrades model performance. "Monocular depth networks trained on ground-level data suffer from domain shift when applied to oblique aerial viewpoints"
- Dormant track: A temporarily inactive track that continues to predict positions through occlusions and can be reactivated upon re-detection. "A two-tier active/dormant track management scheme handles occlusion: dormant tracks continue to propagate Kalman predictions and can be reactivated upon re-identification"
- Effective visibility score: A scalar measure combining geometric visibility with occlusion effects to assess how well a face/view is seen. "yielding an effective visibility score that combines self-visibility with occlusion"
- Feed-forward transformer: A transformer-based model that produces outputs in a direct pass without iterative optimization, used here for 3D reconstruction. "CUT3R~\cite{cut3r}, an online feed-forward transformer, recovers dense per-frame pointmaps"
- Foreshortening: The visual compression of dimensions when an object is viewed at a shallow angle relative to the camera. "quality scoring (viewing angle, projected area, centrality, foreshortening)"
- Foundation models: Large-scale pre-trained models that generalize across tasks and domains with minimal or no fine-tuning. "foundation models trained on web-scale data have enabled zero-shot generalisation for vision tasks"
- Gimbal telemetry: Orientation and motion data from the camera gimbal used to stabilize or constrain reconstruction. "PCA-based fitting with optional gimbal telemetry constraint"
- Ground snapping: Constraining or snapping predicted object geometry to the ground plane during annotation/refinement. "geometric correction (6-DOF adjustment, keyframe-based interpolation via LERP/SLERP, ground snapping)"
- Hungarian algorithm: A combinatorial optimization algorithm that solves the assignment problem in polynomial time, used for data association in tracking. "solved via the Hungarian algorithm"
- IDF1 (Identity F1 score): A tracking metric combining precision and recall of correctly matched identities across frames. "WildLIFT-RT achieved perfect recall (1.000) while attaining the highest identity consistency (IDF~=~0.982)"
- Inter-animal occlusion: Visual obstruction where one animal blocks another from the camera’s view. "Ray--OBB intersection tests quantify inter-animal occlusion"
- Kalman filter: A recursive state estimator used to predict and update object states (e.g., position/velocity) over time. "The Kalman filter continues to propagate its predicted position in 3D"
- KITTI format: A standard annotation format originating from the KITTI dataset, widely used for 3D object detection labels. "WildLIFT-A generates KITTI-format 3D oriented bounding boxes (OBBs)"
- LERP (linear interpolation): A straight-line interpolation method between two values, used for positions and dimensions across keyframes. "keyframe-based interpolation—LERP for position and dimensions, SLERP for orientation"
- LiDAR point clouds: 3D point measurements acquired by laser scanning sensors, often used as ground-truth geometry. "manual 3D bounding box annotation on LiDAR point clouds typically requires 60--120~seconds per box"
- Mask lifting: Projecting 2D segmentation masks into 3D by selecting reconstructed points whose projections fall inside the mask. "Mask lifting () projects detections into 3D"
- Mesh templates: Predefined 3D meshes specific to a species or class used by parametric shape models. "unlike parametric shape models that require taxon-specific mesh templates"
- Monocular 2D-to-3D lifting: Inferring 3D structure from single-camera 2D image sequences. "represents a natural extension of monocular 2D-to-3D lifting"
- Multi-view geometry: Geometric principles that exploit multiple viewpoints to reconstruct 3D structure. "the three-dimensional scene structure recoverable from the multi-view geometry inherent in drone video"
- Nearest-neighbour association: A simple tracking association strategy that pairs detections to tracks based on nearest distance in feature space. "3D ablation baseline using nearest-neighbour association without Kalman filtering"
- Non-maximum suppression (NMS): A selection procedure that keeps the most confident candidates and suppresses nearby, lower-scoring ones; here applied over time. "identify exemplar frames via temporal non-maximum suppression"
- Open-vocabulary segmentation: Instance segmentation conditioned on natural language queries that generalizes to unseen categories. "Open-vocabulary segmentation methods such as Grounded-SAM~\cite{ren_grounded_2024} provide instance-level detection from natural language queries"
- Oriented bounding box (OBB): A rotated 3D box aligned with an object’s orientation rather than the world axes. "Oriented bounding boxes are fitted to each instance-level 3D point cluster via PCA"
- Parametric shape models: Deformable 3D models controlled by parameters (e.g., limb angles) to represent articulated shapes. "unlike parametric shape models that require taxon-specific mesh templates"
- PCA eigenvector sign ambiguity: The inherent ambiguity in the direction (sign) of PCA axes, which can flip estimated headings by 180 degrees. "Semantic heading flips (PCA eigenvector sign ambiguity inverting the heading by 180\textdegree) occurred in 10\% of frames"
- Pointmap: A dense set of 3D points reconstructed per frame that represents scene geometry. "CUT3R~\cite{cut3r}, an online feed-forward transformer, recovers dense per-frame pointmaps"
- Ray–OBB intersection: A geometric test to determine whether a viewing ray intersects an oriented bounding box, used to quantify occlusion. "Ray--OBB intersection tests quantify inter-animal occlusion"
- SE(3) (Special Euclidean group): The mathematical group of 3D rotations and translations used to represent camera or object poses. "camera poses "
- Shannon entropy-based diversity indices: Measures derived from Shannon entropy to quantify diversity (e.g., distribution of viewpoints). "Coverage vectors, Shannon entropy-based diversity indices (Equation~\ref{eq:entropy}), and letter grades (A/B/C/F) provide aggregate metadata"
- SLERP (spherical linear interpolation): Interpolation on the unit sphere for smooth rotation transitions, typically using quaternions. "SLERP~\cite{shoemakeAnimatingRotationQuaternion1985} for orientation"
- Species-agnostic: Methods that do not depend on any particular species and can generalize across taxa. "enable species-agnostic 3D detection and tracking"
- Track fragmentation: The undesired splitting of a single object’s trajectory into multiple track IDs. "Track fragmentation---which distributes an individual's activity budget across pseudo-individuals and dilutes behavioural signals---was reduced"
- Tracklet: A short, contiguous segment of a tracked trajectory used for annotation and analysis. "The pie chart summarises the coverage distribution across faces for a single tracklet"
- Zero-shot generalisation: The ability of a model to perform on unseen categories without category-specific training data. "foundation models trained on web-scale data have enabled zero-shot generalisation for vision tasks"
Collections
Sign up for free to add this paper to one or more collections.

