- The paper introduces a framework that expands behavioral repertoire in hierarchical reinforcement learning via linear combinations of reward functions.
- The methodology employs a high-level controller to specify reward coefficients, significantly improving exploratory performance in the NetHack environment.
- Experimental results demonstrate enhanced waypoint visitation and robust strategies over long horizons, challenging standard HRL temporal abstraction concepts.
Hierarchical Behaviour Spaces: Expanding Expressivity in RL via Linear Reward Combinations
Introduction
The paper "Hierarchical Behaviour Spaces" (2604.24558) proposes a framework for hierarchical reinforcement learning (HRL) that leverages linear combinations of reward functions to induce a rich space of agent behaviors. The approach, termed Hierarchical Behaviour Spaces (HBS), builds on recent advancements in scalable option learning (SOL) but transcends the constraint of discrete option selection by allowing the high-level controller to specify coefficients over reward function axes, thereby orchestrating temporally extended behaviors. The empirical evaluation focuses on the NetHack Learning Environment (NLE), a benchmark characterized by extreme horizon lengths and hard exploration, demonstrating state-of-the-art waypoint visitation rates on early game milestones.
Hierarchical Behaviour Spaces: Motivation and Methodology
The motivation for HBS arises from inherent limitations in traditional option-based HRL: with a fixed set of options, the expressive power of the induced semi-MDP is bounded by the option policies’ granularity. Theoretical analysis from [Fruit & Lazaric, 2017] establishes that regret in the base MDP can be decomposed into the SMDP regret term and a value gap due to option expressivity. This highlights the benefit of expanding the behavioral repertoire via compositional structures.
HBS consists of a two-level hierarchy:
- High-level Controller πΩ: Specifies a vector ρ∈[0,1]n as coefficients over n reward functions.
- Low-level Intra-option Policy πω: Conditions on ρ and executes primitive actions to maximize the weighted reward sum ρT(R1,...,Rn) over a fixed temporal span.
This formulation generalizes SOL, enabling the controller to dynamically interpolate between reward axes, thereby inducing behaviors unattainable via pure option selection.
(Figure 1)
Figure 1: The controller selects points in the reward function simplex, inflating the space of achievable behaviors via linear combination.
Discrete bins for ρ are used for effective policy specification, reflecting practical findings that quantized action spaces facilitate learning stability. Reward function normalization is omitted to enhance behavioral diversity.
Experimental Results on NetHack Learning Environment
HBS is evaluated in the NLE with a 5-axis reward space: scout (map exploration), −Δ(dlvl) (dungeon level backtracking), −Δ(AC) (armor improvement), +Δ(Food) (nutrition), and ρ∈[0,1]n0 (combat experience). Unlike previous benchmarks dominated by flawed in-game score metrics, the focus is on exploration-driven rewards and milestone visitation.
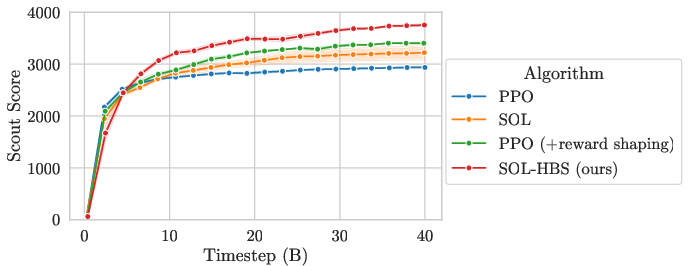
Figure 2: HBS demonstrates superior performance on NLE, converging to higher returns after 40B timesteps compared to SOL and PPO variants.
HBS outperforms PPO and SOL baselines—contradicting prevalent notions regarding the sample efficiency benefits of hierarchy, as HBS only achieves dominance after substantial training horizons.
Further qualitative assessment is realized through early milestone visitation rates.
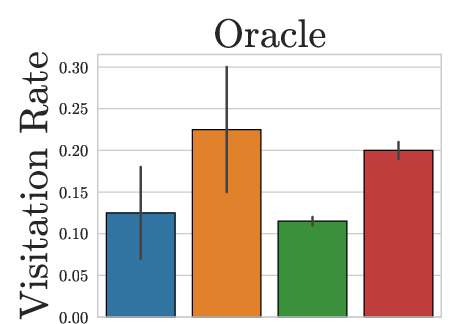
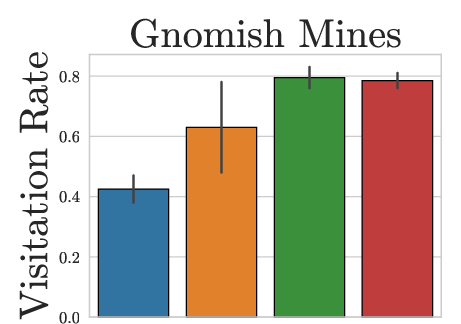
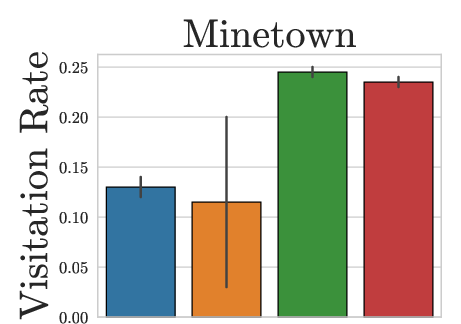
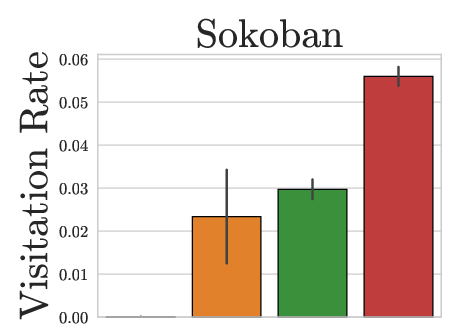

Figure 3: HBS achieves high visitation rates across both dungeon branches, unlike PPO or SOL which exhibit branch favoritism or insufficient traversal.
HBS uniquely succeeds in consistently reaching critical game waypoints (Gnomish Mines, Oracle, Sokoban) across seeds, indicating robust strategies capable of flexible backtracking and branch exploration.
Analysis of Discount Factors and Temporal Reasoning
Typical HRL arguments posit that hierarchical decomposition facilitates long-term credit assignment. However, empirical ablation reveals that HBS performance is largely unaffected by the controller discount factor ρ∈[0,1]n1, diverging from PPO which exhibits performance collapse at high ρ∈[0,1]n2 due to variance.
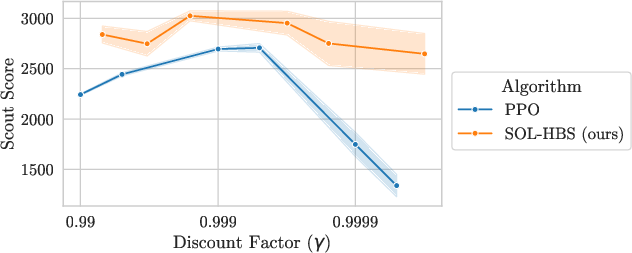
Figure 4: HBS maintains performance over a wide range of controller discount factors, while PPO collapses under high ρ∈[0,1]n3.
The best HBS performance aligns with moderate ρ∈[0,1]n4, refuting the hypothesis that hierarchy's primary advantage lies in extended temporal reasoning for this domain. The implication is that HBS’s gains are attributable to expanded exploration dynamics via behavioral diversity, not horizon compression.
Intrinsic Rewards: Automated Coefficient Tuning via HBS
By interpreting HBS as an automated intrinsic reward tuning mechanism, the method can be understood as continuously searching for optimal reward weights to maximize exploratory and task-driven behaviors. Adding reward axes increases HBS performance, contrary to SOL, which suffers degradation as the option space expands due to combinatorial complexity.
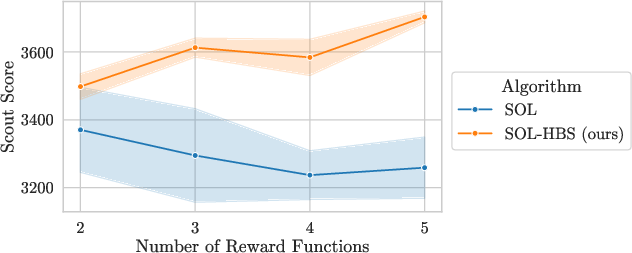
Figure 5: HBS exploits growing reward axes to improve performance; SOL's performance declines with option set enlargement.
This dynamic intrinsic reward management obviates the need for manual intrinsic reward coefficient sweeps, offering a scalable solution to incorporating diverse behavioral incentives.
Implications and Future Directions
Practically, HBS’s architecture enables RL agents to scale to hard-exploration, long-horizon domains, efficiently utilizing large parallel throughput setups. Theoretically, HBS challenges standard HRL wisdom by evidencing that hierarchy’s principal utility need not be temporal abstraction per se, but instead lies in facilitating structured exploration through behavioral compositionality.
Future research could investigate:
- Integration of learned or synthesized reward functions to further orthogonalize behavioral axes.
- Application to other unsolved RL benchmarks characterized by long horizons or sparse reward signals.
- Combining HBS with meta-learning strategies to adaptively generate reward axes online.
Conclusion
Hierarchical Behaviour Spaces (2604.24558) present a scalable HRL algorithm wherein controllers induce a simplex of behaviors via linear reward combinations, fostering increased expressivity and exploration. Empirical validation on NLE establishes state-of-the-art waypoint visitation rates. The findings prompt reconsideration of hierarchy’s role in RL, suggesting enhanced exploration—rather than horizon compression—is the critical benefit. HBS constitutes a pragmatic tool for RL practitioners confronting hard-exploration environments and sets a precedent for reward compositionality in future AI systems.

