- The paper presents a divergence-based model weighting approach that balances in-sample fit with out-of-sample predictive accuracy.
- It employs optimism-penalizing priors and convex optimization to generate stable, theoretically optimal weights compared to stacking and negative exponentiation methods.
- Empirical results demonstrate superior RMSE and log scores on various datasets, with PAC-Bayesian analysis and asymptotic consistency supporting its effectiveness.
Divergence-Based Model Weighting for Model Prediction Averaging
Introduction
The paper "A Divergence-Based Method for Weighting and Averaging Model Predictions" (2604.24172) proposes a principled framework for combining predictions from multiple statistical and machine learning models, applicable to both frequentist and Bayesian paradigms. The central premise is to employ a divergence-based optimization, motivated by minimum divergence principles, to compute model weights that balance predictive accuracy and optimism penalty. The objective is to improve prediction by leveraging model ensembles, providing advantages especially for small sample regimes where classical methods such as stacking and negative exponentiated weighting (including AIC-based and Bayesian model averaging) exhibit limitations. The paper introduces theoretical justification, empirical evidence, robustness checks, and practical implementation guidance.
Background: Existing Model Weighting and Averaging Methods
Two major paradigms dominate existing model weighting:
- Negative exponentiated model weighting: Transforms predictive scores into weights using negative exponentiation—commonly seen in Bayesian model averaging and AIC weighting, but suffers from excessive concentration on a single model as the sample size increases.
- Model stacking: Directly optimizes the linear combination of model predictions, typically via cross-validation. Stacking achieves strong asymptotic optimality but is unstable or suboptimal in small sample regimes, even with regularization.
Both paradigms inherently trade-off in-sample fit, predictive generalization, and computational stability. The divergence-based method proposed aims to bridge the strengths of both, mitigate their weaknesses, and provide a theoretically grounded alternative.
Methodology: Divergence-Based Model Weighting
For models M1,…,MK fit to data y1,...,yn, the method proceeds as follows:
- Optimism estimation: Quantify model optimism by opk=−i∑logpkp(y~i)+i∑logpkp(yi), representing the difference between in-sample and out-of-sample log scores (future sample prediction is estimated via cross-validation, bootstrap, or information criteria).
- Optimism-penalizing prior weights: Define prior model weights as wkop=∑i=1Ke−opie−opk, penalizing models whose in-sample accuracy is overly optimistic.
- Convex optimization: Solve
wp∈SKmink∑wkplogwkopwkp−i∑logk∑wkppkp(yi)
which trades off KL divergence from the prior (optimism correction) against log-score-based predictive accuracy on the observed data.
The optimization is convex and solvable efficiently with standard solvers. The framework accommodates any estimation method and is agnostic to the underlying fitting paradigm.
Theoretical Justifications
The method is justified from three complementary viewpoints:
- Empirical surrogate of ideal predictive objective: The optimal blend would minimize expected log-loss on future data, but since ground truth is unknown, the procedure discounts in-sample bias via optimism-penalizing weights and penalizes divergence from the prior, resulting in provably unique optimal weights (Theorem 3.1).
- PAC-Bayesian analysis: The optimization aligns with PAC-Bayesian bounds, with adjustments to account for mixture predictors (log inside the mixture) and empirical versus out-of-sample evaluation. Sub-Gaussian tail assumptions yield tractable bounds, and the method is robust to overfitting in small-sample settings (Theorems 3.2, 3.3).
- Asymptotic consistency: Divergence-based model weighting converges to the ideal predictive objective as sample size grows, ensuring consistency and avoiding systematic overfit (Theorem 3.5).
Boundary conditions uniquely determine KL divergence as the correct f-divergence and c=1 as the regularization constant. Deviations from these (e.g., Brier divergence or flat prior) are shown to degrade performance empirically.
Empirical Results
Linear Regression Simulation
Extensive simulations on diverse linear regression settings (varying sparsity and correlation structure) compare divergence-based weighting, negative exponentiated weighting, and stacking. Results demonstrate:
- Superior RMSE for divergence-based weighting in small samples.
- Asymptotic parity between divergence-based weighting and stacking in large samples.
- Negative exponentiated weighting underperforms, especially as sample size increases.
- Divergence-based weighting yields more stable weight estimates across runs.
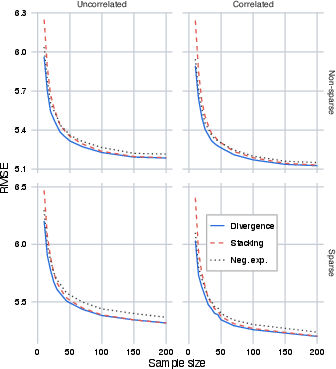
Figure 1: RMSE of model-weighting methods with various data-generating distributions; divergence-based weighting outperforms for small n.
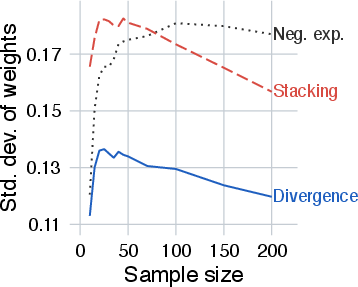
Figure 2: Standard deviation of model weights across 1000 simulation runs for varying sample sizes; divergence-based weighting exhibits greater stability.
Machine Learning Dataset Experiments
Twelve data sets from the UC Irvine repository are used, encompassing a range of n and p, comparing divergence-based weighting, stacking (multiple meta-learners), negative exponentiated weighting, and non-linear stacking variants. Findings:
- Divergence-based weighting achieves the best log score on 9/12 datasets and the best mean log score overall.
- Negative exponentiated weighting excels only for very small datasets, but divergence-based weighting consistently outperforms all linear and non-linear stacking variants in the small-sample regime.
- The method's linearity in model predictions provides interpretability and optimality, but for select data, non-linear combinations occasionally surpass linear methods.
Bayesian Model Averaging Context
Simulations in Bayesian subset regression settings replicate and extend prior benchmarks (cf. [Yuling2018]), showing:
- Divergence-based weighting dominates pseudo-BMA+ and stacking for small samples.
- Asymptotic behavior matches stacking, indicating the method's linear optimality.
Robustness Checks
Experiments varying penalty divergence (Brier vs. KL), prior choice (uniform vs. optimism-penalizing), and regularization constant y1,...,yn0 validate the theoretical boundary condition: only KL divergence, optimism-penalizing prior, and y1,...,yn1 achieve consistent optimality. Heavy-tailed error distributions do not degrade the method's performance.
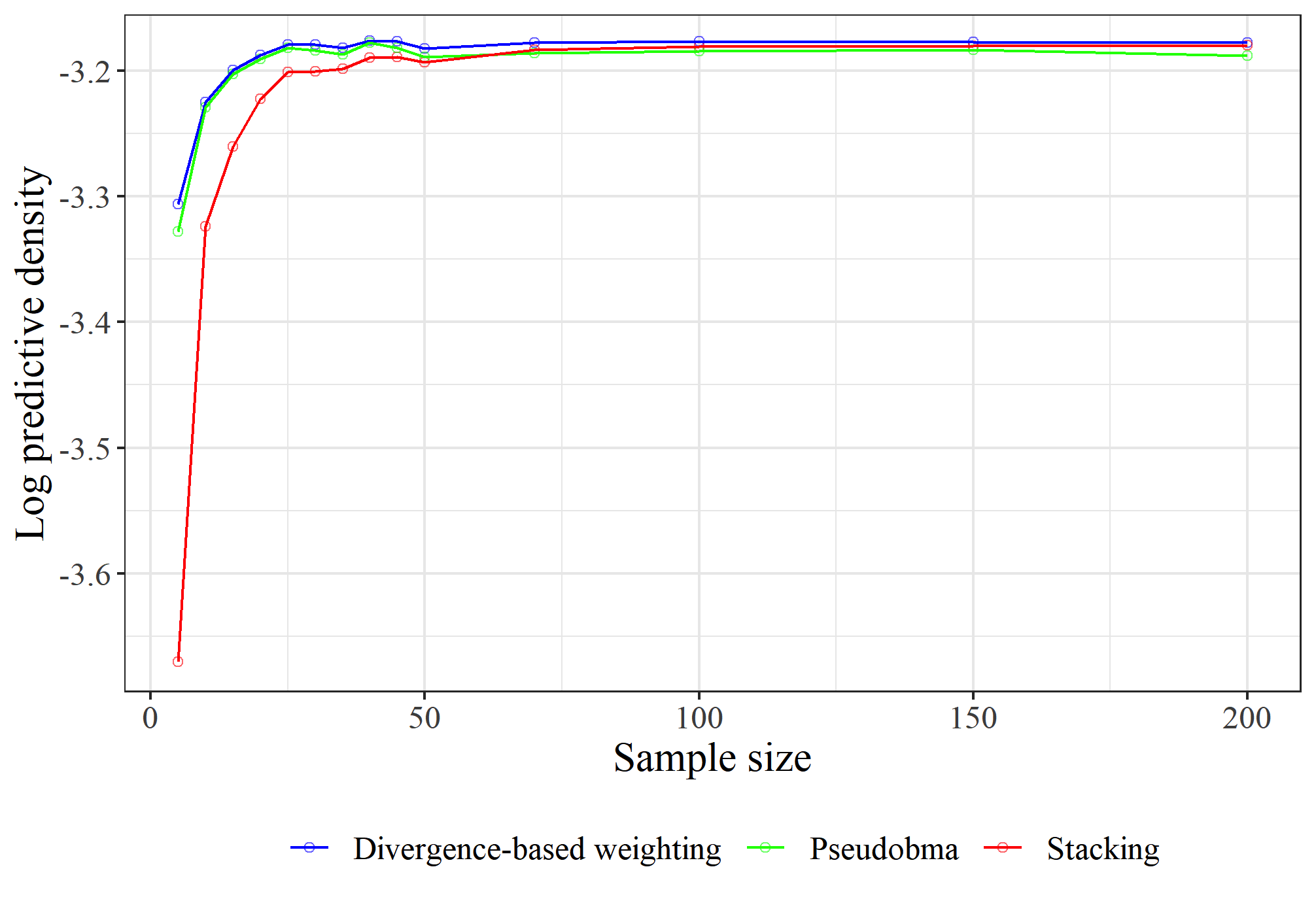
Figure 3: Each model consists of a single predictor in Bayesian regression simulation; divergence-based weighting dominates for small samples.
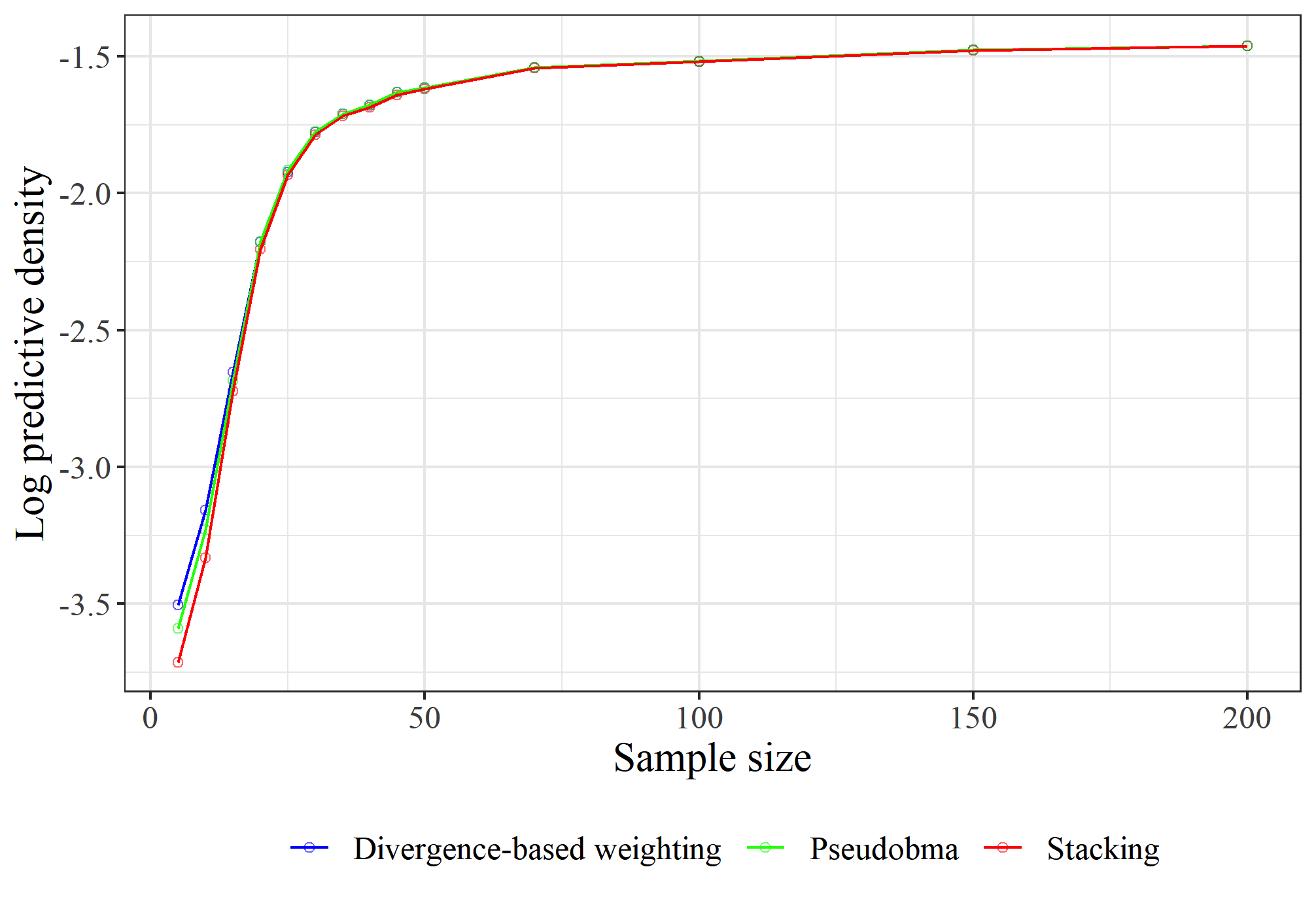
Figure 4: Models are increasingly larger subsets in Bayesian regression simulation; divergence-based weighting slightly superior for small y1,...,yn2.
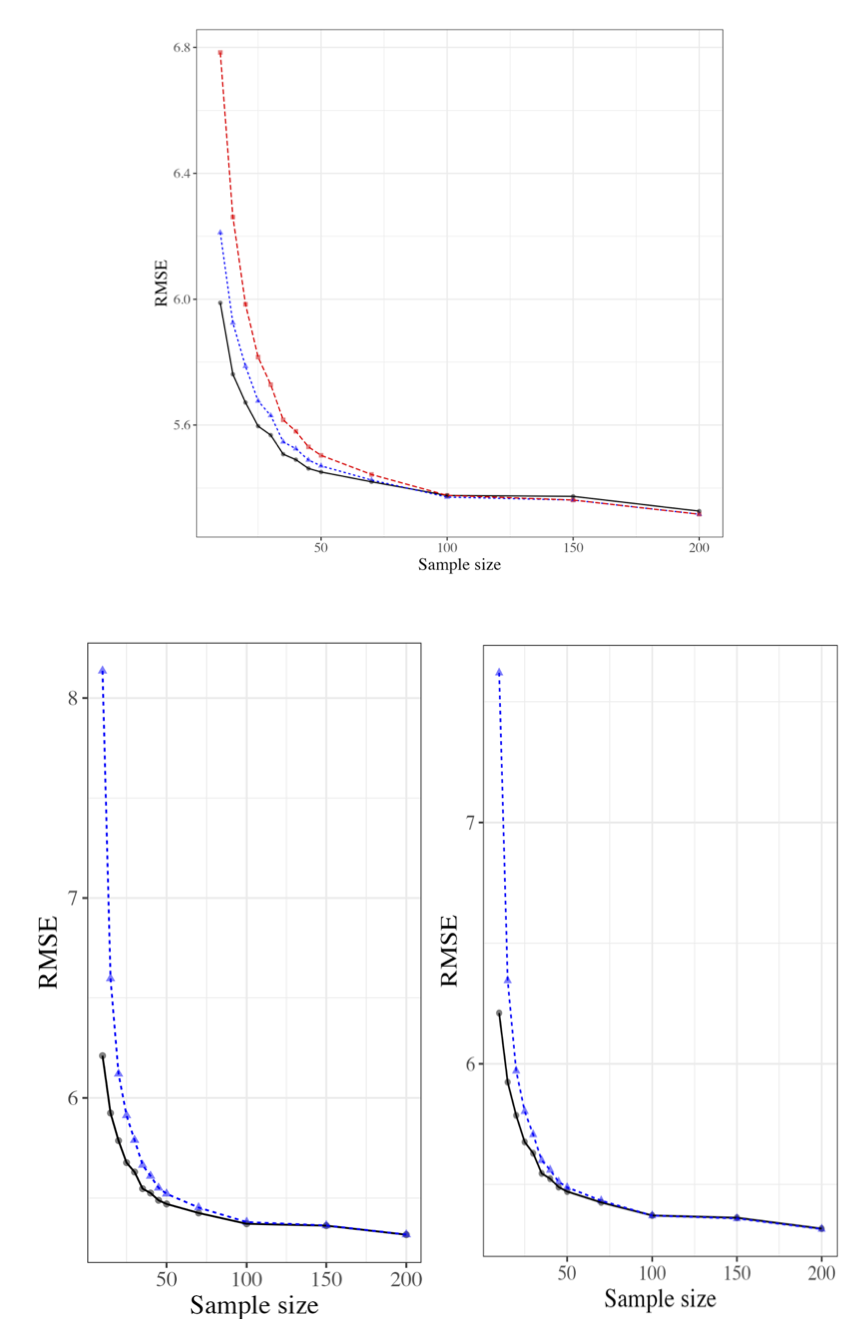
Figure 5: Robustness analysis; KL divergence (bottom left) and optimism-penalizing prior (bottom right) are essential for optimal performance.
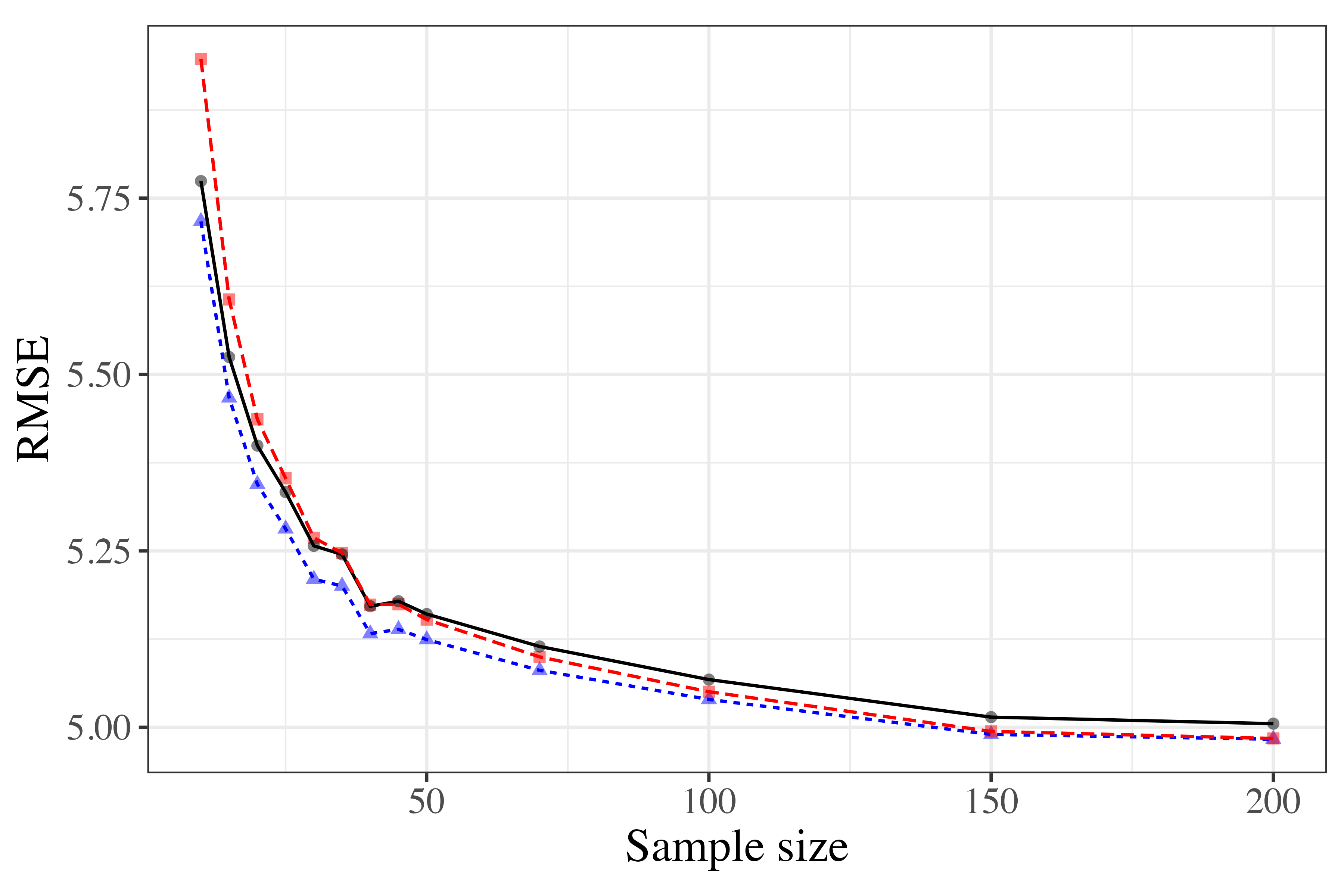
Figure 6: Performance for heavy-tailed generative models. Divergence-based weighting retains superiority against stacking and negative exponentiated weighting.
Practical Considerations and Extensions
The method admits practical implementation across modeling scenarios, accepting frequentist, Bayesian, or otherwise constructed model ensembles. Optimism estimation flexibility enables computational efficiency, with information criteria (AIC/WAIC) offering alternatives to cross-validation. Extension to input-dependent weighting are suggested, as well as exploration of alternative priors for improved performance.
Conclusion
Divergence-based model weighting establishes a robust and theoretically optimal mechanism for probabilistic model averaging. It outperforms prevalent alternatives, particularly in regimes characterized by small sample sizes or model overfitting, and remains competitive or superior as sample size scales. The method's dual principled justification—minimum divergence and PAC-Bayesian bounds—provides clarity in predictive ensemble construction, with practical empirical evidence across synthetic and real-world machine learning tasks. Future directions include input-dependent weighting and exploration of non-trivial priors for enhanced predictive flexibility.